


Hello, Codeforces!
Some time ago I created a blog post about Sqrt-tree. If you didn't read this post, please do it now.
But earlier, we were able just to answer the queries on a static array. Now we will make our structure more "dynamic" and add update queries there.
So, let's begin!
Update queries
Consider a query 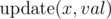 that does the assignment ax = val. We need to perform this query fast enough.
that does the assignment ax = val. We need to perform this query fast enough.
Naive approach
First, let's take a look of what is changed in our tree when a single element changes. Consider a tree node with length l and its arrays: 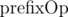 ,
, 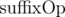 and
and 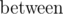 . It is easy to see that only
. It is easy to see that only 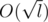 elements from and will change (only inside the block with the changed element). will change O(l) elements. Therefore, total update count per node is O(l).
elements from and will change (only inside the block with the changed element). will change O(l) elements. Therefore, total update count per node is O(l).
We remember that any element x is present in exactly one tree node at each layer. Root node (layer 0) has length O(n), nodes on layer 1 have length  , nodes on layer 2 have length
, nodes on layer 2 have length 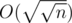 , etc. So the time complexity per update is
, etc. So the time complexity per update is 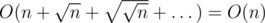 .
.
But it's too slow. Can it be done faster?
A sqrt-tree inside the sqrt-tree
Note that the bottleneck of updating is rebuilding of the root node. To optimize the tree, let's get rid of it! Instead of array, we store another sqrt-tree for root. Let's call it 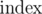 . It plays the same role as — answers the queries on segments of blocks. Note that the rest of the tree nodes don't have , they keep their arrays.
. It plays the same role as — answers the queries on segments of blocks. Note that the rest of the tree nodes don't have , they keep their arrays.
A sqrt-tree is indexed, if its root node has . A sqrt-tree with array in its root node is unindexed. Note that is unindexed itself.
So, for the indexed tree, we have the following algorithm for updating:
Update
and in .Update
. It has length and we need to update only one item in it (that represents the changed block). So, the time complexity for this step is . We can use the previous algorithm to do it.Go into the child node that represents the changed block and update it in
, again with the previously described algorithm.
Note that the query complexity is still O(1): we need to use in query no more than once, and this will take O(1) time.
So, total time complexity for updating a single element is . Hooray! :)
Implementation
It is just a slightly modified code of a static sqrt-tree. Here it is.
Lazy propagation
Sqrt-tree also can do things like assigning an element on a segment. 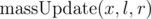 means ai = x for all l ≤ i ≤ r.
means ai = x for all l ≤ i ≤ r.
There are two approaches to do this: one of them does 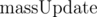 in
in 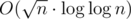 , keeping O(1) per query. The second one does in , but the query complexity becomes
, keeping O(1) per query. The second one does in , but the query complexity becomes 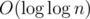 .
.
We will do lazy propagation in the same way as it is done in segment trees: we mark some nodes as lazy, meaning that we'll push them when it's necessary. But one thing is different from segment trees: pushing a node is expensive, so it cannot be done in queries. On the layer 0, pushing a node takes time. So, we don't push nodes in query, we only see if the parent or current node is lazy, and just take it into account while performing queries.
First approach
In the first approach, we say that only nodes on layer 1 (with length 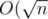 ) can be lazy. When pushing such node, it updates all its subtree including itself in . The process is done as follows:
) can be lazy. When pushing such node, it updates all its subtree including itself in . The process is done as follows:
Consider the nodes on layer 1 and blocks corresponding to them.
Some blocks are entirely covered by
. Mark them as lazy in .Some blocks are partially covered. Note there are no more than two blocks of this kind. Rebuild them in
. If they were lazy, take it into account.Update
and for partially covered blocks in (because there are only two such blocks).Rebuild the
in .
So we can do fast. But how lazy propagation affects queries? They will have the following modifications:
If our query entirely lies in a lazy block, calculate it and take lazy into account. O(1).
If our query consists of many blocks, some of which are lazy, we need to take care of lazy only on the leftmost and the rightmost block. The rest of the blocks are calculated using
, which already knows the answer even on lazy block (because it's rebuilt after each modification). O(1).
The query complexity still remains O(1).
Second approach
In this approach, each node can be lazy (except root). Even nodes in can be lazy. So, while processing a query, we have to look for lazy tags in all the parent nodes, i. e. query complexity will be .
But will become faster. It will look in the following way:
- fully covers some blocks. So, lazy tags are added to them. It is .
Update
and for partially covered blocks in (because there are only two such blocks).Do not forget to update the index. It is
(we use the same algorithm as in the next item). For partially covered blocks, we go to the nodes representing them and call
recursively (reminds something, doesn't it? :) ).
Note that when we do the recursive call, we do prefix or suffix . But for prefix and suffix updates we can have no more than one partially covered child. So, we visit one node on layer 1, two nodes on layer 2 and two nodes on any deeper level. So, the time complexity will be 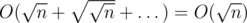 . The approach here is similar to the segment tree mass update.
. The approach here is similar to the segment tree mass update.
Implementation
I am too lazy (like a node in an sqrt-tree :) ) to write the implementation of lazy propagation on an sqrt-tree. So, I leave it as an exercise. If someone provides an implementation for this, I'll post it here mentioning the author.
Conclusion
As we can see, sqrt-tree can perform update queries and do lazy propagation. So, it provides the same functionality as segment trees, but with faster queries. The disadvantage is slow update time, but sqrt-trees can be helpful if we have many ( ≈ 107) queries but not many updates.
Thanks for reading this post. Feel free to write in comments if there are mistakes in it or something is not clear. I hope that this data structure will be helpful for you.
I will publish another one post about sqrt-tree soon.
Thanks to Vladik for inspiring me to write this post.







Auto comment: topic has been updated by gepardo (previous revision, new revision, compare).
Isn't this called veb-tree?
No. Though the structure of veb-tree and sqrt-tree is similar, they are different. Veb-tree keeps maximum and minimum key in each node, but sqrt-tree keeps three arrays. Also their supported operations differ.