


5 сентября стартует 1/4 чемпионата мира по программированию! Всем удачи. Здесь предлагаю обсуждать организацию, задачи и просто спамить)
→ Обратите внимание
До соревнования
Rayan Programming Contest 2024 - Selection (Codeforces Round 989, Div. 1 + Div. 2)
12:57:04
Зарегистрироваться »
Rayan Programming Contest 2024 - Selection (Codeforces Round 989, Div. 1 + Div. 2)
12:57:04
Зарегистрироваться »
*есть доп. регистрация
→ Лидеры (рейтинг)
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3993 |
| 2 | jiangly | 3743 |
| 3 | orzdevinwang | 3707 |
| 4 | Radewoosh | 3627 |
| 5 | jqdai0815 | 3620 |
| 6 | Benq | 3564 |
| 7 | Kevin114514 | 3443 |
| 8 | ksun48 | 3434 |
| 9 | Rewinding | 3397 |
| 10 | Um_nik | 3396 |
| Страны | Города | Организации | Всё → |
→ Лидеры (вклад)
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 155 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 10 | djm03178 | 152 |
→ Найти пользователя
→ Прямой эфир






Codeforces (c) Copyright 2010-2024 Михаил Мирзаянов
Соревнования по программированию 2.0
Время на сервере: 30.11.2024 04:37:57 (h2).
Десктопная версия, переключиться на мобильную.
При поддержке

Первый вопрос: Есть ли расписание мероприятий в Луганске и где предполагают поселятся участники?
Согласно приглашений, полученных 23.08.2012, по Центральному региону (Сумы) расписание таково:
05.09.2012, 15:00: открытие, жеребьёвка
05.09.2012, 16:00: пробный тур
06.09.2012, 10:00: основной тур
06.09.2012, ориентировочно 18:00 но гипотетически может изменяться в зависимости от текущей ситуации: награждение и закрытие
Насколько понимаю, пробный и основной туры неминуемо одновременно по всем регионам.
05.09.2012, 16:00: пробный тур 06.09.2012, 10:00: основной тур
Извините, возможно, это глупый вопрос, но что представляет в данном случае жеребьевка и зачем она нужна?:)
Для распределения команд по компьютерам и аудиториям.
Открытие только что началось
Где можно будет online поболеть за команды?
думаю тут, или тут можно будет.
Пока что ни там, ни сям не доступно :(
И организаторы молчат...
Будем надеяться, что кто-то осведомлённый откликнется! :)
Похоже, что онлайн-результаты тут
Был весьма странный проблемсет. 3 задачи, которые мы пихали, но так и не допихали, выглядят вообще элементарными, при этом входят они довольно случайным образом у разных команд (могут входить у довольно средних и не входить у очень сильных). Что ещё больше озадачивает, те, кто сдали эти задачи, делали то же, что и мы.
Задачи C, E, G ? Отпишитесь, плиз, когда выясните в чём дело!
Мы пытались сдавать 3 разных трактовки задачи Е и только последняя зашла дальше 1 теста. Причем, как по мне, они все подходили под условие.
А какая трактовка в Е правильная?
Нужно найти количество способов выстроить в очередь именно те k человек, которые даны в начале инпута. Люди, которые не встречаются во входных данных, вообще на ответ не влияют.
Саме те, на чому ми отримували ВА. Шкода, трішки не хватило часу, щоб здати "правильний" розвязок.
именно так и было у большинства тех кто получал ВА по Е
C ещё ладно — там тайм лимит 0.5 (Внимание, вопрос: зачем? Автор знает решение за n^2 или ждал именно оптимальные n^2 log n?) и при наличии времени можно было её впихнуть. Но с остальными двумя — ВА и это вводит в ступор. Ещё больше удивляет 3 аксепта по Е (наверно, она всё-таки решалась персистентной дучей по неявному ключу или минкост-максфлоу на суффиксном дереве, а наивные люди какие-то цепочки строили, факториалы считали...). С G тоже не понятно — команды с отличными математиками имеют по ней минусы, а с первой попытки её вообще никто не сдал. Такое ощущение, что оригинальные задачи оказались слишком простыми (так и есть), более сложных не нашли или не захотели искать и поэтому для усложнения в условие был заложен дополнительный скрытый смысл, который обнаруживается только при тщательной вычитке.
Просто во всех задачах есть вырожденные частные случаи и т.п. Нужно было аккуратно все рассмотреть или написать брутфорс и сверить с ним свое решение на рандомных тестах.
Насчёт C: я (автор) решения более быстрого чем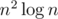 не знаю, но мне удалось построить совокупность оптимизаций, с которыми всё укладывается где-то в 0,170 сек; а совокупность оптимизаций, с которыми всё укладывается в 0,300--0,350 сек, как по мне, относительно простА. Вот если б таки появились именно на эту задачу решения на джаве, было б стрёмно.
не знаю, но мне удалось построить совокупность оптимизаций, с которыми всё укладывается где-то в 0,170 сек; а совокупность оптимизаций, с которыми всё укладывается в 0,300--0,350 сек, как по мне, относительно простА. Вот если б таки появились именно на эту задачу решения на джаве, было б стрёмно.
UPD: а все ли, кто говорит, будто у них не прошло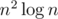 , уверены, что их решение ни на каких входных данных не превращается в n3?
, уверены, что их решение ни на каких входных данных не превращается в n3?
Есть такое мнение что ТЛ менее 2 с, а так же дробный ТЛ — зло. Всегда можно чуть-чуть увеличить ограничения (и таки при этом проще будет отделить куб)
Я с этим почти согласен, но не согласны люди, организовывающие техническое обеспечение :( По их мнению, необходимость делить проверку между несколькими серверами — бОльшее зло, чем time-limit-ы в 0,5 сек.
Вот объясните мне, за что минуса!
За то, что поставили time-limit втрое выше авторского решения? Или за то, что он всё равно маленький? Или минусуют меня за то, что команда технического обеспечения не считает целесообразным делить проверку между физически разными компами? Или за то, что я сделал задачу, в которой участник очень даже может думать, будто написано решение за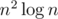 и не видеть что оно на самом деле за n3?
и не видеть что оно на самом деле за n3?
Контрпродуктивная ситуация, причём уже не первый раз: только напишу что-то по результатам тура где играли мои задачи, так сразу одновременно и минуса и отсутствие конструктивной критики (во всяком случае в плане того, что мог бы сделать я сам, а не команда технического обеспечения).
Ну давайте я уйду из всего этого, и увеличится процентное соотношение задач авторов, которые пихали в тесты лишние слэши (на прошлогоднем финале Украины & SEERC) и совершенно по этому поводу не парились, может так всем будет лучше.
Я надеюсь, ваши оптимайзы с такими же запасами и на Джаве заходят?
Немного конструктивной критики. Насколько я понял из Вашего поста, решения на Джаве по задаче С проходить если и должны, то впритык (если я Вас неправильно понял, простите). Это не очень хорошо, учитывая, что Джава — официально используемый язык АСМ и решение на нём должно существовать.
А ещё я утверждаю, что я писал именно n^2 log n (не очень оптимально, но всё же) и получил ТЛЕ.
Посудите сами: отсортируем массив весов и массив рёбер (n^2 log n), рёбра создадим без дубликатов, т.е. их до 500000. Для каждого ребра (n^2) вершины, инцидентные ему (n^2), запихнём в вектор, соответствующий весу этого ребра (изначально заведён массив из 10^6 векторов, lower_bound (n^2 log n) ищет первое вхождение веса ребра в массив весов и говорит, что вектор с таким же индексом отвечает за этот вес), затем добавим все рёбра (каждое ребро — не более раза, а значит суммарно n^2) с текущим весом в граф и запустим dfs только от вершин в текущем векторе (так же суммарно n^2). После того, как запустили dfs, почистим вершины, которые находятся в текущем векторе (а значит, ребра не накапливаются с одной стороны и мы проходимся по каждой вершине ровно столько раз, сколько рёбер ей инцидентно с другой стороны).
Я не снимаю с себя ответственности за неоптимальность кода — слишком много добавлений в векторы, можно было использовать 1 вектор вершин, а не 10^6, можно было сортировать рёбра в каждом списке инцидентности, а не глобально (увы, времени оптимизировать особо не было — ещё 2 задачи висели), но на асимптотику это не влияет, а именно она у Вас вызывает сомнения.
Я конечно сторонний участник дискуссии, потому что на контесте не был и эти задачи не решал, но кажется немного подозрительной фраза "... но мне удалось построить совокупность оптимизаций ..." из этого следует, что было написано решение, а потом оно просто нахачивалось. Делать таким образом задачи не очень хорошо, хотя бы потому что почти в любой задаче можно взять решение которое работает 2с и нахачить его так что оно будет работать 100мс и после этого поставить ТЛ 250 мс.
Контест мне тоже не понравился, задачи собирались спехом, галопом от разных авторов, разного уровня профессионализма авторов, не вычитывались, не проверялись. Контест не сбалансирован, вообщем из года в год ситуация как по составлению задач, так и по организации контеста не меняется.
Я вчера лично разговаривал с девушками из ОНУ, юнаками зі Львова и с братьями Соболевыми, так уровень проведения второго этапа страдает, а в случае, как сказал Дима, Луганска, так хуже провести было просто невозможно.
Но зная что за всем этим стоит т.Мисюра и зная, что его уже давно пора списывать на заслуженный отдых, так как он не справляется с требованиями к мероприятиям такого уровня, то призываю, просто заклинаю все команды, которые попали в топ 20 ехать только в Бухарест, голосуем против Винницы ногами, собираем деньги и едим туда, где организация более-менее.
И еще давайте вместе поищем, попросим, подумаем над тем кто у нас в Украине смог бы организовать все так, чтобы задачи были достойны и интересны, уровень организации не страдал, организаторы хотели и могли бы сделать праздник, чтобы было не стыдно туда пригласить иностранные команды и спонсоров, неужели на Украине нет таких людей? Надеюсь, что есть!!!
"Я вчера лично разговаривал... с братьями Соболевыми"... Насколько я знаю, Дмитрий Соболев в данный момент находится на стажировке в Facebook. Вы ведете репортаж из Америки?..
Да, Дрюк он и в Луганске Дрюк! Ну и зачем было палить отличную команду из-за того, что они писали без Димы, а теперь их дисквалифицируют и не допустят к финалу.
Какой фееричный бред..
Народ, перестаньте кормить тролля.
Хм. Вы можете назвать хотя бы одну команду, которая была дисквалифицирована по этой причине за последние N лет?
А есть ссылка на монитор?
Борд
А у меня тем времнем вопрос к участникам, ни кому задача J не показалась знакомой? Не могу вспомнить, где видел что-то похожее...
Где можно достать условия задач?
Здесь
А где-нибудь можно порешать этот контест?
p.s. может кто-нибудь добавит в тренировки, если у него есть тесты?
AWPRIS то ли договаривается то ли уже договорился получить полный комплект тестов и провести зеркало этого соревнования на e-olimp.com.ua Только вот когда оно будет...
e-olimp — это хорошо, но тренировки на Codeforces — предпочтительнее, т.к. их может запускать каждый в любое время, а на означенном сайте такими возможностями обладают только руководители групп. А ещё у господина Присяжнюка есть удивительное мнение о том, что перед соревнованием и зеркалом стоят разные задачи, авторское решение не обязано проходить в ТЛ и если по задаче нет чекера, то участнику следует угадать решение автора. Вкупе с не очень быстрым сервером это порой создаёт задачи, которые надо оптимизить часа 3.
Расскажите кто-нибудь как решать D и F, пожалуйста. По поводу задачи D — буду рад, если кто-нибудь еще и условие полностью обьяснит.
Задачу F можно решить при помощи БФСа. состояние — где мы можем сейчас находится. поэтому состояний максимум 2^(n*m). Ну и чтобы быстро совершать переходы по командам D,L,R,U нужно воспользоваться битовыми маскам (что-то похожее на http://codeforces.me/problemset/problem/97/D ). Чтобы ответ был лексмин, в очередь нужно класть сначала переход по D, потом по L, R и U. В итоге сложность при аккуратной реализации получится порядка 2^(n*m)*4
Спасибо, понятно.
Кстати, мне одному кажется, что из условия задачи F неочевидно, что выводить в случае, когда есть только стены? С одной стороны, выходов нет, достичь их нельзя, поэтому NO SOLUTION. С другой — стартовать тоже неоткуда, поэтому никуда идти не надо и ответ — пустая строка. Мне кажется, что либо условие задачи двусмысленно, либо такой тест некорректен.
Задача D.
Условие. У нас изначально есть куб. Просто единичный куб со значениями только в вершинах, равными 1. На каждом шаге мы все имеющиеся у нас кубы делим на 2 по каждой координате — итого на 8. При этом у новообразовавшихся вершин значение получается из суммы "соседних". На самом деле, если соседних изначально не было, то это или сумма 4х чисел в углах грани (если новая вершина ставится в центр грани), или сумма всех 8и вершин куба ( если ставится в центр куба).
Найти сумму всех получившихся чисел после n разбиений.
Решение.
Из ограничений довольно ясно, что придётся возводить матрицу в степень. У нас была матрица 4*4. Эти 4 координаты — сумма элементов в углах исходного куба, на рёбрах, на гранях и внутри соответственно. Матрица переходов получилась такая:
Уже после контеста я вывел формулу, дающую тот же ответ: (3n + 1)3.
Оффтоп: похожее было в задаче A раунда 118, где одни люди возводили в степень матрицу, а другие — двойку. Нет ли какого-нибудь общего алгоритма, заменяющего возведение матрицы в степень с последующим умножением на вектор и поиском суммы элементов результата на возведение в степень числа или матрицы меньшего размера (возможно, с какими-то константными операциями)
Спасибо, буду разбираться.
По поводу условия. Там есть такая строчка "We will split the cube into 8 equal cubes and assign to new vertices numbers equal to the sum of numbers in adjacent vertices." Для меня както не очевидно, почему из нее не вытекает, что значение в центре верхней грани первоначального куба зависит не от всех значений на серединах ребер этой грани.
Похоже, тут имел место случай (не очень уж редкий, особенно, если язык условия — не родной для автора и/или контестанта), когда эффективнее не разбираться в тексте условия, а посмотреть на сопровождающие рисунок+input+output.
Для того они и приводятся!
Минусующие — хотите сказать, что вам такие задачи не попадались? ;)
Да, есть. Но не всегда это реализуемо на практике.
Допустим, имеется рекуррентность f(n) = a(1) * f(n-1) + ... + a(k) * f(n-k). Составляем характеристическое уравнение заменой f(m) -> q^m: q^n = a(1) * q^(n-1) + ... + a(k) * q^(n-k) или q^k = a(1) * q^(k-1) + ... + a(k). Получаем уравнение k степени с корнями q_1, q_2, ..., q_k, c учетом кратности и комплексных корней. Если все корни различные, общее решение рекуррентности выписывается в виде f(n) = c(1) * q_1 ^ n + c(2) * q_2 ^ n + ... + c(k) * q_k ^ n, где c(i) определяются из начальных условий. Другие случаи рассмотрены здесь http://en.wikipedia.org/wiki/Recurrence_relation#Solving.
Применение на практике — если повезет с корнями характеристического полинома. Например, для чисел Фибоначи f(n) = f(n-1) + f(n-2) корни иррациональны и точный ответ с использованием формулы получить непросто. http://en.wikipedia.org/wiki/Fibonacci_number#Closed-form_expression
Для этой матрицы можно было легко перейти к степеням, потому что она получилась треугольная, а значит ответ можно представить в виде линейной комбинации степеней элементов на диагонали. Т.е. если на диагонали стоят b1, b2, ..., bm, то характеристический многочлен будет равен (x - b1)(x - b2)...(x - bm), и поэтому an = c1b1n + c2b2n + ... + cmbmn.
А я кину камень в огород организации...
А кто как различал фигуры в задаче А?
С помощью хеша. Мы использовали степени 3-ки.
Мы тоже хешировали, хотелось бы и другие способы узнать.
Ну, действительно получалось, что одновременно и по времени работы программы, и по затратам на её написание, трудно найти что-то лучшее, чем хэши (с частичной, не до конца честной проверкой при коллизиях). Правда, это всё же действительно спокойно и уверенно только за счёт возможности многократной сдачи — если последствия неправильного учёта коллизий таки проявятся, можно пересдать с друг(ой/ими) хэш-функци(ей/ями).
А ещё альтернативные способы, которые абсолютно гарантированно правильные:
1 этап. при обходе фигуры в ширину/глубину получить некоторое "слово" (или из относительных координат клеточек, или из последовательности в стиле "пихнули в очередь направление вниз, пихнули в очередь направление влево, закончили рассмотрение всех соседей текущей клеточки, ... ... ...")
2 этап, 1 вариант. Пихать эти слова в котейнер set. Может казаться, будто тут одновременно и дорогое сравнение строк, и большое количество фигур, и ещё накладные затраты на сам set (логарифм с большИм константным множителем). Но на самом деле суммарная длина всех строк ограничена размерами поля, посему они не могут быть одновременно и очень длинными, и в очень большом количестве. Так что подобные решения пропихиваются относительно легко, а если ещё сравнивать строки сначала по длинам, а потом уже для одинаковой длины лексикографически, то всё вообще гарантированно получается.
2 этап, 2 вариант. Пихать эти слова в рукописный бор (trie). Хотя теоретически это решение должно бы быть асимпотически лучшим всех рассмотренных ранее, на практике оно почему-то немножко даже проигрывает. Но тоже сдаётся.
По поводу коллизий мы долго не думали, 2ой хеш вполне хорошо сработал. А за 2 альтернативных варианта спасибо.
А какой там был МЛ? Довольно глупо, что я не мог взять еще один массив размером со входные данные, из-за чего получал МЛ 14-15 тест.
Довольно странно, потому что в кларах было написано, что на все задачи МЛ 256Мб.
По каким-то загадочным причинам решения, у которых было переполнение стека, получало МЛ. По крайней мере с нашим решением было так. Мы убрали все сеты, большие лишние массивы и т.д. и локально решение потребляло максимум 20 метров, но оно не проходило, пока мы не заменили рекурсивный дфс на нерекурсивный.
А как, собственно, должен отображаться участнику stack overflow? Признаюсь, что именно этот вопрос я как-то до сих пор пропускал мимо внимания. Впрочем, и на этом туре от меня это вроде бы никак не зависело.
И, разве совсем уж нелогично и неожиданно выглядит, что рекурсия глубиной более миллиона таки ломается? 14-й тест был 1162*1226, примерно 77% клеточек звёздочки:
15-й тест — 1206*1153, аналогичным образом обеспечено что примерно 98% клеточек звёздочки. Неужели в этих тестах есть какой-то хитрый и неожиданный подвох???
Ну вроде как везде Stack Overflow это Runtime Error
Это везде по-разному и вообще трудноуловимо, т.к. нужно правильно интерпретировать сигналы. Например, на КПИ-Опен под МЛЕ скрывался выход за границы массива.
А кто-нибудь знает, как решалась задача J (про мат. ожидание количества точек попавших в круг)?
По идее, должен знать ее автор, Виталий Неспирный;)
Очень бы хотелось почитать авторский разбор задач (если это вообще возможно).
У меня была идея рандомно выбирать 3 точки и считать ответ за O(n) на протяжении 2х секунд. Дело в том, что в задаче ответ нужно вывести с точностью до сотых. Поэтому по ЗБЧ возможно бы и зашло, хотя я далеко не уверен в этом. Ничего другого в голову больше не пришло. Но руки не дошли написать это, мы Е пытались сдать.
Не, рандом — это от лукавого;)
Мы в последние 10 минут написали это и получили ВА 7.
Быстро написанный чекер ошибается даже в знаках перед запятой;)
P. S. т. е. если эту программу запустить два раза, то будут сгенерированы два одинаковых набора точек, а ответ будет отличаться.
Вот на этом контесте задача H совпадает с задачей J с данного контеста.
К сожалению, видео-разбора быстро не смог найти, но совершенно точно помню, что задача решалась формулой (все доказательство было в некоторой статье), в которой использовалось количество выпуклых четырехугольников, которые можно построить на заданных точках. А количество выпуклых четырехугольников — это тоже известная задача, была и в Петрозаводске и на зимней школе в Харькове.
http://icpc.baylor.edu/public/worldMap/reservationList.icpc;jsessionid=028C66953D9EFC10F329B0E028190381?contestId=1326
Я только что посмотрел список зарегистрированных на румынский полуфинал и у меня возник вопрос, почему им можно регистрировать по 4 команды от университета(например Babes-Bolyai University), а на украинском полуфинале действует жесткое ограничение не больше 3 команд от вуза, почему украинские правила жестче мировых? опять чувствую руку т.Мисюры!
Кто вчера участвовал в финале 2й лиги в Харькове? http://ejudge.hneu.net/ Подскажите, пожалуйста, какой-нибудь логин/пасс для дорешивания
Где можно посмотреть условия и результаты?
http://olymp.hneu.net/new/ — вот сайт.
Собственно условия задач
На всякий случай прорекламируюсь, что тут есть ((ссылка на разбор) и (обсуждение) задачи F)
А как, собственно, решается I — о сумме остатков?
Остатки при делении числа N на числа от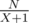 до
до 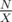 , где
, где 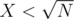 , формируют арифметическую прогрессию. Так что нужно было быстро просуммировать
, формируют арифметическую прогрессию. Так что нужно было быстро просуммировать  последовательностей.
последовательностей.
И потом, наверное, прибавить остатки от деления на первые sqrt(N) чисел. Благодарю.