


Since the original data has been lost during the dark days of Codeforces, no version of the editorial has been re-released, and I feel the round itself is quite educational, so I decided to give a try.
390A - Inna and Alarm Clock
The criterion shows that we can only use either vertical segments or horizontal segments.
Since there is no limit on the segments' length, we can see that it's always optimal to use a segment with infinite length (or may be known as a line).
We can see that the vertical line x = a will span through every alarm clocks standing at positions with x-coordinate being equal to a. In a similar manner, the horizontal line y = b will span through every alarm clocks standing at positions with y-coordinate being equal to b.
So, if we use vertical lines, the number of segments used will be the number of distinct values of x-coordinates found in the data. Similarly, the number of horizontal segments used will be the number of distinct values of y-coordinates found.
The process can be implemented by a counting array, or a map.
Time complexity: 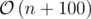 for regular arrays, or
for regular arrays, or 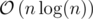 for maps.
for maps.
Submission link: 48214007
#pragma GCC optimize("Ofast")
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
mt19937 rng32(chrono::steady_clock::now().time_since_epoch().count());
mt19937_64 rng64(chrono::steady_clock::now().time_since_epoch().count());
int main(int argc, char* argv[]) {
ios_base::sync_with_stdio(0); cin.tie(NULL);
int n; cin >> n;
map<int, int> cntx, cnty;
while (n--) {
int x, y;
cin >> x >> y;
cntx[x]++; cnty[y]++;
}
cout << min(cntx.size(), cnty.size()) << endl;
return 0;
}
Submission link: 48213984
#pragma GCC optimize("Ofast")
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
mt19937 rng32(chrono::steady_clock::now().time_since_epoch().count());
mt19937_64 rng64(chrono::steady_clock::now().time_since_epoch().count());
int main(int argc, char* argv[]) {
ios_base::sync_with_stdio(0); cin.tie(NULL);
int n; cin >> n;
vector<int> cntx(101, 0);
vector<int> cnty(101, 0);
while (n--) {
int x, y;
cin >> x >> y;
cntx[x]++; cnty[y]++;
}
int distinctx = 0, distincty = 0;
for (int i=0; i<101; i++) {
distinctx += (cntx[i] > 0);
distincty += (cnty[i] > 0);
}
cout << min(distinctx, distincty) << endl;
return 0;
}
390B - Inna, Dima and Song
From the constraints given, for the i-th song, provided there exists corresponding xi and yi values, then the following inequality must hold: 2 ≤ xi + yi ≤ 2·ai.
Thus, if any bi is either lower than 2 or higher than 2·ai, then no xi and yi can be found, thus, Sereja's joy will surely decrease by 1.
Amongst all pairs of 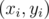 that xi + yi = bi, the pair with the highest value of xi·yi will be one with the equal value of xi = yi (this can be proven by the famous AM-GM inequality).
that xi + yi = bi, the pair with the highest value of xi·yi will be one with the equal value of xi = yi (this can be proven by the famous AM-GM inequality).
Thus, if bi is divisible by 2, we can easily pick  .
.
Also, from this, we can see (either intuitively or with static proofs) that the lower the difference between xi and yi is, the higher the value xi·yi will be. Thus, in case bi being odd, the most optimal pair will be 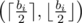 or
or 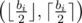 (the order doesn't matter here).
(the order doesn't matter here).
Time complexity: 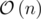 .
.
Submission link: 48212208
#pragma GCC optimize("Ofast")
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
mt19937 rng32(chrono::steady_clock::now().time_since_epoch().count());
mt19937_64 rng64(chrono::steady_clock::now().time_since_epoch().count());
int main(int argc, char* argv[]) {
ios_base::sync_with_stdio(0); cin.tie(NULL);
int n; cin >> n;
vector<int> a(n), b(n);
for (auto &z: a) cin >> z;
for (auto &z: b) cin >> z;
long long Joy = 0;
for (int i=0; i<n; i++) {
if (b[i] < 2 || b[i] > a[i] * 2) {Joy--; continue;}
int x = b[i] / 2, y = b[i] - x;
Joy += 1LL * x * y;
}
cout << Joy << endl;
return 0;
}
390C - Inna and Candy Boxes
The query content looks pretty confusing at first, to be honest.
Since k is static throughout a scenario, we can group the boxes into k groups, the z-th box (in this editorial let's assume that the indices of the boxes start from 0) falls into group number 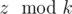 .
.
Then, each query can be simplified as this: "Is that true that among the boxes with numbers from li to ri, inclusive, the candies lie only in boxes of group 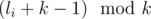 ?
?
To make sure the answer for a query being "Yes", Dima has to remove candies from all candied-box in all groups other than , while in that exact group, fill every empty box with a candy. Obviously, we'll consider boxes with indices between li and ri inclusively only.
We can make k lists, the t-th (0-indexed) list stores the indices of candied boxes in group t.
We'll process with each query as the following:
- Obviously, given from the criteria, each range will consist of exactly
 boxes per each group. Let's denote
boxes per each group. Let's denote 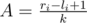 .
. - Traverse all groups, for the t-th group (again, 0-indexed), let's denote xt as the number of candied boxes of group t in the given range. This value can be calculated quickly through binary searching the constructed lists above.
- If group t is not the group being demanded to have candies (group ), we'll need to perform xt actions (removing candies). Otherwise, we'll need to perform A - xt actions (adding candies to empty boxes).
Time complexity: 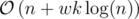 .
.
Submission link: 48213932
#pragma GCC optimize("Ofast")
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
mt19937 rng32(chrono::steady_clock::now().time_since_epoch().count());
mt19937_64 rng64(chrono::steady_clock::now().time_since_epoch().count());
int main(int argc, char* argv[]) {
ios_base::sync_with_stdio(0); cin.tie(NULL);
int n, k, w; string s;
cin >> n >> k >> w >> s;
vector< vector<int> > CandyGrp(k);
for (int i=0; i<n; i++) {
if (s[i] == '0') continue;
CandyGrp[i % k].push_back(i);
}
while (w--) {
int l, r;
cin >> l >> r; l--; r--;
int res = 0;
int demandedGroup = (l + k - 1) % k;
int BoxesPerGroup = (r - l + 1) / k;
for (int id=0; id<k; id++) {
int x = lower_bound(CandyGrp[id].begin(), CandyGrp[id].end(), l) - CandyGrp[id].begin();
int y = upper_bound(CandyGrp[id].begin(), CandyGrp[id].end(), r) - CandyGrp[id].begin();
if (id == demandedGroup) {
res += (BoxesPerGroup - (y - x));
}
else res += (y - x);
}
cout << res << endl;
}
return 0;
}
390D - Inna and Sweet Matrix
We can see that the most optimal placement will be choosing k cells being nearest to cell (1, 1) (yup, including (1, 1) itself).
To find these k points, we can simply do a BFS starting from (1, 1), with traceback feature to construct the paths to get to those cells.
However, keep in mind that any cell being candied will later on become obstacles for the following paths. Thus, to avoid blocking yourself, you should transfer candies to the farthest cells first, then getting closer. Thus, cell (1, 1) will be the last one being filled with candy.
Time complexity: 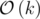 or
or 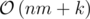 , based on implementation (I myself did , since the difference isn't too much).
, based on implementation (I myself did , since the difference isn't too much).
Submission link: 48213856
#pragma GCC optimize("Ofast")
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
mt19937 rng32(chrono::steady_clock::now().time_since_epoch().count());
mt19937_64 rng64(chrono::steady_clock::now().time_since_epoch().count());
int dx[] = {-1, +0, +0, +1};
int dy[] = {+0, -1, +1, +0};
pair<int, int> Default = {-1, -1};
int main(int argc, char* argv[]) {
ios_base::sync_with_stdio(0); cin.tie(NULL);
int n, m, k; cin >> n >> m >> k;
vector<vector<int>> Dist(n+2, vector<int>(m+2, 4444));
vector<vector<pair<int, int>>> Last(n+2, vector<pair<int, int>>(m+2, Default));
stack<pair<int, int>> Cells;
int cost = 0;
queue<pair<int, int>> Q;
Q.push({1, 1}); Dist[1][1] = 1;
while (!Q.empty() && Cells.size() < k) {
pair<int, int> C = Q.front(); Q.pop();
Cells.push(C); int x = C.first, y = C.second;
cost += Dist[x][y];
for (int dir=0; dir<4; dir++) {
if (x + dx[dir] < 1 || x + dx[dir] > n) continue;
if (y + dy[dir] < 1 || y + dy[dir] > m) continue;
if (Dist[x+dx[dir]][y+dy[dir]] != 4444) continue;
Dist[x+dx[dir]][y+dy[dir]] = Dist[x][y] + 1;
Q.push({x + dx[dir], y + dy[dir]});
Last[x+dx[dir]][y+dy[dir]] = C;
}
}
cout << cost << endl;
while (!Cells.empty()) {
int x = Cells.top().first, y = Cells.top().second; Cells.pop();
stack<pair<int, int>> Traceback;
while (x != -1 && y != -1) {
Traceback.push({x, y});
pair<int, int> NextCell = Last[x][y];
x = NextCell.first; y = NextCell.second;
}
while (!Traceback.empty()) {
pair<int, int> CurCell = Traceback.top();
Traceback.pop();
cout << "(" << CurCell.first << ", " << CurCell.second << ") ";
}
cout << endl;
}
return 0;
}
390E - Inna and Large Sweet Matrix
Let's denote A as the total number of candies on the board, Ri as the total number of candies on the i-th row (1 ≤ i ≤ n), Cj as the total number of candies on the j-th column (1 ≤ j ≤ m).
Also, let's denote 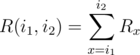 and
and 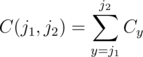 .
.
Let's considered the 2nd type of query first. Denoting the answer for the query as f(x1, y1, x2, y2), we can see that f(x1, y1, x2, y2) = R(x1, x2) + C(y1, y2) - A (you can draw a simple diagram and validate this function).
Thus, the problem is now reduced to calculating R(x1, x2), C(y1, y2) and A:
- A can be easily calculated. After each query of the 1st type with parameters x1, y1, x2, y2, v; A will be increased by v·(x2 - x1 + 1)·(y2 - y1 + 1).
- The calculation of R(x1, x2) and C(y1, y2) makes us thinking about some kinds of data structures that support range sum update and range sum query. Segment trees and Fenwick trees can both work on that. Personally I used segment trees, they fit in just right for the memory limit (I implemented it by vectors, regular arrays will obviously be safer).
Time complexity: 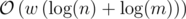 .
.
Submission link: 48213830
#pragma GCC optimize("Ofast")
#include <bits/stdc++.h>
using namespace std;
#define endl '\n'
mt19937 rng32(chrono::steady_clock::now().time_since_epoch().count());
mt19937_64 rng64(chrono::steady_clock::now().time_since_epoch().count());
struct SegTree_Sum {
int n; vector<long long> Tree, Lazy;
SegTree_Sum() {}
SegTree_Sum(int _n) {
n = _n;
Tree.resize(n*4);
Lazy.resize(n*4);
}
void Propagate(int node, int st, int en) {
if (Lazy[node] == 0) return;
Tree[node] += Lazy[node] * (en - st + 1);
if (st != en) {
Lazy[node*2+1] += Lazy[node];
Lazy[node*2+2] += Lazy[node];
}
Lazy[node] = 0;
}
void Update(int node, int st, int en, int L, int R, long long val) {
Propagate(node, st, en);
if (en < st || R < st || en < L) return;
if (L <= st && en <= R) {
Lazy[node] += val;
Propagate(node, st, en); return;
}
Update(node*2+1, st, (st+en)/2+0, L, R, val);
Update(node*2+2, (st+en)/2+1, en, L, R, val);
Tree[node] = Tree[node*2+1] + Tree[node*2+2];
}
long long Sum(int node, int st, int en, int L, int R) {
Propagate(node, st, en);
if (en < st || R < st || en < L) return 0LL;
if (L <= st && en <= R) return Tree[node];
long long p1 = Sum(node*2+1, st, (st+en)/2+0, L, R);
long long p2 = Sum(node*2+2, (st+en)/2+1, en, L, R);
return (p1 + p2);
}
void RangeUpdate(int L, int R, long long val) {
Update(0, 0, n-1, L, R, val);
}
long long RangeSum(int L, int R) {
return Sum(0, 0, n-1, L, R);
}
};
int main(int argc, char* argv[]) {
ios_base::sync_with_stdio(0); cin.tie(NULL);
int n, m, w; cin >> n >> m >> w;
long long TotalCandies = 0;
SegTree_Sum TreeRow = SegTree_Sum(n);
SegTree_Sum TreeCol = SegTree_Sum(m);
while (w--) {
int t, x1, y1, x2, y2;
cin >> t >> x1 >> y1 >> x2 >> y2;
if (t == 0) {
int v; cin >> v;
TotalCandies += 1LL * (x2 - x1 + 1) * (y2 - y1 + 1) * v;
TreeRow.RangeUpdate(x1, x2, 1LL * v * (y2 - y1 + 1));
TreeCol.RangeUpdate(y1, y2, 1LL * v * (x2 - x1 + 1));
}
else if (t == 1) {
long long res = 0;
res += TreeRow.RangeSum(x1, x2);
res += TreeCol.RangeSum(y1, y2);
res -= TotalCandies;
cout << res << endl;
}
}
return 0;
}







thanks.
Good Job
Already the account with most ACs in the country, what a hard-working person!
Did you find this contest by accident or have you done it all the way back there ?
I just came across it while searching for some relaxing undone contest to do virtual, then I found this :D
What is your motivation to train so hard ? I want to be as good as you are, but I'm so lazy xD
I'm quite of a guy with innate self-motivating ability :D
Also, tbh, I have only stepped into CP since college, which is way late compared to many other guys. To fill the gap, guess I have no better choice but double my efforts ;)
I really admire you, how much time do you spend a day to practise CP?