


Hello, Codeforces community!
Codeforces Round #384 for the second division will take place on Wednesday, 14 December 17:35 MSK. Traditionally, first division participants will be able to take part out of competition.
Round was prepared by Yury hloya_ygrt Shilyaev and me, Kirill kefaa Gulin.
Many thanks to Nikolay KAN Kalinin for his help with the contest preparation and Mike MikeMirzayanov Mirzayanov for the Codeforces and Polygon systems.
You will be offered 5 problems and 2 hours for solving them.
Scoring will be announced closer to the beginning of the round.
UPD: Scoring is 500 — 1000 — 1250 — 2000 — 2500
UPD2. The contest is over! Hope you enjoyed it :)
Congratulations to the winners!
Div2:
Div.1:







Good look all participants!!
Why we can't see this announcement at the homepage. And why writer's name is missing at the upcoming contest list? Just asking :) BTW thanks for preparing the round. Hopefully everything will be alright (no long queue and fast rating update) :)
UPD: The announcement is now available at the homepage.
For those who gives me negative vote, please let me know how can I improve my previous comment? Normally we can see the announcement at the homepage and every contest has its writer's name at the contest list. Thanks in advance :)
Actually, it takes a while to get the annoucement to the homepage and the same thing for the contest list.
Thanks :)
bekarsan e ətağa
Is it rated?
yep.. it's rated.
-48 votes?? I think we are being quite rude here. This person has participated only once! It might not be obvious for newcomers. This much hostility makes the community unhealthy for beginners.
Newcomer? OK then he wouldn't even know that unrated rounds even exist :D BTW, Nice rating for a newcomer :D
Contribution is even nicer!
i hope the problems statements will be short like this announcement and less hacking
Why less hacking?
because hacking system is not fair , you can be in the room where most of the room solve the problem wrong and you make a lot of hacks on the other side in another room all people solve the problem right is it fair ?
Life is so unfair, my friend.
sure my friend , but we have to make this community fair as we can
In my opinion, it's because that CLEAR and CONCISE programming is discouraged. Also, not every programming language is understandable. Coding in really difficult languages (brainfuck) is also encouraged.
Actually , no.
See Contest rules , Can-do's and Can't-do's , Point no. 3
" It is forbidden to obfuscate the solution code as well as create obstacles for its reading and understanding. That is, it is forbidden to use any special techniques aimed at making the code difficult to read and understand the principle of its work. "
The idea is to subject your code to a jury of your peers , who have all shown confidence in their code (by locking it).
The guiding reason behind it is that you are expected make the logic of the code so infallible that it simply cannot be hacked , and not deliberately obfuscate code , which is against both the spirit of the competition and the rules.
It is the objective of the writer to write perfect , legible code. It is the objective of the hacker to expose flaws in that code.
I think you want more hacking: wrong solutions in every room.
So much for "less hacking"... there are 40 pages of hacks: http://codeforces.me/contest/743/status (EDIT: select "Verdict: Hacked" on the right side panel)
Please include some hints for the problems in the editorial like in the editorial for the previous round
they are really helpful
Well, long time no cf. I would love to take part into this round. Wish me scores increasing!Haha
Unusual time!! Yayy!! Codeforces is back...I missed you. Unusual is the new usual :D
Am I the only one here thinking that this round features the same writer of round 321 (which has all questions named after kefa)
i cant get you
I think they should have mention it in announcement (is it rated or not). Because most of the registrants are new and they don't know that each round is rated(If it is not mentioned explicitly ). Otherwise freshers will keep asking, whether its rated or not and they will keep getting negative votes. I am sure that i will also get negative votes for this comment for no reason.
Usually a regular round is rated. So, in my point of view it's unnecessary to mention if the round is rated. But in case the round is not rated then it's necessary to mention it. And newcomers should read the FAQ before participating. Thanks :)
My sister once signed up for a codeforces account to try out competitive programming and stopped 1 year ago. Yesterday when she received an email about this round she asked me: "why do your codeforces contests always start at an unusual time"
Tell her because it's the new usual.
Three rated rounds in one week, how unusual!
Three rounds in one week! That's the spirit!
2 hours, 5 Problems the traditional Codeforces Rounds are back!
Tomorrow I've 2 exams! but I can't read now, because excited about CF :D
I just came after having a horrible exam, but yeah it's codeforces round so happy enough.
:D I had a xm today also!
You'll get the exams! Participate in the contest and don't worry! :)
Some people worries in exam result. Some are just more worried in rating change result
I'm not worried abt the xm result or the rating change :D I just love doing contest B-)
Am I the only one who can't do anything in the few moments just before every contest ?
I've been sitting here for the past 15 mins staring at the contests page.
Notice anything unusual about this screenshot?
Right after hack it was like
Pretest passed
Running on test 8
Hacked
Волшебный талант "Хакер решений"
и ты плюсов хотел?
Great contest!!!
Maximum fun from problem C )
Approach for problem E?
if you fix the minimum frequency , then you can calculate the answer in N*2^8 using dp with state(position , mask) , so now just do a binary search to find max posible frequency. Total complexity N*logN*2^8
At first we can list all of the length t, which means that each digit can appear t or t + 1 times. Then we need to figure out the longest subsequence, so we can use dynamic programming to do this. Let dp[mask][i] mean the leftmost position for us to consider the next digit when we now have filled the digits set mask, and we have i digits whose length is t + 1. We can choose a digit not in mask and greedy choose the next position, which can be processed in O(n2) time at the begin of the program. Thus the whole algorithm is O(8n2 + 8n * 28).
UPD: We can also binary search t to speed up the algorithm into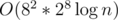 . And if n = 106, we can use binary search in vector to greedy get the next position, in this case the whole algorithm is
. And if n = 106, we can use binary search in vector to greedy get the next position, in this case the whole algorithm is 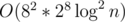 .
.
i tried making D[k][i][j] — first position where ends finding j elements of type k from position i after that, for each permutation of the subset ( 0 -> 8 ) i try to find best solution, hard to explain, i finished the solution right when the time ends, the solution is correct but not sure if it fits in time
i think i found a solution in O( N^2*8 + 8!*8*log(n) + 8!*2^8 ) precalculating D[k][i][j] — from position i to D[k][i][j] are j elements equal to k. With that precalculated bs the answer making all permutations and checking every combination if its valid in O( alphabet = 8 ). After we find the respective number, we can check which elements will appear lenght+1 times in the final answer in O( 8! * 2^8 ). I implemented this solution with linear searching instead of bs and it works pretty fine: 68ms http://codeforces.me/contest/743/submission/22980164
Sorry for bad english
Hack fiesta with 1 on problem C :)
How to solve A?
Let the binary string be s (1-indexed). Then if s[a]==s[b], then answer is 0, else it is 1.
I am an idiot.
0 if the companies in A and B are different or 1 otherwise.
Well just print 0 if value at a and b are the same. Otherwise is 1. Because if value at a and value at b are different, you have to get to the next airport if the next one is same as b you travel right away to b so cost 1, on the other hand it will cost 0.
That feeling when you find a mistake in your A solution just after you lock it. :'(
And hacking streak after that.
That feel when you don't understand the answer is 1 when the companies are different and instead find the nearest airport to airport B of the same company as airport A.
I did the same thing!
cost me 3 wa
Worst contest of my life ;_; . Got killed by A ;_;
Good problems (y)
3 more minutes and I could've at least submitted D ;_;
problem c
read problem D wrong twice.. thought one would take before another and write ~100 lines for tree dp...
D should have a test case with all negative pleasantness.
Why? The question did not state maximum non-negative pleasantness.
Hack Festival!@#(@($*!@(#!@
For Problem C:
if (n==1) answer = -1;
else
numbers are (n) , (n+1) and (n*(n+1))
Proof?
1/n + 1/(n+1) + 1/n(n+1)
= [(n+1)+n+1]/n(n+1)
= 2(n+1)/n(n+1)
= 2/n
Don't work when n=1 because n+1 = n(n+1)
1/n+1/(n+1)=(n+1+n)/(n(n+1)). Then, 1/n+1/(n+1)+1/(n(n+1))=(2n+1+1)/(n(n+1))=2(n+1)/(n(n+1)). Cancelling n+1, we get 2/n.
Can anyone tell me how to do D?
This is my logic, but didn't get to submit
First, sum all values in a subtree, and store in a sum array.
Then, do a DP on each vertex and find the max value you can get from this subtree, using values from sum array.
Then traverse the tree again and take 3 global variables with you : v1=-inf, v2=-inf, v3=-inf. V1 holds the max value of two subtrees( we'll use dp table from before ). answer is v1, if all v1,v2,v3 are > -inf.
v2 and v3 are the two values we took to make v1.
Why did you even get downvoted? This is a pretty solid explanation.
For every node you can store the sum of pleasantness of its subtree with DFS. Let's call this value P[node]
Suppose two nodes u and v, these nodes can be paired if u is not an ancestor of v and vice-versa.
You can traverse the tree and, for every node u find another node v which is neither an ancestor nor a children of it, with maximum P[v] and update the final answer.
I think there are several ways to find that node quickly, I used Range Maximum Query with Segment Tree.
The last part of I_love_Captain_America solution can be solved using segment tree too. During traversing we can mark each node by it's start and end time. Now all the node of a sub-tree will fall into a range [start time,end time]. If we take this node for Chloe we need to choose another non-intersecting sub-tree for Vladik. We can take the sub-tree from range [1,start time — 1] and range [end time+1,n] except the nodes fall in the path from root to current node. To exclude the nodes from root to current node we can update it's value with a large negative number at the beginning and rollback to it's actual value at the end. You can look at my submission for better understanding.
Confused why I got downvoted. I got AC with that method, although didn't need v2 and v3. lol
How to go for Div-2 B
cin>>n>>k; n=n-1; x=n+1; y=power(2,n); while(k!=y) { k=k%y; y=y/2; x--; } cout<<x;
Test Case 11 for Problem D? Any ideas?
Problem A was just made for hacking..any solution where you do not see
if(s[a-1]!=s[b-1]) cout<<1; else cout<<0;was hackable.
And C was googble :(((
what was i thinking...
How to approach question D ?
Hint: DP on tree
it can be solved in a greedy approach too
What should be the approach to solve Div2 C (assume that you know nothing about Egyptian fractions). I formed equations, tried solving them, but was not able to solve :(
Example case 2 is your friend , personally i think this problem is too mathematic.
Couldn't agree more. I wrote so much equations but nothing matched. Then i did stress testing to find some pattern but i failed there aswell, and whole time i was thinking that case 1 and 2 are just baits..Lost so much time on it..
2/n = 1/n + 1/n
So, n is x.
1/n = (n+1)/(n*(n+1)) = 1/n+1 + 1/n*(n+1)
I didn't know about Egyptian fractions! I wanted to find some pattern and suddenly it came to my mind! And the 2nd test case helps a lot to solve this problem.
I did not had any idea about Egyptian fractions so tried the following method. I ran 3 loops for x,y,z, with upper limit 200...after checking for small values of n, I found that the solution will always be
nn+1n*(n+1). I put these values in the expression. And found it to be true.It is logical that for any number 2/x, it can be divided into 1/x + 1/x
So first number is x.
Now we have to split 1/x into two parts (1/y and 1/z) such that sum = 1/x.
Observation: x/x+1 * 1/x = 1/(x+1) -> we pick such a division to get 1 in numerator
Therefore we can divide the remaining 1/x into 1/x+1 + 1/(x)*(x+1).
For example, 1/3 can be divided into 3/4 and 1/4 parts, 3/4th of 1/3 = 1/4, and 1/4th of 1/3 = 1/12. So answer for 2/3 = 1/3 + 1/4 + 1/12
And you realize all this and fail on n=1...I Hate my life.
I didn't know about egyptian fractions. My approach was heavily influenced by example 2, which was n=7, sol: 7,8,56. Using this example, I proved that n, n+1, and n(n+1) always works.
You can run a brute force to generate all solutions for a particular n and notice that a solution of form n, n + 1, n(n + 1) always appears. You can now prove that it works for all n by simple algebra and go for it.
First, I thought that 2/n looks a bit weird and it is worth to remove 1/n from 2/n (put x = n). The remaining equation looks much simpler: 1/n = 1/y + 1/z. If you look at the examples or try to guess yourself, you will notice that 1/2 = 1/3 + 1/6; 1/3 = 1/4 + 1/12 etc. Then you can realize that 1/n = 1/(n+1) + 1/(n(n+1)). So, y = n+1, z = n(n+1).
Otherwise, you can just rewrite simplified equation like follows: 1/n — 1/y = 1/z (y-n)/yn = 1/z All you need to get a solution is to set z = yn and y-n = 1 — which gives you the same as above.
And, of course, notice that y and z should differ — so n = 1 is a special case. Actually, maximum value of 1/x + 1/y + 1/z we can get with pairwise different x, y, z is 1/1 + 1/2 + 1/3 = 11/6 which is less than 2/1 — so for n = 1 answer is -1.
Initially I also formed equations and starting thinking of LCM of x,y,z . But then it was too much of trouble so I gave up that approach and started thinking from scratch. Following is what I next thought: Think of 2/n as 1/n+1/n . Then by observation , 1/n can be written as 1/(n*(n+1)) + 1/(n+1) so write any one of the two (1/n)s as 1/n*(n+1) + 1/(n+1). Thats pretty much what i did. Took me 45 minutes to see this . But then in the end my solution got hacked in the last minute (and i could not correct it in that less time)because there was one edge case here(n=1 ; ans would be -1 for this case). Hope this explanation helps.
I didn't even think that it could be solved with a formula :( I used brute force. The idea is:
When contestants in TOP 20 submitted A and C after E, and almost everybody has additional points for hacks you know that it was a good contest :)
I didn't get hacked on A or fail system tests, but can someone tell me what was the hack on A?
Something like this:
Can you explain what people did wrong to get this wrong?
If
s[a] != s[b]they were looking for i, j:So for test
Ah, ok thanks a bunch!
Read this
Some of the test cases I used are
12 6 12
101010111000
9 4 9
101000111
Did this ever happen to anyone else? My submission for problem C was treated as 3 distinct submissions and I got penalty for 2 re-submissions. Generally, Codeforces doesn't allow same code to be submitted multiple times but this ignored that rule too.
Wasted a lot of precious time figuring out C! If not, could've hacked more solutions of A! :(
Nevertheless, a good contest allover! :)
waiting for rating ...
rating is lating ...
This was the best round except my performance. No waiting queues. Fast system testing. Problems were too good. _/_
In Div2 D I couldn't understand if all the gifts have negative values then why not the answer is 0 as they want to maximize the pleasantness and hence both will not pick so answer should be 0 rather impossible.
you have to pick something, thats the given condition
Completely missed this!!My bad!
Why this submission AC....Data set very WEAK....
743B - Chloe and the sequence
22968117
This Submission hack for test case: 9 8541
see the constraints 1 ≤ k ≤ 2n - 1
http://codeforces.me/contest/743/submission/22961619
This code generates correct answer for pretest 8 on my machine but not on codeforces server. Can somebody give a detailed analysis on why it happened? Thanks :)
I'm not sure why it showed up differently on your machine, however your ans variable is an integer instead of a long.
the maximum value of the answer can be 51, so int is enough.
I've figured it out! When you make the bitset out of k, in your computer the initialization treats k as long long. However, in codeforces server, k is parsed into an int, and then the bitset is generated. Sorry, but your wrong answer is a consequence of lack of standardization among compilers :/. (You should try to print string s in custom test of codeforces to see how no bit of k is being registered in the server.)
I saw a wrong solution for A, then I quickly generate test and hack it. Unfortunately, he resubmit it just before me hack and I get a fail hack :(.
I think if you try to hack a code and this code is resubmitted it will said "that code has been hacked or resubmitted"
I don't know why :(. I easily paste the input, click the hack button and I didn't see any alert.
if you see that he resubmitted a code it doesn't mean that your hack is tested on the new code simply your hack is wrong :"D it is not a problem .... and it is illogical that you hack a code and your hack tested on another code :"D.
I was the one you tried hacking. You are not correct, thienlongtpct
From log we see, that I submitted after your hack:
My initial code: 22962124 simply passed your hack http://codeforces.me/contest/743/hacks/273143/test with a correct result :)
Oh, maybe when I see unsuccessful hacking, I reload a page and see you have resubmit the problem. Congratulation for your new color.
I was wondering why a hack of 10000 (or 1e4) on problem C gave me an unsuccessful hack while the exact same code TLE'ed for an input of 8863. Here is the code: http://codeforces.me/contest/743/submission/22965351 Any inputs are much valued.
I think it not depend on how bigger the number N is, it depen on the time we find the answer.
Maybe with n = 10000, it may find the answer quickly and and then end the program (exit (0)) when the stament is true. However, with n = 8865 it cosume more time to find the answer.
When I try it on CUSTOM INVOCATION
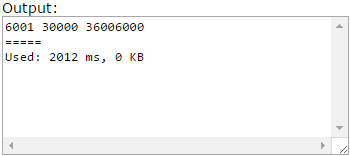
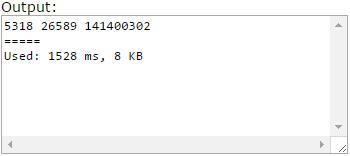
- for 10000
- for 8863
daayum, so close, yet so far. i hope, next ranked my rank can improve at least one point. 
contest is over guys now enjoy!!!!
Hi Guys!
I need some help, I'm not an expert in java but I'm not sure what is happening about this code, for several prime numbers is working but for instance for the prime number 6491 I'm getting something strange when I run the code. This is my actual code
As this number is prime then the List div is going to have just two elemens 6491 and 6491 but when I compare them java is saying its comparisson is false when should be true, could some one tell me please if I'm missing something or I did something wrong?, thank you in advance
I think you have to write your code on ideone in order to be readable
Thank you and sorry about it, it was my first comment ever, I research about my comment and seems like my mistake was to write div.get(0) == div.get(1) instead of something like div.get(0).compareTo(div.get(1)) == 0
Can anyone please tell me what's special about test case 15 in problem D? I am getting WA. Here is my submission.
You only check for subtrees of the first tree that have more tan 1 child. It is possible that the answer is lower in the tree. Take the following test case: ~~~~~ 7 -1 -1 -1 1 1 -1 -1 1 2 1 3 2 4 2 5 3 6 3 7 ~~~~~ Your program will state that the answer is 1 (from the subtree rooted at 2)+(-1) (from the subtree rooted at 3), when actually, the answer is 1 (from the subtree rooted at 4)+1(from the one rooted at 5)
Thanks for pointing out the problem.
Problem C My code is incorrect, however I pass the final test... Code refer to this paper
You can hack my by follow data whose factors != 1 mod 24
73 97 193 241 313 337 409 433 457 577 601 673 769 937
Can someone explain how to solve D ? I don't understand the editorial and it's a bit hard to analize codes.
First, by dfs you can get sum[u] and dp[u].
- sum[u] means the sum of a[u] and a[ vi ],vi is the son of u
- dp[u] means the max value of sum[u].....dp[ vi ],vi is the son of u
and start another dfs
when dfs(u),
- if u have more than 1 son you choose twos sons v1 and v2,satisfy dp[v1] and dp[v2] is the max and second max value in the son of u.and record the max value of v1 + v2.
here is my code 22968058
can anyone explain the idea of problem B with proof?
its a constructive algorithm so it prooves itself. you can calculate the length of the array in o(n) with formula lng[i] = lng[i-1]*2+1; array is constructed as last array + new element + array; so thr new element is in the middle. with that observation you can say that if the element k you search is in the middle you can say its the unique element of the given length. if its in the left side, you search in array n-1 the same k. if its in the right side, you know that both halves look the same so you find the corespondent of the k-th element in the left side, which is k-lng[n-1]-1 and search that element in the n-1 string
hope it helps, sorry for bad english
743B — Chloe and the sequence : value of k cannot be greater than 2^50 — 1 but in** test case 34** it is 2^50. My submission was evaluated as wrong please take desired action.
562949953421312 = 2^49, 1125899906842624 = 2^50, isn't it?