


Tutorial is loading...
(Developing and idea — vintage_Vlad_Makeev)
Tutorial is loading...
(Developing and idea — MikeMirzayanov)
Tutorial is loading...
(Developing — cdkrot, idea — jury)
Tutorial is loading...
(Developing — Sehnsucht, idea — Helen Andreeva)
Tutorial is loading...
(Developing and idea — VFeafanov)
Tutorial is loading...
(Developing and idea — Sender)
Tutorial is loading...
(Developing and idea — voidmax)







Auto comment: topic has been translated by ch_egor (original revision, translated revision, compare)
Thx for fast judging and editorial!
Good problems, interesting solutions
Could D be solved using Topological Sorting?
Yes. I did it by Topological Sorting. My code is here 50382490
Actually I think Topological Sorting is just implementing the same method given by the editorial.
Hi! Could you please explain your code a little bit. I am interested in knowing what addEdge() function is doing and how is the while(head <= tail) loop working ? What is fe[] array for ?
I am sorry to reply so late.
For the first question, do you know what Adjacency List is? Function addedge() just adds an edge to the adjacent list of the graph, and fe[i] just denotes the index of the head of the list which contains all edges which start from vertex i.
For the second question, do you know what BFS is? In this step I am just implementing BFS algorithm to get the topological order of this graph.
C is very nice!
Please explain the proof of C.
There are already few comprehensive explanations, I don't think I can do it better.
Given editorial for c problem is grt..!!..but what I wanna say is I got AC in different way(sadly not during the live contest)...initially I sort the array...pick the largest element & put it into the dequeue.. then in the same fashion I traversed back from (n-2) to (0) and at one move I pick the element & put at the leftmost position in dequeue( O(1) operation..) and in other operation I pick element & put at the rightmost element in dequeue... Through this I approach I got AC...but I m also surprised with editorialist's solution bcoz it is O(n) where my solution is O(nlogn)...but it works well in the given constraints
Can somebody explain how to do the Concatenation of lists in
O(1)for problem F?Roll your own linked lists, and create a map from the DSU to the first and last pointer in the list. Then, to join two lists it's just a single pointer change.
You can use
std::listand thesplicefunction. For a reference, take a look at this submission: https://codeforces.me/contest/1131/submission/50373670How to solve problem F using dfs? Many of the people have solved it using DFS.
You may want to see my comment below.
Wait. On F, I don't understand why it's enough to simply unite the sets. We are trying to put the numbers on an ordered line, so when we unite a and b does it not matter if a is to the left of b or b is to the left of a? Can we prove that it doesn't matter? The editorial doesn't actually explain the problem, it explains how to do DSU.
Every time when we have to merge sets, all of kittens from one set are in one cell. If you have some order for set a and set b, you just have to ensure that this two sets are adjecent, because no matter you place them ab or ba, after i-th operation they will become one component.
Assume that putting a to the right of b is a valid solution
Then we split the sequence into four parts
c — b — a — d
Where c is the subsequence in front of b and d is subsequence behind a
It is fairly obvious that d’ — a — b — c’ is also a valid solution (d' and c' are the reversed sequence for c and d respectively)
So the order doesn’t matter
retired.old.cake can you please explain the time complexity part. I now that in DSU with union by size each query takes O(logn) time. And we will make (n-1) such queries. Also in each query we have to concatenate two list A, B in O(min(A, B)) time. How all of this combined give us O(nlogn) time?
We don't actually concatenate the two lists, in practice, you may use multiple linked lists. To merge two lists, you may simply point the end of one linked list to another. This is O(1)
What about the space complexity ?.....Each element has a list, will it not give MLE ?
Is there any way to solve F using DFS
I did that, but not sure if the way is what you want, since my DFS is used to travel a tree. My Submission is here, notice that array sz[] is not used and was forgotten to remove.
Simple explanation: when we merge 2 sets, we create a new node stands for the whole set and set its two sons to that 2 sets. After all operations it will become a tree because answer always exists. Use DFS to travel this tree, and every time when we meet a leaf node just print it. It's correct because for every merge operation the 2 operands are sons of a new node and that guarantees the 2 part must be neighbors in the final output.
Hope it helps.
i did that and i got a wrong answer can you check my solution? https://codeforces.me/contest/1131/submission/50388700
try this: ~~~~~ 5 1 2 2 3 2 4 3 5 ~~~~~
Each node would have only 2 edges , except the leaf nodes. Am i correct? And for that i just stored everything in the adjacency list and applied DFS on one of the leaf node.I am getting wrong answer.
I think starting from a leaf node will invalidate the correctness proof.
O_E
Did you find the faults in your approach I did the same and got WA in test case 8 like you. Can you tell me if you got it?
61853937
actually i learned dsu and came back to solve it , it's really easy using it but i didn't understand the dfs approach ,sorry
How to solve G? I think I need more details.
Let’s look on stack of increasing values of dp. Then we count the new value, we need to get the minimum element on the segment, that element should be in the stack, we can go from top and search for it. But this solution is O(m**2). Let’s notice that we can erase elements if we find reachable element earlier. So we can keep in stack only optimums. That gives us O(m).
Thank you!
didn't understand the solution of problem C, can anyone explain it to me or suggest other one ?
and what is the kind of topic he used to solve this problem ?
The solution is a constructive one. Sort the sequence, and append all even-indexed elements reversely to the end of the sequence. Correctness proof is given in the editorial.
I'll do my best to describe the proof in more detail:
We have a problem that requires us to find a configuration that minimizes a value. The general approach used (which can sometimes be applied to other problems too) is the following: We prove that that there's a lower bound on how small the answer can be for a given input and then we figure out a configuration that achieves that exact lower bound.
For this task: First, let's consider the numbers ordered such that a[i] ≤ a[i + 1]. We can then prove that the answer can't be better than ai + 2 - ai, for any i = 1,2,3,...,n-2. ( statement 1 )
If we manage to do that, then we can say that a lower bound for the answer is the maximum of all of those, i.e. max(ai + 2 - ai), where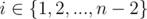 . The final step would be to see that the solution provided in the editorial gives that exact lower bound ( statement 2 ).
. The final step would be to see that the solution provided in the editorial gives that exact lower bound ( statement 2 ).
Proof for statement 1: First imagine that you have a complete graph, where the vertices are the given heights and the edges represent the absolute differences between the two endings. In order to give a solution, we must give for every vertex a "before" neighbour and an "after" neighbour, such that we get a cycle going through all nodes exactly once (a hamiltonian cycle). Now let's prove by contradiction that the solution can't be better than ai + 1 - ai for a fixed i. Suppose that it is smaller. Since we want the maximum value of an edge to be stricly less than ai + 1 - ai, then it means we can't use any edge between a[m] and a[n], where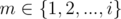 (let this be the first set) and
(let this be the first set) and 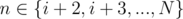 (let this be the second set), since a[n] - a[m] would be greater or equal to a[i + 2] - a[i]. From this, we can see that if we want to start a path from the first set that goes to the second set and then comes back, then we must use a[i + 1] at least twice. Thus, any cycle will contain a[i+1] more than once, so it can't be hamiltonian, so we can't build a correct configuration => contradiction with our initial hypothesis that there exists a solution.
(let this be the second set), since a[n] - a[m] would be greater or equal to a[i + 2] - a[i]. From this, we can see that if we want to start a path from the first set that goes to the second set and then comes back, then we must use a[i + 1] at least twice. Thus, any cycle will contain a[i+1] more than once, so it can't be hamiltonian, so we can't build a correct configuration => contradiction with our initial hypothesis that there exists a solution.
Therefore any solution can't be better than the mentioned lower bound.
Proof for statement 2: I'll just mention the logic for the example solution given in the editorial: a1, a3, a5|a6, a4, a2. We can see that the difference between two heights in the first part or in the second is one of the those that give the lower bound. The other two are the difference in the middle and the one at the end. But we have that a[6] - a[5] < a[6] - a[4] < lowerBound and a[2] - a[1] < a[3] - a[1] < lowerBound. So the maximum of all values is less or equal to the lower bound, but since the lower bound is the lowest value, it means we get exactly that.
Hope it helped.
Honestly, the proof of statement 1 seems pretty nontrivial, which is why I'm surprised the problem was a Div2 C.
I agree. The problem was probably a Div.2 C because of how easy it is to write the code for the solution given in the editorial. Maybe many people "eyeballed" the solution without proving it.
Can anybody please point out why my solution for F is exceeding time limit? Thanks in advance!
50385034
You haven't initialised sze with 1.
Thanks a lot for replying and solving my mistake as well.
However do you have an idea as to why all those 7 test cases worked (the 7th testcase had a very large input file as well)... and why particularly initialising the sze array with values as 0 was causing a tle?
Thanks a lot though!
Wait I got it, no need for replying , thanks a lot! It was a pretty silly mistake by me :(
G: Where is the case with dropping domino to the left? Also first formula shouldn't be dp[j]=min(dp[i-1]+c[i]) for all j, that j-th domino fall if i-th was pushed to the right?
I think the editorial has a typo. The first situation should be domino falls left.
I think so. It had confused me for some moment until I realized there is a typo.
I did Problem C using Binary Search, but my implementation was too complex 50403476. Anybody who also did it using Binary Search with an easier implementation?
DSU contest
How to solve problem G by dynamic? I need more explanation.
actually,I can't understand D's DSU solution.how to deal with '<'ans'>'?
if aij equal to "=" then dish i from the first day and dish j from the second day must be equally good, then you will realize that 2 dishes must be on the same group. When you assign all dishes to the group then you can look at '<' and '>'. So if aij equal to '<' then the group of dish i from the first day are worse than the group of dish j from the second day so that makes a graph of the group of dishes, Same as '>'. After that use DFS on that graph to find which group are the worst and which one is better and so on.
Here is my solution : link
PS. Sorry about my English.
The following is another alternative for implementing the proposed solution for problem 1131C - Birthday.
50431644
Assuming a 0-indexed array a0, a1, ..., an - 1, and an array-size parity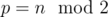 , your valid optimal solution can be formulated as follows:
, your valid optimal solution can be formulated as follows:
ap, ap + 2, ap + 4, ..., an - 2, an - 1, an - 3, an - 5, ..., a1 - p.
P.S. In the problem statement, I think that the word "low" should have been written as "short", and that the phrase "growth of two neighboring children" should have been written as "heights of two adjacent neighboring children".
Can someone explain E more thoroughly?
The following is another intuitive deque-based solution for problem 1131C - Birthday, pushing ordered heights at both ends of the deque in alternation until all heights are pushed to form the optimal circle with minimum height-difference between adjacent neighboring children.
50471341
P.S. This idea was developed independently. Other contestants might have used a deque as well to form the requested circle.
Div2 Problem B: Draw! In my local machine, I'm getting the correct output for the test case, while on cf output is different, Can anybody help me with this, Here is my code .
Try your original code on your local machine by entering the input values instead of copying the test case. It will output a garbage value. Solution: Replace
mp(0, 0)by construct assignmentpair<int, int>(0, 0). andmp(x, y)withpair<int, int>(x, y).In the second loop, i goes up to n,
then in this line,
y = min(arr[i+1].ff,arr[i+1].ss);You try to access the element at arr[n+1] which is some garbage value that you did not set.
Can anybody help me with the number assignment process in D?
Can you modify the answer fo G ? I think the editorial has a typo. The first situation should be domino falls left.
Thank you very much. I think it will be very helpful.
can anyone help me in question F. I used DFS. https://codeforces.me/contest/1131/submission/51000532
Try the following test case it gives a wrong sequence 10 10 6 8 10 6 2 8 7 8 4 1 7 8 5 3 10 10 9
Given editorial for c problem is grt..!!..but what I wanna say is I got AC in different way(sadly not during the live contest)...initially I sort the array...pick the largest element & put it into the dequeue.. then in the same fashion I traversed back from (n-2) to (0) and at one move I pick the element & put at the leftmost position in dequeue( O(1) operation..) and in other operation I pick element & put at the rightmost element in dequeue... Through this I approach I got AC...but I m also surprised with editorialist's solution bcoz it is O(n) where my solution is O(nlogn)...but it works well in the given constraints
Just want to share my approach on F, don't Know how to use DSU or function mentioned but can be done using array of priority Queue, Might be a little complex and lengthy at first sight but simpler and easier
a Component=> a priorityQueue(element of priorityQueue array)
Priority queue is used to find element with least degree(0 or 1) in a component
also create a list to store neighbors of every element
there are 4 case when a new query comes.
1) both are included in different(obvious from question) components(can be checked by creating a map) then take the smaller Component and put all its elements to larger component while changing their location in map but before that to merge two components we need to update two elements each of each component changing their degree and adding them in each other's list
2) first element is included in some component then just add 2nd element in first element's group but before that update two elements each of each component changing their degree and adding them in each other's list
3) second element is included in some component , similar to 2nd case
4) no element is included in any component, put both element in new Component and mapping their location(index of their component) and add them to each other,s list
After that we have now a graph(actually a linked List ) , traverse the list to find one element with degree 1 and using that element as first perform dfs to print the array
https://codeforces.me/gym/252240/submission/60240365
In problem D ,
Otherwise assign numbers, where the vertex gets the least number greater than the vertex it goes to.how to do this??Topological sort.
Here's a solution to E that doesn't use associativity.
Consider 2 cases
Case 1: there are at least two distinct characters in $$$s_{n}$$$
Case 2: all the characters in $$$s_{n}$$$ are equal to some character call it $$$u$$$
Case 1:
Take a character that appeared in at least one of $$$s_{1},...,s_{n-1}$$$ call it $$$c$$$.
Let the string $$$t_{c} = s_{n} + c + s_{n}$$$
Then the answer will be the max beauty over all $$$t_{c}$$$.
Case 2
Let dp[i] denote the longest contiguous subsequence of $$$u$$$ in $$$((s_{1}\cdot s_{2}) \cdot \cdot s_{i-1}) \cdot s_{i}$$$
You can calculate dp[1] with two pointers. For dp[i] there are again 2 cases.
If $$$s_{i}$$$ contains a character other than $$$u$$$ the calculation is similar to case 1 replacing beauty with the longest contiguous subsequence of $$$u$$$
Otherwise dp[i]=(dp[i-1]+1)*(length of $$$s_{i}$$$) + dp[i-1]. (You place dp[i-1]+1 copies of $$$s_{i}$$$ around the longest contiguous subsequence of $$$u$$$ in the previous state)
The answer is dp[n]
code 105430189