


Hi,
The 2019 ICPC Mexico Finals starts in 30 minutes.
Let's discuss the problems after the contest.
There are some mirror contests starting 1h after the real one:
- https://www.juezguapa.com/concursos/icpc-latin-america-2019-final-official-mirror
- https://matcomgrader.com/contest/overview/6254
- https://www.urionlinejudge.com.br/judge/en/contests/view/496
This facebook page is posting updates frequently: https://www.facebook.com/acmitesochapter
Streaming:
- From Universidad de Oriente de Santiago de Cuba (Spanish): https://www.facebook.com/icpc.caribbean.media/videos/433791383990095/
Good luck to all the teams.
UPDATE The contest has started.
UPDATE Live scoreboard: https://global.naquadah.com.br/boca/score/index.php (use this if the previous one doesn't work https://global.naquadah.com.br/boca/scoreglobal.php?h=AT2oE0HBeAg8eox30q5wZOdk8SY_bIZ-hGKuX9OTrY661HqiWgHRra4KBYyrxV6IDqZeTVr7yJ6EpBVje50BxzQBkGZoTKMNPwb3UZpD_G79M9PmveqUhUUrtO04BJUpMwqPvrz_7o-QWTc)
UPDATE Problems available:
- https://matcomgrader.com/media/contests/6254/A.pdf
- https://matcomgrader.com/media/contests/6254/B.pdf
- https://matcomgrader.com/media/contests/6254/C.pdf
- https://matcomgrader.com/media/contests/6254/D.pdf
- https://matcomgrader.com/media/contests/6254/E.pdf
- https://matcomgrader.com/media/contests/6254/F.pdf
- https://matcomgrader.com/media/contests/6254/G.pdf
- https://matcomgrader.com/media/contests/6254/H.pdf
- https://matcomgrader.com/media/contests/6254/I.pdf
- https://matcomgrader.com/media/contests/6254/J.pdf
- https://matcomgrader.com/media/contests/6254/K.pdf
- https://matcomgrader.com/media/contests/6254/L.pdf
- https://matcomgrader.com/media/contests/6254/M.pdf
UPDATE Official results are ready: http://scorelatam.naquadah.com.br/
Congrats to the winners!!!
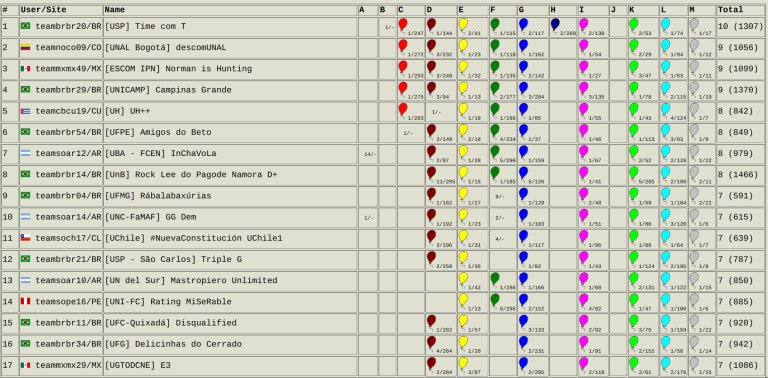
UPDATE These are the teams going to the world finals, there were 4 extra spots:
- UH++,CUBA
- Limitless, CUBA (new)
- Norman is Hunting, MEXICO
- E3, MEXICO
- #define TriLCI(404.0) :v, MEXICO
- pu+os, MEXICO (new)
- Guerreros de RodriGOD, COSTA RICA
- InChaVoLa, ARGENTINA
- GG Dem, ARGENTINA
- #NuevaConstitución UChile1, CHILE
- Rating MiSeRable, PERU (new)
- descomUNAL, COLOMBIA
- La bomba de tenedores, VENEZUELA
- Time com T, BRASIL
- Campinas Grande, BRASIL
- Amigos do Beto, BRASIL
- Rock Lee do Pagode Namora D+, BRASIL
- Rábalabaxúrias, BRASIL
- Triple G, BRASIL (New)
UPDATE MarcosK uploaded the contest and the official standings to the gym: 2019-2020 ACM-ICPC Latin American Regional Programming Contest







Auto comment: topic has been updated by k790alex (previous revision, new revision, compare).
Auto comment: topic has been updated by k790alex (previous revision, new revision, compare).
Auto comment: topic has been updated by k790alex (previous revision, new revision, compare).
Auto comment: topic has been updated by k790alex (previous revision, new revision, compare).
Auto comment: topic has been updated by k790alex (previous revision, new revision, compare).
Is there another way to solve K problem avoiding FFT?
Sure, naive multiplication does the job pretty well here. Expected complexity in this problem is $$$O(n^2)$$$.
We tried FFT with divide and conquer but the precision error is too big to handle up to 2^63 -1. In the end 10^4 for 0.1 seconds troll us :P
Because of the 2^63-1 constraint, the real limit is actually $$$n \le 16$$$. So you can do multiplication as slowly as you want...
:O i am dumb
That's true O_O!
I actually didn't notice that so I coded it with divide and conquer NTT and then used BigInt to reconstruct the answer, which took like 90 minutes to implement, I think it has to do with the fact that I was learning NTT last week, so I had the topic fresh and didn't try to come up with an alternative approach. Funny enough, when I saw 2^63 I thought why not 10^18 that way it fits without having to use BigInt hehe
Well at least I can say that I learnt it good since I managed to get it AC :)
https://codeforces.me/gym/102428/submission/65614985
We are not allowed to see others' submissions. Could you share it in another way?
Can someone please tell me why this solution for I is wrong? https://ideone.com/61vnoj
If a client i is sent an email k*(1e9 + 7) times, dp[i] is zero, but that client still needs to be counted towards the "number of emails after the improvements".
You should count separately the number of messages before the optimization and after the optimization because of the mod. Test case that breaks this solution was added one day before the competition.
How to solve G and F ?
Problem G could be easily solved with Suffix Automaton, you could build a Suffix Automaton of S in $$$O(n*log(n))$$$ and then for each query start at the root of the automaton and do the following:
If there is a transition from the current node with the current letter of the query, move through it.
Otherwise, if you are not on the root, go to the root and add $$$1$$$ to the answer, if you are on the root, then the answer is $$$-1$$$.
For Problem F, you have to solve the problem recursively. Consider you'll be putting floors from bottom to top, if you have $$$s$$$ remaining blocks and the last floor you put had $$$n$$$ blocks then the number of ways to put the rest is:
This is, if the next floor doesn't start in the first block of the last floor, then there are $$$dp(s, n-1)$$$ ways to put the rest, otherwise, you can pick any valid size for the next floor and you know where it will be.
This is $$$O(n^3)$$$ if implemented naively, but it can be optimized to run in $$$O(n^2)$$$ by pre-calculating some sums.
About problem F, I'm not sure if I'm understanding correctly. Shouldn't the $$$dp(s,n)$$$ recurrence be:
Because $$$x$$$ basically means how wide you want the current floor to be, therefore you have $$$n-x+1$$$ positions to place a floor of width $$$x$$$ on top of a previous floor of width $$$n$$$ without going beyond its margins.
About precomputing some sums to reduce the complexity to $$$O(n^2)$$$, can you explain that part more in detail?
both are correct, for CrazyDiamond's formula you can think of:
the next floor will (A) start in the leftmost position of the previous floor or (B) it won't start there.
for (A) you have to choose where it ends: $$$ \sum_{x=1}^{min(s,n)}dp(s-x,x) $$$, and for (B) you can reduce it to the same problem but forgetting about the first position of the previous floor: $$$dp(s, n-1)$$$
This formula is a bit nicer because it needs an easier precomputation, although your formula can also be optimized to run in $$$O(n^2)$$$
If you keep thinking, with similar reasoning, you can get to martins formula (comment below) which is even nicer (very simple dp with no precomputation)
My recommendation to understand the optimization is to look at the memo matrix and what the sum we need to compute ($$$ \sum_{x=1}^{min(s,n)}dp(s-x,x) $$$) looks like in the matrix. You can build prefix sums over that matrix (in this case, over some diagonals of the matrix) such that you can compute $$$ \sum_{x=1}^{min(s,n)}dp(s-x,x) $$$ in $$$O(1)$$$
Another way to solve F is the following. First, you can ignore the first level of blocks. Let $$$DP(s,b)$$$ be the number of ways to put the remaining blocks. To calculate this you look at three cases:
The first level of blocks is full
The leftmost stack is empty
The rightmost stack is empty
You can calculate the first case by simply ignoring $$$s$$$ blocks. The second and third case are analogous, and you can calculate them by ignoring one stack. However, the cases eventually overlap, since the scenario where both the leftmost stack and the rightmost stack are empty can be reached from both cases. This can be solved by subtracting the value for the overlap. This is the formula:
$$$DP(s,b) = DP(s, b-s) + 2 \cdot DP(s-1, b) - DP(s-2, b)$$$
That's incredible hahaha literally blew my mind... During contest my team and I spent the last hour trying to solve this problem and now I feel stupid hahaha
This is awesome.
Is this $$$O(N)$$$ complexity?
This is amazing, dude. So clean and simple
For problem G another option is to use suffix array. Build a suffix array of the main string in $$$O(n \cdot log(n))$$$, and then for each query iterate over its characters and each time do 2 binary searches (a lower bound and upper bound) so that each time you keep narrowing the range of suffixes that still match with the query. To make it clearer, you start with the first character of the query, and with 2 binary searches you find the range of all suffixes having the first character as prefix, then you do 2 additional binary searches and find the range of all suffixes having the first 2 characters as prefix (inside the previous range) and so on. If the range becomes empty, increase your counter by 1 and start all over again from where you left off. In case you can't match even 1 character, then print -1.
Worst case time complexity of this is O([sigma of x from 1 to 2e5(xlogx)]*log2e5). Which in worst case will give tle. So this should not be used. Although it gave AC
In general I think it was good that problem-setter name was removed from each problem (I used to check the name of the problem-setter to try to guess complexity). Although, after reading problem C I feel bad the authors are not getting any recognition, very creative statement indeed.
Thanks for the problems. They were pretty brutal.
In case you are referring to the first two problems here is an outline of the solution:
Problem A: build the graph where every possible set is a node, and there is a directed between A and B if B contains exactly one element more than A. This is of course a DAG and we need to find maximal anti chain here. Applying Dilworth to this graph is enough to find the solution. Notice that number of edges in the transitive closure is at most $$$N \cdot 3^K$$$.
Problem B: Every point can be rotated 90 degree several times without affecting the answer. Do this until every point is in the first quadrant. Let's find where is the corner of the optimal square in the first quadrant. Binary search over the length of the diagonal (it is proportional to the perimeter) and try to find a rotation of the square such that it doesn't contain any point. Each point will give you a possible interval to rotate the square. Find if the intersection of all intervals is not empty. The time complexity was $$$O(\log(-PREC) \cdot \log n \cdot n)$$$.
There was also a beautiful solution for this problem with expected complexity $$$O(n)$$$, similar to the algorithm that find minimal enclosing circle. Random shuffle points at the beginning, and try to find a valid square for all prefix. Suppose you have a maximal square for first $$$x$$$ points, if point $$$x+1$$$ is outside this square, no action needs to be taken, otherwise, recompute the square, but letting this point belonging to one side of the square. This solution is a little bit trickier to implement, since a pair of point can define two possible maximal (not both maximum) squares.
$$$N \times 3^K$$$ is still a heck of a lot. As the problem stands, you're expecting contestants to submit an $$$O(E\sqrt{V})$$$ algorithm with $$$E \approx 6\times10^6$$$, which is a gamble I expect most people to not be willing to make (the scoreboard agrees with me). Did you ever consider decreasing limits for this problem?
Yes sure, but in practice the solution works extremely fast since the graph is not arbitrary. I stress my solution against tons of random (and not some random) distributions and it turns out that number of bfs required by Dinic was $$$O(log V)$$$ opposed to $$$O(\sqrt{V})$$$ (empirical result).
Moreover there was a very nice property that we didn't proved, it looks like transitive closure was not necessary to find minimum chain decomposition. Reference solution used transitive closure and run in less than a second.
I agree with you that it still sounds like this solution is a gamble, and maybe this problem doesn't fit quite well in this format of contest, but I still believe it is a nice problem. For the purpose of the problem we could decrease the limits, but it turned out hard to kill some greedies with small restriction, since we don't have so much control on the graph.
A complement to your empirical findings: https://link.springer.com/article/10.1007%2Fs00224-005-1254-y
Is it really a gamble though? Worst case analysis here seems too pessimistic and despite being a valuable tool is no silver bullet.
To reach N*2^K vertices and N*3^K edges there's no intersection between algorithms known by teachers so actually we have N independent graphs with 2^K vertices and 3^K edges each (in practice we are running N bipartite matchings on really small graphs, that translates into something close to 10^7 operations, given a proper hopcroft-karp implementation I'd be more concerned about the cost of constructing the graph than with calculating that).
On top of that these graphs are quite sparse and for those on average hopcroft-karp runs in near linear time.
This is an ICPC contest; your code has to pass all test cases so average case analysis is meaningless.
mnaeraxr made a valid argument that the worst case for these specific kinds of graphs is fast, and I have no reason to believe this is not true. But the only proof of this is empirical findings, which make it a gamble from a competition standpoint in which implementing flow and checking that it runs fast consumes precious time.
We agree with you ffao. We are very sad that this problem has not been solved.
We started working late this year and nobody really helped mnaeraxr until the last week. I have to admit that I misread the problem and understood that there were only 10 algorithms in total. I only realized that 3 days before the competition.
By the way, I think that most wrong-solutions were WA, not TLE.
In A there is no need to build edges between every pair of sets X and Y, where Y is a subset of X. You can build an edge only when (size of X = size of Y + 1), so there will be N*(2^K)*K/2 edges, for N=100 and K=10 it is about 5*10^5 edges.
We were aware of this, but... Do you know why it works?
well, it seems obvious that there will always be a path from X to Y if Y is a subset of X
That's not enough, you usually need to find the transitive closure of the graph to find minimum chain decomposition.
Take for example this directed graph:
The minimum chain decomposition is 2 (1,3,5; 2,4), but to find it you need to find the transitive closure. The underlying graph structure allows in this particular problem not to find the transitive closure. This tells that the optimal chain decomposition can be built using only edges between sets that differ in exactly one element. But I hadn't proof that yet.
You're right, I'm dumb.
I also submitted the solution without the transitive closure and it worked, is it weak testcases or is there proper reasoning why it would work?
mnaeraxr
vivace_jr We noticed before the competition that this strategy passed all testcases. I personally invested some time trying to break such solution, but unfortunately, didn't find any counter-example, also neither proved that it was legit.
So regarding your question about weak testcases: It depends if it is actually correct solution or not, which I don't know yet. My guess is that it is ok. At least testcases were not deliberately weak in that sense.
This wasn't a big deal since model solution used transitive closure.
There is a method to find maximum antichain (as well as minimum chain decomposition) without transitive closure.
In this problem, the partial order is the same as what danya090699 said and we construct a special network $$$G=(V,E)$$$. In this network, each edge has both minimum capacity and maximum capacity, meaning that in a feasible flow the real flow $$$f(u,v)$$$ of edge $$$(u,v,c,d)$$$ must satisfies: $$$c(u,v)\le f(u,v)\le d(u,v)$$$. Assuming we can solve this, we construct a network as follow:
Then a feasible flow corresponds to a chain decomposition of original partial order and the minimum one is the answer. Because each vertex $$$u$$$ in original partial order corresponds to $$$u\in V_0$$$ and $$$u'\in V_1$$$ and edge $$$(u,u',1,\inf)$$$ in network. So, the minimum capacity restricts that there must be a flow through this vertex.
To solve this kind of network, we just put another source $$$ss$$$ and sink $$$tt$$$. And turn each edge $$$(u,v,c,d)$$$ with minimum capacity into 3 edges:$$$(ss,v,c),(u,tt,c),(u,v,d-c)$$$ in normal network. (edges $$$(u,v,c)$$$ are described as there is a edge from $$$u$$$ to $$$v$$$ with capacity $$$c$$$) Since $$$s$$$ and $$$t$$$ don't satisfy flow conversation, we add a edge $$$(t,s,\inf)$$$. The meaning is that for edge $$$(u,v,c,d)$$$, there are $$$c$$$ units of flow into $$$v$$$ and $$$c$$$ units of flow out of $$$u$$$ compulsorily.
Then, we apply dinic on $$$(ss,tt)$$$ and check whether all edges from $$$ss$$$ are full. If yes, we have a feasible flow. If no, there is no feasible flow.
And finally, we need a minimum feasible flow. Apply dinic on $$$(t,s)$$$ to reduce the useless flow while satisfying those minimum capacities. (since all change of flow will not have an influence on those minimum capacities)
It works like this:
You can see this for more about this kind of network. (I know some Chinese reference about it but not in English, sorry)
In this way, time complicity is $$$O(maxflow(100*1024 \space vertices,3*5*10^5\space edges))$$$ (we triple the number of edges in construction, though a bit less than that)
I implemented this and got TLE (sigh) while a normal solution got AC in 904ms. (they are similar except construction of network)
Because dinic performs not so well in non-bipartite graphs. ($$$O(m\sqrt n)$$$ and $$$O(maxflow)$$$)
But even if i had got AC with this method, there are still too many vertices and edges to apply a network algorithm and it is still a gamble. And I was thinking about some greedy strategies or so to solve this problem instead of using network directly before checking editorial :P
can you share the chinese references?
"上下界网络流" is Chinese name for network with minimum capacity. You can search it and find lots of blogs in Chinese.
For example, link1, link2 and I like this best.
They talked about
find a feasible solution for a network with minimum capacity but without source and sink (capacity that flow in every vertex must equals to the capacity that flow out of it);
find a feasible solution for a network with minimum capacity and with source and sink;
maximum/minimum flow for a network with minimum capacity and with source and sink.
You can even solve cost flow version by the same way.
There is a problem about cost flow version.
There is few (but there is! link3) discussion about solving maximum antichain problem by network since it's not stable compared with computing transitive closure. For we can't even say whether it will give the answer in 1 second.
Btw, inspired by link3, I realized my implementation was so poor.
You can see that in my solution, we use dinic(ss,tt) to find a feasible solution but we can construct it directly (cover every vertex by a chain). So, we only apply the second dinic(t,s) to reduce the answer.
I got AC in 139ms.
wow, thank you!
mnaeraxr what is the extra logn for in the solution of B
Fix the length of the diagonal using binary search (this is $$$O(\log -PREC)$$$), then find for every given point the rotation intervals which are invalid. Now the problem is, given a set of intervals, find if there is a point no contained in any of the intervals. Sort them (this is $$$O(n \log n)$$$) and make a sweepline.
It is possible to avoid the sorting part by finding the complement of each interval and intersect them.
Auto comment: topic has been updated by k790alex (previous revision, new revision, compare).
Bonus: Can you solve problem D in $$$O(n \cdot log n)$$$.
This solution requires $$$O(n^2)$$$ number of restrictions. Try to use $$$O(n)$$$ restrictions instead.
Try to solve it first for the case where all brightness are different.
Order relationship is transitive. If brightness 1 is sorted before 2 and 2 is sorted before 3, then 1 is guaranteed to be sorted before 3.
Try to solve the problem for two brightness. (Points with repeated brightness are allowed this time).
You only care about points in the convex hull per brightness.
Polygon tangents.
I can only come up with an $$$O(n^2 \cdot log(n))$$$ solution which should be good enough in theory but I'm getting TLE due to the constant :(. The idea is to iterate over all possible directions counter clockwise ($$$O(n^2)$$$ directions) and for each direction we have all straight lines parallel to this direction and for each straight line we have all the points intersected by this straight line (we can compute all this in $$$O(n^2 \cdot log(n))$$$ by considering each pair of points $$$p_i$$$ and $$$p_j$$$ and computing the vector $$$p_j - p_i$$$ and a hash for the straight line defined by them and storing things in maps / unordered_maps). Then we initially rank points based on the first direction in $$$O(n \cdot log (n))$$$ (given a direction vector, we can rotate it 90 degrees ccw and then sort everything by projecting using dot product) and then in $$$O(n^2)$$$ we can count how many pairs of points are wrongly ranked. Then we iterate over all remaining directions, so when we transition from one direction to the next direction ccw the points that were collinear in the previous direction now are ranked in a strictly increasing order, so we sort those subranges and check quadratically the ranking conflicts in those subranges, and the points that become collinear in the current direction they no longer have ranking conflicts. If at some point the counter of ranking conflicts becomes 0, we print "Y", otherwise we print "N". I think this should work but I'm getting TLE. How can I improve it?
This is a very nice, but complex, solution. It is very hard indeed remove the $$$O(n^2 \log n)$$$ in the beginning of your approach.
The expected solution was: Every pair of points $$$p_i$$$, $$$p_j$$$ with different brightness $$$b_i < b_j$$$ defines a range of valid directions for this two points. Note that the range is 180 degrees wide. All directions $$$d$$$ such that the dot product between $$$d$$$ and $$$p_j - p_i$$$ is non negative is a valid direction for this two points. There is an answer if and only if the intersections of all such ranges is not empty. Finding the intersection of all this ranges can be done in $$$O(n^2)$$$ (no need to sort), but even sorting this intervals to find the intersection fit in time.
For every $$$i,j$$$ such that $$$b_i < b_j$$$ we take the range: $$$angle(p_j-p_i)$$$ $$$+-$$$ $$$pi/2$$$ right?
This is what I'm doing here then I do a sweep on the ranges, but I keep getting WA39, does anyone spot something wrong?
Edit: I found my mistake. It was simply the case when there is no $$$b_i < b_j$$$ so my code never enters the sweep loop and returns N instead of Y.
Auto comment: topic has been updated by k790alex (previous revision, new revision, compare).
How to solve C?
I don't know what was the intended solution. Mine uses a segment tree to keep track of biggest and smallest prefix sum. Then (in $$$O(log(n))$$$) we can find the first moment in which we need to "cut" our value if we start at position $$$X$$$ with value $$$Y$$$. Then, precompute "jumps" between cuts with a sparse table and you are done.
What is the intended solution for problem H?
This problem was planned as the most or second-most difficult of the set (with Problem J). There isn't any greedy approach.
First of all, let’s start thinking an easier problem. We want to calculate the expected amount of turns which a player needs to score 75.
It seems like a dp-problem. So, we are going to call dp[x][y] to the expected number of turns that we need to get 75 if we have already x points and our total turn has actually y points. For example, dp[75][0] is 0, because we don’t need any turn and dp[74][0] is going to value infinite because we cannot get 75 from 74.
For convenience, we count the turns after the “hold” or the “1-roll”, so dp[73][2] is 1 because after holding we get 75. We are going to calculate dp[x][0] in decreasing order of the x, so we assume that we already know all the dp[x1][0] for higher x1.
Let’s think dp[73][0]. We have to roll a 2 because any other number makes that we lose the turn. So:
dp[73][0] = ((1 + dp[73][0]) + dp[73][2] + dp[73][3] + dp[73][4] + dp[73][5] + dp[73][6]) / 6
As we said, dp[73][2] is 1 and in all others we have to lose the turn. So:
dp[73][0] = (5 * (1 + dp[73][0]) + 1 ) / 6
1/6 dp[73][0] = 1
dp[73][0] = 6
This example is easy, because basically we don’t need an strategy (we don’t need to choose between either hold or keep on rooling). In most cases, although that for any particular strategy we can calculate the probability of lose the turn without scoring any point (in the previous case was 5/6), we dont know which is the optimal strategy. So we can’t do a dp+Markov to solve the problem.
The solution is calculated numerically:
The key is the value dp[x][0]. If we know previously the value of dp[x][0], we can guess an strategy for every state dp[x][y] (descending by 'y') because we know the probability of winning if we hold, if we continue and roll a 1 and if we continue and roll any other number.
Formally, if dp[x][0] = k, and we know all the higher states (dp[x1][0] with x1 > x), we can iterate descending for all y (dp[x][y]) and see if we have to roll again or hold. In conclusion, if we get the real value of dp[x][0], we can know if this is the real answer.
So, we have 2 different numerical solutions:
We can make a binary search in the value of dp[x][0]. If after the iteration, rolling dp[x][0] we got a worse value means that the real value is, in fact, worse. Making a binary search, we solved the problem iterating for higuer-x to lower-x.
Also we can calculate dp[x][0] improving step by step. So, inicially dp[x][0] = INFINITE and for all the other states the strategy is Hold. Next, we can improve each state with the possibility of Continue several times until we don’t improve any of them. This method has a precision of 1e-9 after 200 steps.
Let’s return to the original problem. dp[x][y][z] means the probability of winning with the optimal strategy if you have x points, your opponent have y points and you have z points in this turn. In this case we are going to calculate dp[x][y][0] in decreasing order of x+y, so we assume that we know all the dp[x1][y1][0] for higher sum x1+y1.
We are going to use the ideas of the 'expected amount of turns' problem. The difference is that we have to guess at the same time the states dp[x][y][0] and dp[y][x][0]. This is a problem because we have to guess 2 numbers. I don’t know how to solve with the binary search idea (see next comment of ffao), but we can solve using the 2nd idea of improving step by step.
So, we have to calculate dp[x][y][z] and dp[y][x][z] for all the z at the same time.
For that, we create two arrays, lo[x][y][z] and hi[x][y][z] which are the low_bound and the high_bound of the solution. Inicially, lo[x][y][z] = 0 and hi[x][y][z] = 1.
After each step, we can optimize lo[x][y][z] with the formula: lo[x][y][z] = max(hold, roll); where hold is ''1-hi[y][x+z][0]'' and roll generally is ''(lo[x][y][z+2] + ... + lo[x][y][z+6] + (1-hi[y][x][0]) ) / 6'' Also, we can reduce the high_bound using this formula: hi[x][y][z] = max(hold, roll); but where hold and roll are similar to the previous ones but using the opposite arrays. At any step, lo[x][y][z] could only increase, hi[x][y][z] could only decrease, and lo[x][y][z] <= dp[x][y][z] <= hi[x][y][z] as invariant.
Finally we can use the values of the arrays to decide if you have to hold or continue.
I believe the first approach still works for the harder problem:
Let $$$A$$$ be dp[x][y][0] and $$$B$$$ be dp[y][x][0]. Suppose you magically learn the value $$$A$$$. From this, it is pretty easy to compute $$$B$$$, since the expected returns from holding or continuing at any point are known. Let the function that gets $$$B$$$ from $$$A$$$ be $$$f(A)$$$.
Similarly, you can compute $$$A$$$ from $$$B$$$. Let this function be $$$g(B)$$$.
What you want is to find $$$A$$$ such that $$$g(f(A))=A$$$. You can do this by binary search: if $$$g(f(A))>A$$$, you guessed too low; if $$$g(f(A))<A$$$ you guessed too high.
You could also write $$$f$$$ and $$$g$$$ explicitly to solve for the exact value of $$$A$$$, but this is probably not better than the numerical solution anyway.
Nice!
Yes, I didn't have time to see carefully, but I'm pretty sure the AC solution in contest used your idea and also I think that mjhun used the same idea to solve the problem. :)
By the way, for people who likes graphics, mnaeraxr maked this one with the optimal strategy (played to 101 instead of 75): https://giphy.com/gifs/U1h7WtR89xHpkFpD6b
As he said: "The animation shows the following: The image X shows the matrix if my oponent have X points already what is the probability I win with each action, Continue (1st graph) and Hold (2nd graph). The axis stands for (My current points vs The points in the counter). The third graph is binary showing whether the best strategy is Continue or Hold."
The AC solution in contest was the naive dp with an extra state for the amount of passed rounds. Turns out this converges quickly enough.
I know that you are from the same university and also I didn't read the code carefully :), but are you sure?
I read these lines of code that makes me fell that your solution used ffao's idea:
I'm not from the same university as them, I'm just saying what they told me after the contest. AFAIK, the CCL team "Chefes do Beto" tried to solve it using that binary search but the official team from USP solved it adding an extra state.
You are right, the AC solution was from SP not UFPE, my mistake.
But anyway, these lines comes from this solution.
We have this (very easy) solution link.
I am not sure if it's the same as the solution tfg suggests above, but it seems to converge very quickly. Does anybody have an idea why it converges so quickly instead of exploding, for example? And does it depend on the initial values?
(My guess to what happens here is that the implicit transition matrix $$$T(i, j, i', j')$$$ that updates $$$M(i, j, 0)$$$ at each step has some nice spectral properties, but I don't know enough linear algebra to prove).
Very interesting solution! :)
I don't know linear algebra also but...
How to solve problem J?
For a fixed position we can find the positions to the left and to the right that we may end up. That is, the ones that we will be trapped if we stop there looking to some direction (any direction).
The answer is the one with biggest height between the two possible positions, the update is simple.
Lets say that we started in position y and the best towers to the left/right are x and z respectively. Notice that after every jump we are looking in the direction of the start position, and also notice that we can only endup in x looking for z or in z looking for x.
This problem is really beautiful and shows that a problem can be hard and simple
Thanks! I did understand that... But how to update this?
I mean in order to find the trapped point for position x while looking at left / right at first, we need to use a stack to find the nearest left / right one which can not find the right / left higher point right? But how to do update operation? I have no idea about that...
It's kinda casebash
For an update in y, lets x and z be the first values bigger than y in left/right. Notice that possible answers can't have both x and z, since we need to be bigger by one side, so everyone in [x+1 , z-1] is not an possible answer anymore if we have both x and z. Now we have 3 cases, when we have an x but not an z , when we have an z but not a x, and when we are the bigger tower, for the first case, everyone in the right of y can't be trapped looking to the left, and everyone between [x+1 and y-1] are not an possible answer anymore, for the second case is analogous, for the third-case, the suffix can't be trapped to the left, and the prefix to the right.
Just use iterative segment tree and I'm sure it fits TL with a binary search. Or you can do it in O(log) with a bit more code on iterative or directly on recursive seg tree. This also removes the need to updates make the height greater.
If there were no updates, I think we can compute this for every position using DP + binary search + sparse table. Given a fixed position, we can binary search the first position to the right which is taller than the fixed position, and the same for the left (we use sparse table for maximum range query in the predicate of the binary search). Knowing this for every position, then it's easy to write a recursive function to find the final position we get trapped in if we start in every position and we can memoize this function (i.e. DP) to avoid recomputations. Unfortunately, this approach doesn't work due to the updates :(
Any ideas on how to handle the updates efficiently?
I don't understand this. What do you mean by "two possible positions"?
I don't understand this either. What do you mean by "best towers"? "Best" in what sense?
How to solve problem L?
I don't know if this is the official solution but here it goes:
You need to get a square sub-matrix where each row is either full with G or full with B. Now, you can create a new matrix $$$B$$$ with $$$N$$$ rows and $$$M-1$$$ columns, where $$$B_{i,j}$$$ is 0 if $$$A_{i,j} = A_{i,j+1}$$$ and $$$1$$$ otherwise.
Now, a square submatrix with side $$$L$$$ in $$$A$$$ will be a submatrix with $$$L$$$ rows and $$$L-1$$$ columns in $$$B$$$. You need to find the biggest $$$L$$$ such that there is a submatrix in $$$B$$$ with $$$L$$$ rows and $$$L-1$$$ columns full with zeros.
You can do this with some preffix sums and binary search. Or you can even ignore the binary search, keeping track of the biggest $$$L$$$ you have found so far.
An interesting and simple solution in $$$O(n*m)$$$, which is really similar to the algorithm used to find the biggest square of ones in a matrix of 0's and 1's:
$$$dp(i,j)$$$ = longest side of a valid square having lower-right corner in $$$(i,j)$$$
We have two cases:
$$$\underline{S_{i,j} == S_{i,j-1} \land S_{i-1,j} == S_{i-1,j-1}:}$$$ $$$dp(i,j)=max(dp(i-1,j),dp(i,j-1),dp(i-1,j-1))+1$$$
$$$\underline{Otherwise:}$$$ $$$dp(i,j)=1$$$
Note that the first condition is the only one necessary to extend by one the length of a valid square. Here is my code :)
how to approach B
Any more detailed idea of how to solve problem C? :c
I think my solution is the same as MarcosK
Let $$$h[i]$$$ be the prefix sum of $$$a[i]$$$.
Now write a segtree which can perform the following query: $$$query(l, r, x, y)$$$ returns the smallest index $$$i$$$ in the range $$$[l, r)$$$ such that $$$h[i]$$$ is outside of the range $$$[x, y]$$$. It also returns a type $$$t$$$ which is 0 if $$$h[i] < x$$$ and 1 if $$$h[i] > y$$$. This segtree can be used to find the first time the amount owned overflows (goes above U) or underflows (goes below L)
Next build a sparse table $$$f[t][i][j]$$$.
$$$f[0][i][j]$$$: assuming that, at time $$$i$$$ we owned $$$L$$$, this stores the $$$2^j\text{-th}$$$ smallest time $$$k$$$ such that there is an over/underflow on index $$$k$$$. It also stores a type, 0 if it was an underflow, and 1 if it was an overflow.
$$$f[1][i][j]$$$ stores the same thing, except we assume that at time $$$t$$$ we owned $$$U$$$.
We can initialize $$$f[0][i][0]$$$ and $$$f[1][i][0]$$$ using the segtree.
Then $$$f[0][i][j]$$$ and $$$f[1][i][j]$$$ can be computed as usual with a sparse table.
Now, for each query:
First, use the segtree to find the first location $$$i$$$ after the beginning day where we encounter an overflow/underflow.
Next, use the sparse table to find the last location $$$j$$$ before the end day where we encounter an overflow/underflow.
Finally, we know that between time $$$j$$$ and the end day, there are no underflows or overflows (Otherwise $$$j$$$ would have been larger). So we can just use $$$h[end]-h[j]$$$ to find how much the amount owned changed.
Yes, it's exactly the same idea. It was a nice problem
There's an alternative really nice solution that avoids a segtree entirely by doing the queries offline, and simulating all the queries at once.
We can sort the start/end times of the queries, and sweep from month 0 to the last month.
As we encounter start times, we maintain the values for all of these queries by storing the values in a sorted list (a set), with a global OFFSET variable. After each month we can increment all our query values with the OFFSET variable. This might cause some values to exceed the bounds, so we can use our set to check if any queries exceed U-OFFSET or L-OFFSET, and merge those elements into one element (with a DSU or similar thing) since every element can be merged at most once.
This way, we know the exact value for those queries when we encounter an end time.
Sorry, Can someone please tell me why this solution for I is wrong? 72862637
I submitted your solution using c++17 and it was AC. I presume the problem with c++11 is in the last line:
In this case you are populating
leafscontainer inside the functiondp, but maybe it is undefined the order in whichdp(1)andleafs.size()is evaluated, or simply it changed from c++11 to c++17.Fixing it for c++11 should be straight forward, split it in two statements: