


Hello Codeforces!
On July 16, 18:05 MSK Educational Codeforces Round 25 will start.
Series of Educational Rounds continue being held as Harbour.Space University initiative! You can read the details about the cooperation between Harbour.Space University and Codeforces in the blog post.
The round will be unrated for all users and will be held on extented ACM ICPC rules. After the end of the contest you will have one day to hack any solution you want. You will have access to copy any solution and test it locally.
You will be given 7 problems and 2 hours to solve them.
The problems were prepared by Ivan BledDest Androsov and me.
Good luck to all participants!
UPD: The editorial can be found here.
Congratulations to the winners:
| Rank | Competitor | Problems Solved | Penalty |
|---|---|---|---|
| 1 | halyavin | 7 | 297 |
| 2 | Shik | 7 | 433 |
| 3 | Kaban-5 | 6 | 132 |
| 4 | sugim48 | 6 | 160 |
| 5 | JustasK | 6 | 164 |
Congratulations to the best hackers:
| Rank | Competitor | Hack Count |
|---|---|---|
| 1 | halyavin | 219:-58 |
| 2 | kuko- | 97:-2 |
| 3 | uwi | 85:-7 |
| 4 | Yazmau | 35:-5 |
| 5 | aleex | 25 |
929 successful hacks and 587 unsuccessful hacks were made in total!
And finally people who were the first to solve each problem:
| Problem | Competitor | Penalty |
|---|---|---|
| A | Lewin | 0:01 |
| B | bmerry | 0:05 |
| C | shubhiks1032 | 0:06 |
| D | A_A_ | 0:06 |
| E | bmerry | 0:24 |
| F | gvaibhav21 | 0:39 |
| G | iiiLoveYOU2018 | 1:06 |






Silver Jubilee of Edu cf rounds! :O
you forget thank MikeMirzayanov
When will be the next round ?
To see the following picture, it seems like the next Educational Round will be end of July. Educational Codeforces Rounds held once per two weeks approximately.
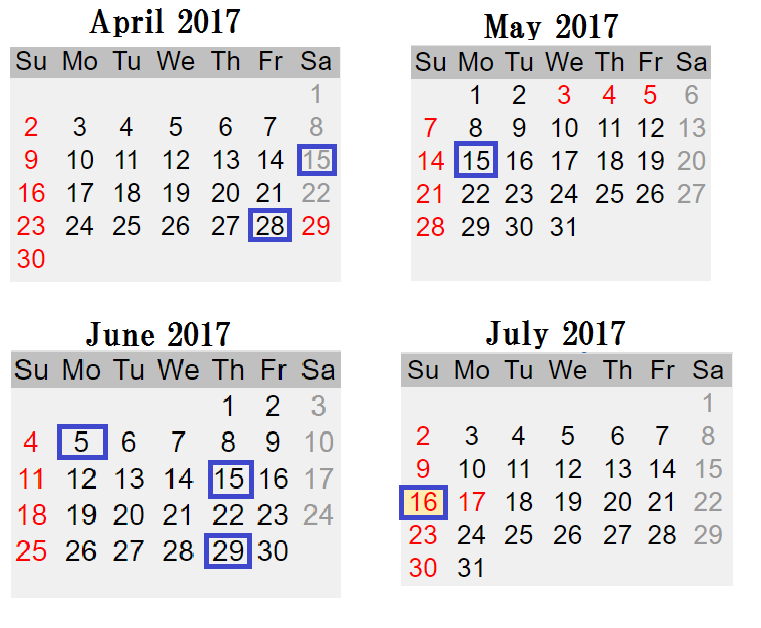
To see the following picture, you just need eyes. ;)
How to solve E, without WA on test 7?
Same question. I tried sorting all vertices by connectivity component, if they equals by count all children, if equals by number of vertex.
I only saw it in the last 5 minutes (which was just in time for me). The trick is to look at the problem backwards: determine which node gets the last label.
Can you please explain why it is optimal to go backwards?
We can prove it by contradiction. Take any graph with the smallest number of nodes for which this algorithm does not give an optimal labeling. The largest label must always be assigned to a node with no outgoing edges, but it can't be the largest of those nodes (otherwise the algorithm would give the optimal labeling). Lets call the largest node with no outgoing edges x and the node that has the largest label in the optimal labeling y. Then after labeling y with the largest label, the remaining part of the graph is correctly labeled by the algorithm (otherwise we would have a smaller graph for which the algorithm gives an incorrect result). This will first label some nodes greater than x and then it will label x. But we get a better labeling by labeling x with the largest label, y with the next largest and then label the same nodes as before. This is because of the nodes labeled so far y is the smallest node (since y < x and all other labelled nodes are greater than x) and in the partial labeling we have labeled the same nodes using the same labels. So we have a contradiction, which means our assumption was wrong and therefore there is no graph that our algorithm labels incorrectly.
Thank you. That is a really nice proof.
Let us have a random valid assignation.
Let a_1 < a_2 < .. < a_i be leaves in our DAG. Then we can observe that given any assignation of the values, we can swap the values between leaves without creating a wrong solution, hence we know that the best answer will have the lowest value at the node with smallest index, second lowest value to the second smallest index ... and the largest value at the largest index.
Now we can see that the value of a_s has to be be n. After having this value assigned, we can ignore node a_s because any value we assign to any node will be lower than n.
Hence we can take out node a_s, and reconsider the new set of leaves, and apply the same argument assigning n, n-1 etc.
The implementation can be done with a adjacency list (saving back edges) and a array to mantain the number of unprocessed child nodes.
Thank you
I tried the greedy approach and just wanted to give the first location the minimum number it can get. For getting the minimum number I reversed all the edges and tried to do a level order traversal until I reached a level where there were no vertices then I tried to give lowest numbers to the lowest level in a sorted order. But don't know why my solution gives MLE verdict Code
I reversed every edge, then applied greedy algorithm backwards (that is, we go through the new topological order assigning values from bigger to smallest with a priority queue to get the biggest value that can be inserted right now). This is a test that helped me
6 5
6 2
5 2
2 1
4 3
3 1
The answer should be 6 3 5 4 1 2
6 4 5 1 2 3
WA7 tho.
Reversed all edges and used bfs for enumerating at first the farthest layers.
The answer should be 6 3 5 4 1 2
I will edit the post to have this
Well, yeah, I see where my solution went wrong :(
Could someone plz tell me why I'm getting TLE on Problem D Test 9? 28613487
Does centroid decomposition pass the limits for tree queries??
Or is it the intended solution?
The problem is with memory, my solution with centroid decomposition uses O(nlogn) memory and i've got mle. Maybe there are some optimalizations, but i think it wasnt intended solution.
Yeah . I thought of same problem and did not code it.
I passed with centroid decomposition with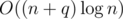 time and
time and  memory (after the contest though).
memory (after the contest though).
I got it to pass both the time and memory limit (barely), but looking at some other solutions, I am now quite sure it is not the intended solution :).
IDK about centroid decomposition, but this task has very simple solution with single dfs, that calculates minimum index on path from root (which is the vertex from the first query) to each vertex. May be it's not the intended solution =)
Why do people always try to solve tree problems with centroid decomposition? :D
The problem at hand has a solution much simpler and more natural than CD.
I agree. I guess it is just the hammer-nail-thing Petr mentioned in one of his recent blog posts.
Btw, my centroid decomposition solution from the contest was hacked (time limit exceeded), but afterwards I optimized my code somewhat and now it passes in 2.4 seconds (28668357).
28615568 F
why this submission is wrong?
Plz help me out here i think in problem C answer should be only 0 or 1 because when we have to solve the question from other judge then we will choose problem with maximum difficulty and after that we don't have to go any other judge again ..because now we can solve all problem of given list.
EDIT: thanks for help , sorry it was my bad i thought from other judges we can select problem of any defficulty now i got itn thanks again
For solving problem with maximum difficulty x , you should have solved a problem with difficulty of x/2 first.
He can only choose those problem from other judge if it difficulty
<= ai/2.Here he will choose 6 and 12, so answer is 2.
How to solve "Suitable Replacement" ?
What is the hacking test for problem A? > <
Diagonals
Auto comment: topic has been updated by awoo (previous revision, new revision, compare).
Hack window is n't opening for me.Anyone else facing the same issue?
Same... It is for every edu somehow...
My best 10 minutes in entire Hacking Phase
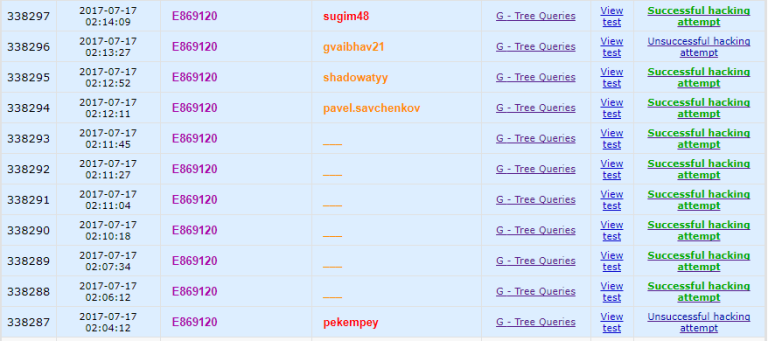
How did you hack the same person radoslav11 more than once in tinny time ?
This is why I managed to hack the same person more than once in tiny time.
:'( xD
This man halyavin is B killer
What's going on with the testing of the round??
Aren't testing suppose to run after adding all the hack test cases? Is that over?
What is the correct answer for this test case, problem E:
11 1
1 2
I think: 1 10 11 2 3 4 5 6 7 8 9
Am i right ?
No, the correct answer is 1 2 3 4 5 6 7 8 9 10 11
Is not 1 10 11 2 3 4 5 6 7 8 9 lexicographically smaller then 1 2 3 4 5 6 7 8 9 10 11 ?
u have to compare number by number
so
1 2 ...is less than1 10 ...Thanks
Why is 2<10 lexicographically? Can you please give definition of lexicographically smaller? I also thought that 10 < 100 < 101 < 2 < 20 < ... etc. when it comes to lexicographical order. Thanks.
Read the statement more attentively:
Permutation should be lexicographically smallest among all suitable.2 isn't less than 10 lexicographically but permutation [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] is less then permutation [1, 10, 2, 3, 4, 5, 6, 7, 8, 9]
You can read about permutations here Generation in lexicographic order
Sometimes i just wonder.
How do the problem setters set the constrains such a way, that every time you will feel , may be an optimized brute-force may just get AC with milliseconds remaining, but in reality it gets TLE just for one or two milliseconds :')
Not gonna fall into that trap again i say to myself each and every time :'v
Well, maybe problemsetters code the solutions they don't want to pass beforehand and check them on tests? :D
Though it's still weird to think about bruteforce (even optimized) solutions for tasks with big constraints. Which tasks did you imply?
awoo I was talking about problem F. I tried to do it with hash. But pre-calculation was N * N * log(N) which i thought may just get AC within time limit.
But it gets TLE for some trivial and easy cases :|
Oh, actually, before hacks there were a few AC solutions which included hashes. Still one modulo is hackable and we tried to make sure nobody is able to get AC with just more modulos.