


Hint
Tutorial
811B - Vladik and Complicated Book
Hint
Tutorial
Challenge. Can you solve the problem with n, m ≤ 106?
811C - Vladik and Memorable Trip
Hint 1
Hint 2
Tutorial
Challenge. Can you solve the problem with n, a[i] ≤ 105? Try to use the fact, that 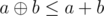 .
.
811D - Vladik and Favorite Game
Hint 1
Hint 2
Tutorial
Challenge. Assume this problem: let's change all dangerous cells on walls, i.e such cells, in which it is just impossible to enter. Now you have to generate such string from moves 'L', 'R', 'U', 'D', that without dependance on possible button breakage of pairs 'L'/'R' and 'U'/'D', as in original problem, will visit finish cell. Of course, it is not necessary to stop at finish cell, you just have to visit it at least once.
811E - Vladik and Entertaining Flags
Hint
Tutorial






Challenge. In problem A can U solve if a , b <= 10 ^ 18 ?
try to use binary search :DD
Can be done in
O(1)! It'd be awesome if someone finds out a hack case for this. 27416204
The hacking test is
443672224612562498 443672223946475251Answer:
Vladik(you can easily check this with a slow solution).Doubles often fail by precision, it's not recommended to use this. Casting everything to
long doubleor avoiding doubles would help.My answer is correct even for that "hacking test", it is below this comment.
Ok... How about this test?
286539999388964720 286539998853670410Answer is also
Vladik.You solution prints
Valera(I tried custom invocation).By the way, the generator is
Try to stress test your solution with this generator and see your code also fails by precision.
Problem A is O(1). Here is my answer.
sqrt function is O(1) ? how is that possible?
What is order of sqrt in c++?
May you please find a mistake behind a logic of my approach for problem C : 27416588
Oh, sorry, there is no question anymore, i found out a mistake, here is AC solution : 27416622
In probelm E,the tutorial is too short to understand,could anybody give more details about how it be solved? Thx :)
Let's say we have two segments A and B with endpoints [LA, RA] and [LB, RB] and LB = RA + 1. Let's also suppose we have three informations for each one of these segments: 1) how many connected components are there in it; 2) in which component every one of the n elements of the column Li is; 3) in which component every one of the n elements of the column Ri is.
Now, we may want to know these three informations for the segment C, which has endpoints [LC = LA, RC = RB]; i.e., C is the merge of the segments A and B. If we are able to do this merge correctly, then we can build a segment tree such that each node stores the three said informations for its range and thus get the correct information for any given range via the query function.
The segment C will have compA + compB - unionsAB connected components, where compi stands for how many components are there in segment i and unionsij for the number of unions made when merging segments i and j. For each line i of the n lines, we gotta union the components of the columns RA and LB if grid[i][RA] = grid[i][LB] and update LC and RC if some change occurred in the components of the elements in these columns.
Very nicely explained, thanks! I can see how to implement this solution using Segment Trees. The editorial, however, mentions Interval Trees, which I've never worked with before. Are these interchangeable words for the same data structure?
I don't know what a Interval Tree is, but this page says that it is a data structure similar to Segment Tree, so probably they are not the same.
Quite clear,thanks for you help! :)
When merging intervals A and B, wouldn't it be necessary to use DSU/union-find data structure? I think you would need a DSU per node in the segment tree. But then you would face the problem of merging DSU's, both for building the segment tree and for answering queries, which will yield TLE considering that there are q = 10^5 queries to answer. How can you solve that?
Take a look at this code. We can just naively merge two nodes in O(n2). Maybe a DSU approach would be even faster. I'm kinda lazy to do the maths right now but it should pass...
Explanations in the editorial are shorter than the corresponding problem statements
Another way to solve A:
We know that, Sum of first n odd numbers = n*n and sum of first n even numbers = n*(n+1).
Notice that Vladik always gives odd number of candies and Valera always gives odd number of candies.
If Vladik can gift n times, then n*n should be at least a, so, n = floor(sqrt(a)) . Notice that Vladik can't give right amount, if Valera can give gift at least same number of times, i.e. n times.
Now, to gift n times with even numbers, Valera needs n*(n+1) candies. If Valera has at least n*(n+1) candies, then he can gift n times, and then Vladik is first who can't give right amount of gifts.
Problem B for n, m ≤ 106 can be solved with AVL, there are another way for solve it?
You can solve it with merge sort tree and binary search too.
Code
Merge — sort tree Tutorial
Thanks!!!
Challenge: Solve each query in O(log n) time complexity. With Merge Sort Tree is it O(log2 n), in strict TL that will Time Out too :P
Like I said, AVL, it solve each query in , so with AVL, insertion time is
, so with AVL, insertion time is  and total query time is
and total query time is 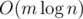 . Do you have in mind another data structure?, I don't know any other.
. Do you have in mind another data structure?, I don't know any other.
Isn't your code a segment tree that works O(log^2(n)) for a query?
https://discuss.codechef.com/questions/94448/merge-sort-tree-tutorial
Segment tre with Vectors AKA Merge Sort Tree has a query with complexity logn * logn (read in link above).
I solved B using, SQRT decomposition.
My submission: 27381506
Update: Previously, by mistake, I had given my submission link for A. Now fixed it. I didn't notice it earlier. Sorry for that..
That's not the answer for problem B, that's the answer for problem A!
I did it using Segment tree.
The time of problem B is O(n·m)???
For this problem n, m ≤ 104 so if n = m = 104 then the time would be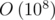 , that runs on 2 seconds???
, that runs on 2 seconds???
Rule of thumb :- On every major platform O(108) runs in about 1 sec. Except on Codechef, where sometimes it gets TLEd
Thanks!!!, I didn't know that. I was thinking that 106 or at most 107 runs in 1 second.
How can I know what's the maximum number of operations that runs in 1 second in any platform???
http://codeforces.me/contest/811/customtest
Just try code with simple operations with different
nso... what about this submission ? 26864037 It is complexity O(10 ^ 9) but get accept in 15 ms !!!
It's about -O2 magic. You can try a code with a 10^18 iterations on your computer and it will run in 0 sec.
Wow! Why does that happen?
The compilers are really clever now.
you can solve problem A in O(1)
by using this formula Sn = n/2 *(2*a+(n-1)*d)
n number of terms , a = the first element of series "1 for Vladik and 2 for Valera" , d= increment = 2
so the formula for count the number of term for
Vladik = n/2 * (2*1+(n-1)*2) = n(1+n-1) = n^2 = a so na = sqrt(a)
Valera = n/2 * (2*2+(n-1)*2) = n(2+n-1) = n^2+n = b so n^2+n -b =0 and solve it by quadratic equation nb = ( -1 + sqrt(1 + b*4) ) / 2
if (na <= nb) "Vladik"
else "Valera"
sqrt function isnt working in O(1)
For the challenge of D part . I have an idea with string of size atmost 4*n*m.
The idea is first just generate the string from start to final assuming all buttons are correct.Lets call s1.
Now assume (L/R) is reversed and simulate s1 from start to see which position it reaches.from that position generate a string which reaches final from it assuming broken (L/R) . Lets call this S.
Now concatenate s2=s1+S.
Now assume (U/D) is reversed and simulate s2 from start to see which position it reaches.from that position generate a string which reaches final from it assuming broken (U/D) . Lets call this S.
Now concatenate s3=s2+S.
Now assume (L/R) & (U/D) is reversed and simulate s3 from start to see which position it reaches.from that position generate a string which reaches final from it assuming broken (L/R) && (U/D) . Lets call this S.
Now concatenate s4=s3+S.
Now it must be visible that s4 passes through final for any possible breakings.
Can someone find a flaw in this??
Yes, my idea was the same :)
problem A can be solved in 0(1). http://codeforces.me/contest/811/submission/27385965
How to solve the challenge problem for problem C
Is it possible to solve E using SQRT-decomposition? I mean something like this (but I missed that spots can be splitted, so it is wrong anyway).
I think it's a bit too slow, O(N*M^(1.5)) is about 1e8, while the compiler could barely optimize the complex code.
3*10^8 to be accurate. I think it can suits in 2 seconds.
What is the meaning of this line , can anybody explain?
Assume, that there was such train carriage, that finished at position i. Then iterate it's start from right to left, also maintaining maximal ls, minimal fr and xor of distinct codes cur. If current range [j, i] is ok for forming the train carriage, update dpi with value dpj - 1 + cur.
So how to solve C for n, a[i] ≤ 10^5 ?
A lot of people (including myself) found the explanation for problem C hard to understand, so I thought I'd explain my solution.
Just like the official solution, we note down for each number its first and last occurrence.
Then we create an array dp, where dp_i will hold the solution to the problem, assuming we were only given i passengers to begin with. This means that dp[0] = 0, and then we iterate over the passenger list, for each passenger checking
Now, how do we get the new solution if we have a segment to process? We will keep track of two variables: the start of this segment, if it is valid, and its end. we iterate from where we were backwards to the start of the segment, and for each passenger we come across, we check that the last element of its kind is before our end (if not, then we'll check it later, i.e. this segment's end has to be moved), and we check where the first element of its kind is – if needed, we move our predicted start for this segment back even further.
If we manage to successfully iterate over the segment, then we need to calculate the needed XOR value for it, and then check if we get a larger final solution by adding dp[start of our segment] + our segment's XOR value, or by simply taking the previous dp value, dp[i-1], whichever gives us a larger result.
In the original solution I couldn't understand what happens if our new segment overlaps some other, smaller segment, but it is important to note that the dp value we add to our newly calculated segment's value, is the dp value for the problem BEFORE the elements of our new segment even began. We don't look at dp[i-1], we look at dp[beginning of our segment].
Sometimes it's easier to just go though someone else's code, so here's my final solution to the problem.
I tried solving C by making directed graph..but getting WA on test 26 https://codeforces.me/contest/811/submission/90333411 Please help.
Thanks man! Implementation
When n ≤ 104 I always assume that O(n2) shouldn't work. I'm surprised!
Would someone mind help me look at my code for Problem E? I suppose my code have a time complexity of O(N*(M+Q)*logM) with each merge action as O(N), but I suspect that I messed up part of the implementation thus causing TLE (is the bfs search too expensive for merging?).
http://codeforces.me/contest/811/submission/27392571
Thanks in advance.
I see that your solution is extremely non-optimized. Problem is not in bfs, but in vectors inside struct node. You shouldn't store all the edges this way, you can generate them on the run (checking if there is an edge when trying to bfs). For example, your code works 7 seconds in polygon, while this code works in 3 seconds (didn't pass in 2 sec too) (I just made edges in nodes global). This happens because dynamic memory allocation is too slow.
Challenge Div2C
Let dp[i] denote answer when we have created segments till 'i'.
We can construct a segment tree which can answer the following for a range [l, r] -
1. Maximum of last occurrences of the elements in the range [l, r] -> Q(l, r).last
2. Minimum of first occurrences of the elements in the range [l, r] -> Q(l, r).first
3. XOR of the elements whose last occurrences lie in [l, r] -> Q(l, r).ans
For a valid segment, Q(l, r).first = l & Q(l, r).last = r. So we are checking at those indices only where Q(l, r).last = r. And if Q(l, r).first != l, then we need to change 'l' to atleast Q(l, r).first and then again check the condition.
We can save the optimal index for 'l', which will bring the overall complexity to O(nlogn).
Solution
Problem C dfs solution
http://codeforces.me/contest/811/submission/27572002
Description:
My O(n) solution for problem C... Since I'm a beginner in dp (and English So I just implement my own thoughts.. and then I get the code blow.. http://codeforces.me/contest/811/submission/29330084
Problem D is so bad.