


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3993 |
| 2 | jiangly | 3743 |
| 3 | orzdevinwang | 3707 |
| 4 | Radewoosh | 3627 |
| 5 | jqdai0815 | 3620 |
| 6 | Benq | 3564 |
| 7 | Kevin114514 | 3443 |
| 8 | ksun48 | 3434 |
| 9 | Rewinding | 3397 |
| 10 | Um_nik | 3396 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 155 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 10 | nor | 152 |






Can someone explain me how the complexity in E becomes 2^(m/2)
Divide the friends in half and calculate the maximal independent set on each part, then merge them, every part can be done in O(2^(m/2) * (m/2)^2). From my solution you will easy see the complexity.
Thanks
can you please elaborate how you are merging the results of two sets, each set have (m/2)*(2^m/2) states , i am not getting how we can use these result to combine because if a path come from set1 to set2 then the states of set2 is not valid anymore(means can't be used directly) since i could have visited some vertices in set1 which blocks some vertices of set2 whose effect is not included in set2 states. please help. in my graph each two nodes have edge between them if they both can be made happier.
The Editorial is so fast!
One of the best contests I wrote, interesting & balanced problems and a fast editorial!
Problem B alternate ideas!!
Make a frequency array (not really frequency though) corresponding to small english alphabets (size:26). Iterate through the given string. Whenever you get consecutive occurences for a alphabet(use a simple while loop), increment the value corresponding to the alphabet in the array. Say you get 'm' consecutive occurences for a alphabet while iterating, this would mean you have to increment the corresponding array value of alphabet by m/k (Think!). Do this whenever you get consecutive occurences for any alphabet. When you have finished iterating, the answer would then be the maximum value in the frequency array.
Thanks!!!
you need to find the maximum occurrence of a substring with length k where every letter is same
I couldn't take part in the contest but invented another solution for E.
One creates a bipartite graph in which edges are between (id of friend) and (id of group between two 1's) if this friend belongs to that group.
Now I only have to find maximal matching in this graph — each selected edge will mean that we have to change our handle to that friend's name before this group.
In my opinion it should fit in the time limit, because we can have only 40 friends.
I will try to implement this solution later and will let you know if it works as well.
Can you elaborate this a bit more? This was the route I took before switching to independent set formulation. Maximal matching would mean that you select only one of the edges from all the edges incident on a friend. How does finding this matching solve the problem?
Ok, so a friend gave me a sign that I misunderstund the problem — I thought a friend should see his name at least once and it is not true — they should see their name each time they visit.
Sorry for mistke. Anyway, this still solves a problem, just not this one :p
There still won't be bipartite graph tho.
I don't think this will work. A name needs to be chosen every time for it to be happy.
This is what I overlooked. Thanks for letting me know! :)
But in Bipartite Matching you can manipulate the already assigned match, but here can you ?
Thanks, for the great round.
It wasn't ABCD were just pure implementation and E has very much similarity with https://codeforces.me/blog/entry/4623
Should a randomized solution pass for E? Can anyone figure out a chance of success. Can use this algo for reference: https://codeforces.me/contest/1105/submission/48630631
Yeah, tests must be stronger, of course. Such solutions should not pass.
But nowadays, random is strong enough :(( Everywhere, on TopCoder, Codeforces and other programming platforms such solution pass when it should not be happened, I see this fact once or twice a week.
Yes I am trying to make counter tests for it, thanks for bringing it out :D
Why there were no tests with the answer 15...38 for the task E? Only 39,40 and small one.
I suppose that "39" for the last testcase corresponds to the "challenge" test, there were challenges on E.
So, without this challenge all tests were < 15 and only "40". Do you know that it can easily be beaten with some solution for small answers and printing "40" otherwise?
How many "bad" solutions you've wrote to check the test pack? It should be > 10 different bad (random, brute force, greedy) solutions that must be written by jury to test their tests and how they are strong enough.
The main thing, that this is not done on Codeforces or other platforms, weak tests lead to weak solutions, random accepts everywhere... Lazy problem setters. Only money. Nothing personal..
Give one contest in a month but strong one, with tests like from Andrew Stankevich on geometry neerc problems.
I was also completely infuriated with random solutions for recent Topcoder SRM 746 task 500, where you have to generate string with length <= 100 from letters "a" and "b" and the number of "good" substrings equal to N (N <= 1000 is given), "good" is a substring where "palindrome check" pairwise symbols are different at all positions. The people divided into 2 groups, one that solved it by creating the technique of generating such strings, other, like Kunyavskiy solved with 10000 or more iterations of random strings where next character is changing with 3/10 probability! So dirty solution for 500 task. And it is only because authors like to accept them.
Are you planning to redo the system tests?
I suppose it can be done only in archive, the contest results are final.
I like your game very much. Thank you very much.
A Player from China
In my solution to E for finding max independent set I remove vertex and her neighbor vertex and edges, which incident by all this vertex, which have minimal neighbor vertexes. And this is got AC. Overall complexity O(M^2). Or am I mistaken somewhere?
В моём решении задачи Е для нахождения минимального независимого множества вершин я находил вершину, имеющую на текущий момент наименьшее количество оставшихся соседей и удалял её, её соседей, и все рёбра, смежные со всеми удаляемыми вершинами. Это решение получило Accepted. Сложность O(M^2), где M — количество друзей. Или я где-то ошибся?
This solution is incorrect, here is a countertest. Your solution outputs 2, while it's possible to satisfy 3 friends (b, c and d).
True, you can also use the countertest from here https://stackoverflow.com/questions/13921679/why-is-greedy-algorithm-not-finding-maximum-independent-set-of-a-graph
Ok, were added testcase 30. But this problem can solve by random))
Can we solve problem E with other way(solution with no graphs)?
No, because this problem can be directly converted to finding maximum independent set. If you end up solving this another way you would have essentially solved the maximum independent set problem
I solved it using greedy algorithm and was quiet surprised to see it accepted.
Solution —
Formed the graph in same fashion as mentioned in editorial.
Submission 48636151
It doesn't mean anything. To prove that there is no polynomial solution, you should convert the maximum independent set problem to this problem, but not vice versa.
This problem is a bijection to the maximum indepent set problem. This is because every single graph can be produced in the problem. Every single graph can also be written in the form of our problem so they are essentially the same problem
You can still solve it without graphs, it will just not be in polynomial time...
Hi, can someone tell me what happened here ?
gcc-14 WA 48634660
gcc-11 AC 48641033
(Codes are identical)
You haven't initialised a variable
prso that a comparisonsol != prends up with undefined behaviour.Hello there :D Concerning problem D
https://codeforces.me/contest/1105/submission/48642557 https://codeforces.me/contest/1105/submission/48642301
I wanted to know why my first solution passed. I only changed this
while(ok) { ok = 0; for(int i = 1 ; i <= p ; i++) ok |= bfs(i); }
to this
while(ok) { ok = 0; for(int i = 1 ; i <= p ; i++) if(v[i].size())
ok |= bfs(i); }
thanks in advance
The initiation of the queue takes a lot of time. This is why you get TLE, I had the same problem. You can take a look at my solutions, I changed the queue from a local variable to a global one and it made a huge difference. ;)
Local variable: > 2000ms Global variable: 46ms
wow, that is very very strange...
This is not strange. All because u create a queue many times, i.e. call the constructor every time. It takes a long time.
Thank you very much
I'm getting WA on test 38 in problem D I simply process all the rounds with bfs I'm curios to know what's wrong with my code can anyone help me. My submission: https://codeforces.me/contest/1105/submission/48643495
Well, as I see you've lost almost 1000 cells: you got 500488+498514=999002 and not 1000000. You've counted all the 1's and 2's so let's submit your code and see whats inside those cells that wasn't counted: submission Looks like rubbish. Can you find how it got there?
Oh, now I see it — guess its got sucked in from the sides, because of copy-pasting a misspell. Look, it's working.. But what happened with that rubbish in 13th line? Why only 13th? Interesting...
What am I missing in E? Lets say that between first two borders there are friends A and B and they are connected by edge. Lets say that between second and third border there are also friends A and B and they are connected too. MIS of given graph is 2 but answer is 1 as far as I know, so where am I wrong?
We add an edge (A, B) to the graph iff A and B appear simultaneously in-between borders at least once. So the size of the MIS is 1 because A and B are connected.
Oh so we make 1 graph that contains edges based on all gaps, and not more graphs for each gap. Okay, thank you :)
Why isn't the anwser 2?
Because if first name is a and second is b(or first is b and second is a) then answer is 0, If first is a and second is a answer is 1, same in the case of b. Answer cannot be 2
oh, i though that a friend were happy if he saw his handle at least once lol
No, he has to see his name every time
I was trying problem C by stars and bars method of combinatorics. DP didn't occur to me.
Problem C can be solved in O(logn) and memorisation.
How?
Let's say You have given range [L, R] and a value n. and you have to find the number of ways so that the after division by 3 remainder should be r (0 <= r < 3). Let's find
Now you can divide n in two parts: n/2 and (n — n/2). Apply the same process to these parts considering these three cases:
case 1: sum of all the numbers in first part(n / 2) has remainder 0, hence the other part must have remainder r.
case 2: sum of all the numbers in first part(n / 2) has remainder 1, hence the other part must have remainder (3 + r — 1) % 3.
case 3: sum of all the numbers in first part(n / 2) has remainder 2, hence the other part must have remainder (3 + r — 2) % 3.
For base case consider n = 1 for r = 0, 1, 2.
That's it. Now sum all these cases and you are done. Time Complexity: O(logn) if you will use unordered_map.
Its like counting a^b .
slappy Can you share your code ?
48637454
.
Thank you for this contest <3, I became pupil again :p
time limit for D was too strict, no python solution passed the TLE during the contest.
you can check out my python2 implementation of intended solutions gets TLE at test case 13
also all these other solutions from other users in python3 got TLE even if most of them are correct as in the editorial TLE test case 13 TLE test case 13 [TLE test case 13](https://codeforces.me/contest/1105/submission/48640359
EDIT: I implemented a solution using collections.deque but still gets TLE, does anyone have any idea how to get AC with python?
Here's the thing, there are multiple python interpreters. The one you used is called CPython and is the standard one, but it is very slow. The standard python interpreter used for competitive programming is called pypy, use that one and everything should run a lot quicker!
Your code submitted in pypy3 easily got accepted (only took 560 ms out of 2000 ms). It's the exact same code, just submitted under pypy3 instead of CPython 3.
There really is an insane difference between CPython and pypy but for some reason many websites don't make it obvious. For example Kattis lets you pick between python 2 and python 3 when you submit, but it is actually pypy2 and CPython3. So anyone submitting under python 3 will essentially get timeout.
A small thing to note, from my experience I think that pypy2 is slightly quicker than pypy3, so if you want to be competetive using python, I highly advice using pypy2. Also speeding up input/output can really be helpful.
EDIT: Saw that what I submitted in pypy3 was not your code but one of the ones you linked. I then tried to submit your code in pypy2. Even in pypy your solution gets timeout because of sorting a huge list of lists is super slow, this time around it can easily be fixed by switching to a bucket sort. However with the TL problems fixed the code gets wrong answer at testcase 15. I think that the way you use double ended queues is wrong. Here is my pypy2 solution if you want to see one way of using them (it is also a pretty quick only taking 405 ms). Your problem is that you've mixed all players into one double ended queue which messes with the order.
Wow this was a really valuable answer! Thank you very much.Made a lot of clarity for me on the topic. I will experiment as you said and report here my findings :)
Can Someone Help me in D problem ? I am getting Memory Limit Exceeded on test 20
My submission — https://codeforces.me/contest/1105/submission/48646487
You forget to pop from the queue :)
Lol.. Then I should got TLE bro xD
I don't know try it maybe it works.
Please, can someone explain to me test 5 in problem D?
4 4 2
1 1000000000
....
....
..2.
...1
3 13
5 11
the first player can only move to a cell with a sequence of moves no more than 1 and the second player can move to a cell with a sequence of moves no more than 1000000000 which means that he can move to any other cell in the grid if it has not been visited by the first player in the first round player 1 can move from cell (4,4) to cell (3,4) and cell (4,3) and the grid looks like this
....
....
..21
..11
then the second player moves to all not-occupied cells and the grid looks like this
2222
2222
2221
2211
hope you understand this and sorry for my bad english..
Thank you.
I have just read the announcement that explain what wasn't explained in the statement. I thought that one can move either up or right or down or left starting from only his origin cell.
Can someone elaborate on Problem C? TIA
Yes if someone can further explain it it would be really nice.
Let's denote
m0as number of x in range L and R, such thatx % 3 = 0m1as number of x in range L and R, such thatx % 3 = 1m2as number of x in range L and R, such thatx % 3 = 2You can find this 3 numbers in O(1)
Also
dp[i][j]the number of ways of the lost array of lengthiand its sum % 3 =jThe base case is dp[1][0] = m0, dp[1][1] = m1, dp[1][2] = m2
Let's think about how to find value for some i > 1, dp[i][0]. There is 3 case to get (a + b) % 3 = 0, we can pair any (a, b) such that
so
dp[i][0] = dp[i - 1][0] * m0 + dp[i - 1][1] * m2 + dp[i - 1][2] * m1sum of the 3 possible case.You can apply the same logic to find dp[i][1] and dp[i][2]
answer is dp[n][0]. My submission
plzz can you explain why you have multiplied dp[i-1][0] with m0 (and similar for others)because order of array matters
what do you mean "order of array matters"?
great
We need to find ways of choosing n numbers in an array, each of which may vary from l to r inclusive such that their sum is a multiple of 3. first we may recast this problem:
let p(x)=(x^l + x^(l+1)+ x^(l+2)+ x^(l+3)+ x^(l+4)+......x^r)^n
now in this p(x), the coefficient of x^i is simply the number of ways we can use n numbers varying from l to r to sum upto i.
As each time an x^i term comes out when we multiply out the n brackets of (x^l + x^(l+1)+ x^(l+2)+ x^(l+3)+ x^(l+4)+......x^r), taking some powers of x between l and r from each bracket and multiplying them out such that their sum reaches i, each unique way we can do this, we increase coefficient of x^i by 1.
So basically the coefficient of x^i in p(x) is the number of ways of choosing the n numbers in the array each varying from l to r such that their sum is i.
So, now we want all ways in which this sum is a multiple of 3. in other words we want the sum of all coefficients of p(x) which are coefficients of powers divisible by 3. so basically if p(x)= x+4x^2+x^3+x^4+x^5 +7x^6 (arbitrary example); we only want coefficient of x^3 and x^6 or 1 + 7 = 8
lets call this sum our answer So for that we can use 3*answer= p(1) + p(w)+ p(w^2)
(where 1, w, w^2 are cube roots of unity) as in the expansion of p(1)+p(w)+p(w^2),only powers divisible by 3 remain as for example if p(x)=2x+3x^2+6x^3:
p(1)+p(w)+p(w^2) will be 3*(6)or 6+6+6 (coefficient of x^3 ) as x and x^2 will sum up to zero (as 1+w+w^2 =0 )
So basically we calculate our answer as (p(1)+p(w)+p(w^2))/3
and p(x)=(x^l + x^(l+1)+ x^(l+2)+ x^(l+3)+ x^(l+4)+......x^r)^n can be easily calculated in log(n) time using fast exponentiation and g-p series sum.
Could you elaborate the last paragraph? Could you also post a link to the code? Thanks
Here is the link to my code: https://codeforces.me/contest/1105/submission/48648308
I'm saying that the final problem is (p(1)+p(w)+p(w^2))/3 where p(x)=(x^l + x^(l+1)+ x^(l+2)+ x^(l+3)+ x^(l+4)+......x^r) now summing this from l to r is tedious. but thankfully we can do so in constant time as the formula for a geometric progression sum is known. x^l + x^(l+1)+ x^(l+2)+ x^(l+3)+ x^(l+4)+......x^r= (x^l)*(x^(r-l+1)-1)/(x-1)
Может ли кто-нибудь объяснить, почему мое решение по E зашло, причем так быстро? 48633102
Мое решение: Я строил граф, где между двумя друзьями было ребро, если они не могли быть счастливы одновременно, затем делил его на компоненты связности, а потом по каждой компоненте отдельно запускал перебор. В переборе я смотрел на текущий набор вершин (изначально брались все в компоненте), если была какая-то пара вершин, соединенных ребром, то я брал наилучший результат от двух рекурентных запусков
от такого же набора вершин, только без одной из этой пары (обозначим ее за А)
от такого же набора вершин, только без всех, соединенных ребром с А
Если никакая пара вершин текущего набора не соединена ребом, то этот набор нас вполне устраивает, и я возвращаю его размер. Результаты переборов для всех компонент я складывал, очевидно, это и был ответ. Вот только я вообще не понимаю, почему это решение работает за быстро. Интуитивно кажется, что существует антитест за 2m.
47th-draganov подсказал, что вот этот алгоритм
Warawreh Can you provide me with some link of The maximum independent set tutorial? also, it would be nice if that explains how to combine meet in the middle technique as well. Thanks
Dance Link can fuck E. Believe me.Very fast.
Can you put your code here?
https://codeforces.me/contest/1105/submission/48645958
Can you explain how you applied dancing links to solve it?
Can someone please explain why my submission for D is giving TLE? I used BFS. https://codeforces.me/contest/1105/submission/48650058
This is a small test case where your code will give TLE think about why it gives TLE and how to fix it :)
Ah! Didn't consider the case when it's impossible to cover all empty cells. Thanks a lot!
You're welcome.
Most people (including me) passed problem E by using a randomized method.I wonder if this is the right way to do it.Because you can hardly make its time complexity worse. :)
If you can hack it,please let me know.Thank you very much!
my code:48652621 Time:62ms
Can anyone explain why an algorithm like this one: 48645129 doesn't MLE? It seems to be storing 2m states in the worst case? I'm not sure where my logic is wrong, and I can't prove that it achieves a bound of 2m / 2. Can anyone help?
I think it is just that the test are weak. There surely are 2m states in the worst case.
I think this round is a little bit too easy,maybe just as easy as Div3. However the time is pretty suitable for Chinese contestants.
I don't think it is a good round. A-D are extremely easy in div.2, while E is an ordinary independent set in general graph, which is not suitable at all for a contest problem (too easy as well if you have seen similar problems). Maybe it is the author who wants to publish his idea to solve such a general problem, but I think it should be in an Edu Round rather than a regular round.
Hope we will have better round in the future.
A wording suggestion: In the tutorial of E, you said
Let's find a first bit of mask. It would be more clear if you say "The first set bit of the mask".approach in submission 48651576 problem E. runs through all masks from 1 till 2^(m/2) (exclusive). and ran a loop to check that mask M contains nodes such that they are not neighbors to each other by going in another loop from 0 to m/2 (exclusive) and getting the or of all masks OM of these nodes (nodes are present in mask) neighbors if OM&M is positive then this mask is invalid otherwise its answer dp(m)=number of bits in M.
then i made bottom up building of dp such that dp(mask) is max(dp(mask),dp(submasks)) by turning one bit off at a time. and going in dp table (bottom up).
then go through masks of the remaining nodes [m/2, m[ and checking if they themselves are valid and getting the mask of their neighbors from [0, m/2[ and now maximize answer over dp(NOT(neighborMask)) + numberOfBitsInThisMask. where NOT(a) is inverse of its bits.
Is that a wrong approach, coz I got wa on 11 and spent enough time to debug.
My solution (or say explanation) to problem E: To find the maximum clique, we first divide the points into two parts. For each subset in the second part, we find out its maximum sub-clique (just a bitmask dp, the transaction is to remove one of the vertices, or all the vertices form a clique). For each subset in the first part, we can easily find out all vertices in the second part that have edges to all vertices we have chosen in the first part, then we can use the maximum sub-clique we have found in the second part to get the answer.
48662260
Why does 0-1 BFS + dp WA15 for D?
https://codeforces.me/contest/1105/submission/48663062.
https://codeforces.me/contest/1105/submission/48662882.
let us see these two solutions.
dir[4][2]={-1,0,1,0,0,1,0,-1} will return Wrong answer on test 15 .
dir[4][2]={0,1,0,-1,1,0,-1,0} will return Accepted.
who can tell me why?
The inner loop does not work as expected. (I made the same mistake...) For example, your code returns 8 2 to this input (9 1 is expected):
because the path (5,1), (5,2), (5,3), (4,3), ..., (3,1) is searched first, and then the shorter path to (3,1) is not considered.
48677210
I changed about my code a bit to fix what you said, but I'm still getting WA15
Oops, I didn't really understand how the original code works.
I'm not quite sure why it does not work, but maybe you have to update dp[x][y] earlier. I just have tried it 48711922 and passed test 15, but got TLE on test 20.
I think complexity of D can be easily reduced to O(n*m + p). A player won't be allowed to play in further rounds if he is blocked from all sides in a round.
So the worst case would be when in each chance we acquire an additional cell only.
isn't the time complexity of authors solution already O(n*m+p) like we won't visit a vertex more than once during indvidual bfs .
Acc. to editorial, if all players are blocked except one and if that only unblocked expands by only one in each round.
Something like this -
2 3 4 5 6 7 8
# # # # # # #
. . . # . . .
. # . # . # .
. # . # . # .
1 # . . . # .
Can anyone help with problem D? I used bfs and have the same complexity but got a TLE somehow... Here's my submission: https://codeforces.me/contest/1105/submission/48635565
Use C++17 you will get Ac.
i tried and it didn't work
Oh no.Sorry for I can't find the mistake.
Can You Help me why I am getting TLE on test 20 https://codeforces.me/contest/1105/submission/48682380
Thanks in advance
tutu
I think the solution is not enough to solve. To solve this problem is mainly about which language you choose(there is no code Accepted with Python2/3,but if I copy some codes and change them to pypy is enough.For C++ it is worse C++11 will Failed on system test and C++17 will Ac....).So I think the writer should try both java and python to make sure the time limit is enough.C++17'1000ms maybe can do things more than 3000ms of java and python!!
In div 2 D, i used priority queue of vector and i got TLE and priority queue of struct worked properly and rather it was faster than the previous one ?
Can you please help me.. I getting TLE on test 20 in problem D.
Code https://codeforces.me/contest/1105/submission/48682380
Can Anyone please help me.. I getting TLE on test 20 in problem D.
Code https://codeforces.me/contest/1105/submission/48682380
For problem D, I tried a solution using only two queues, but keep getting wrong answer on the test case 15 :( Can anybody help?
My submission link
I solved. The problem was the choice of the queue.
Outputs 9 3 instead of 10 2
Thanks for your case. It helps me a lot. :P
btw, how do you construct this case?
Actually I search for all the examples for problem D in this post and the original post. :(
It would be really helpful if you say how you fixed this problem :)
Hello, I got stuck on problem E because my Algorithm outputs weird ans and If I run my solution on another compiler it can output the real answer, so I dont kow if I doing a mistake reading graph. Here is my last Subm: 48689549
Put some "printf(i, count[i])" in your code and look how your count is growing
Can E be solved in O(2m / 2)? I could solve it in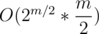 but not sure if it can be solved in less than this complexity. The editorial is not clear to me and I am not quite sure about its solution's complexity.
but not sure if it can be solved in less than this complexity. The editorial is not clear to me and I am not quite sure about its solution's complexity.
can you please explain your approach . if you did using meet in middle then how you proceed further after maintaining the bitmasks for each states for maximum distance in each set. how to merge the processing of both sets?
Imagine each friend as a bit and nbr[i] is a value having set bits only in positions corresponding to friends adjacent to the ith friend. Let dp[j] be the maximum independent set size, where its participants have their corresponding bits set in j.
How to calculate dp[j]? iterate on every set bit of j, let the current set bit in loop be the kth bit, if nbr[k] has no intersection with j (nbr[k]&j = 0), then continue looping normally, else, you have either to remove the kth friend or remove the intersection (nbr[k]&j) from j, so dp[j] will be max(dp[x], dp[y]), where x is j after clearing the kth friend bit, y is j after clearing the intersection bits. If the loop finished without entering the else branch, dp[j] will just be count of set bits in j.
Assume we calculated dp1 for the most significant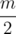 bits and dp2 for the least significant
bits and dp2 for the least significant 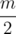 bits, for every possible mask m1 in dp1, make mask m2 for dp2, where the kth bit in m2 is set only if nbr[k]&m1 = 0 (no intersection with m1). And set ans = max(ans, dp[m1] + dp[m2]).
bits, for every possible mask m1 in dp1, make mask m2 for dp2, where the kth bit in m2 is set only if nbr[k]&m1 = 0 (no intersection with m1). And set ans = max(ans, dp[m1] + dp[m2]).
thanks sir for explaining, while building dp[j] if we ever entered in else part then we have to remove either Kth bit or intersection part in both case mask(j) value is no longer j then why we are saving result in dp[j], according to dp[j] definition it should be only either zero or number of set bits in j isn't it?
because definition of dp1[j] matters while choosing mask in dp2,
but sir i think with your approch we will never miss the most optimal answer instead of not choosing the most optimal dp1[m1],dp2[m2] pair every time isn't it, am i right?
If you chose a specific dp2's mask m2 based on a specific dp1's mask m1 which imposed clearing some bits in m2 because the friends representing these bits have neighbors which have their bits set in m1, then even if dp1[m1] was a number less than set bits count in m1, you will reach the optimal answer anyway. Because eventually you will reach that m1 where dp[m1] = set bits count in m1.
thanks a lot got it accepted:D
can anyone explain problem C in more detail ?
you need to store the number of ways to recover the array till index i such that the remainder of "sum so far" divided by 3 equals to 0,1 and 2 as you can have three remainders, this way you can calculate 3 same(same meaning) values for next index by using the number of different numbers you have in range l->r , means number of numbers giving remainder 0,1,2.
for 0 -> previous=0 , current=0
previous=1 , current=2
previous=2 , current=1
for 1-> previous=0 , current=1 ... and so on
How to solve A if the constraints over Ai were large ?
EDIT — Here is the ternary search solution
I think the cost function cost(t) is unimodal. That means you can find the minimum cost using ternary search. overall complexity will be nlog(Max).
I see. Good point. Do you have a proof of unimodality ?
You could take a median (n%2==1) or two (n%2==0) and +/-1 on each of median. Then check this 3-6 numbers.
Proof ?
By median definition. And +/-1 is cause of problem statement.
@admin,
I think the testcases in Problem D are weak. I have submitted 2 solutions (links below) having same code (just order of checking conditions is changed).
Solution 1 (verdict: WA): http://codeforces.me/contest/1105/submission/48716141
Solution 2 (verdict: AC): http://codeforces.me/contest/1105/submission/48716349
As you can see I have just altered the checking condition in BFS to store in queue. It gave AC. The problem is we need to know maximum steps we can go from this cell before marking it visited. Else it is possible that not all cells (that could have been visited in this step) will be visited.
If I am mistaking something do tell me. Thanks!
If constraints of N in Problem C were large (N <= 10^{18}), then we could use matrix exponentiation to solve it.
Here is my code for reference. :)
It is a faster way to find the solution if N were large. :)
Complexity is O(K^3 log N), where K is the size of the matrix being used.
We can also solve E without memoization or meet in the middle ideas. In
solve(mask), we look at the first set bit of the mask. If this node doesn't have any other neighbors inmask, we should always take it and we do one recursive call. Otherwise, we have two options: we take it and we remove it and all its neighbors frommask, or we don't take it and we only remove it frommask.To analyze the time complexity of
solve, let's define a function T(k) that is a bound on the time to computesolve(mask)ifmaskhas k set bits. In the first case mentioned above (the first node has no neighbors inmask), we only do one recursive call, so T(k) ≥ T(k - 1). Otherwise, we have to do two recursive calls: one on a set of size k - 1 and one on a set of size at most k - 2 (this is because we removed at least one neighbor frommask). So T(k) ≥ T(k - 1) + T(k - 2). This is the worse bound, so let's take T(k) = T(k - 1) + T(k - 2) to get our bound on the running time. With base cases of T(0) = T(1) = 1, we see that T(k) is the kth Fibonacci number. That is, T(k) ≈ 1.618k. And since 1.61840 ≈ 108, this should run in time.Accepted submission: https://codeforces.me/contest/1105/submission/48864093
I tried to solve 1105D Kilani and the game using multi-source bfs but I keep on getting TLE,can anyone help me out?
https://codeforces.me/contest/1105/submission/50567716 (Comments added to every line of code for better understanding)
The idea of taking 3k,3K+1,3K+2 was very interesting.. thanks
Anyone can help with Problem C?
I think my mistake is in the cnt() function though i dont know why it is incorrect
[submission:https://codeforces.me/contest/1105/submission/212810915]