


Hello, Codeforces!
Educational Codeforces Round 16 will take place on 22 August 2016 at 17:00 MSK for the first and the second divisions.
It will be the last educational round prepared by me. As I earlier said I started to work at the great team of AIM Tech and now have less time to prepare a rounds. To leave the rounds interesting and qualitative another guy will continue to prepare them.
The problemset was partially suggested by Codeforces users. The problem C was suggested by user Resul Hangeldiyev Resul. The problem E is the next problem suggested by Zi Song Yeoh zscoder. The problem F was suggested Alexandr Kulkov adamant. Other problems was suggested by me (they are standard, but it is important to be able to solve them).
All the problems was prepared by me (Edvard Davtyan). Thanks to Tatiana Semyonova Tatiana_S for checking the English statements. Thanks a lot to Ivan Popovich NVAL for testing the problems A-E and Alexandr Kulkov adamant for testing the problem F.
I hope you will enjoy the problems! I think the problemset is little bit more difficult than usual, but I'm sure that it will not stop you :-)
Good luck and have fun!

UPD 1: The testing on hacks is completed. Thank you for participation!
UPD 2: The editorial is ready.







Your rounds are always interesting, We'll miss these rounds :D
Good luck at AIM Tech!
what a sticker !!!!!!!!!!!!!!!!!!!!!!
I love the ECR,because it's unrated,so I can enjoy the competition's process rather than the result!
Hacking also.
Rated?
Educational Rounds are never rated.
So much against. So sad.
Guys , is AIMTech round rated ?
Is this rated?
Yes.
secta! it's educational round, how can you say yes about the rating?!
That was just an evil way to teach people who still ask this question, I assume.
I think it would be nice if announcements would say whether or not the contest is rated.
Agree! However, they sometimes do but some people still ask. Apparently reading announcements is not worth their time.
some of them are new to Codeforces ... maybe they really don't know about educational rounds.
That's right but come on, before asking the question he wrote this meaningless answer to the same "Is it rated?" question, which was already answered.
sarcasm
Your'e asking this question while you replied
Maybe. Ask Mike.!This does not stimulate without rating
This is a good opportunity to train your skills. And you have to train in order to get nice rating anyway. Here you still can compete with passion and without any risk to your rating. What else?
and 24 hour hacking is helpful too!
Our goal is to improve ourselves,
Wish good luck to all :)
Hacking friends code is the funniest part :D
Why late ?
10 min late!!!!!!!!!!
Codeforces: " Contest has started. Proceed? OK? ".
Me: " OK! ".
*Page Refreshes"
I travel back 10 minutes
Codeforces: " 10 minutes remaining ".
and people said time travel is not possible :)
Now that the contest has been delayed there's a even shorter gap between this and csacademy's round...
wish there be no long queue...
Didn't understand Problem B at all, can someone explain what was supposed to be done?
google it "goemetry median"!
All, you have to do it`s sort array and print middle element.
there are dots in a line the x are the dots you have to choose one of the dots and then, you should find the dot that as the smallest sum of distance to other dot example 4 1 2 3 4
if you choose 1st -> dis=1+2+3=6; else if you choose 2st -> dis=1+1+2=4; else if you choose 3rd -> dis=1+1+2=4; else if you choose 4th -> dis=1+2+3=6;
therefore, the ans is the left one, 2
why is my code wrong?
http://codeforces.me/contest/710/submission/20060223
For each point with coordinate
xyou calculate sumSof the distances to other points, namelyS = sum{|x - x_i|}. Then choose the point with the smallestS.The most straightforward solution is O(N^2) — N times you calculate the sum of N integers. You can improve complexity if you first sort all points by coordinate. Then if you move from point
ito pointi + 1, the difference betweenS_i+1andS_iis(2*i - n) * |x_i+1 - x_i|. Then you can calculate allS_iin O(N)."For each point with coordinate x you calculate sum S of the distances to other points"
So like this?
For input
4
1 2 3 4
1st would be 1 + 2 + 3 = 6
2nd would be 1 + 1 + 2 = 5
3rd would be 1 + 1 + 2 = 5
4th would be 3 + 2 + 1 = 6
The output would be 2 since it is the left most and has the smallest sum, is this how we have to get the output?, I wish there was output explanation like in other contests.
Exactly. I would also like to see more explanations in the contests.
Awesome, it could be great Div2 round!
Did someone pass E using segment tree?
I just did :P
http://www.codeforces.com/contest/710/submission/20066011
can you explain your approach?
Sure! (It is very stupid though)
We know that if we duplicate a string s to form a string t of length n, then length of s must be at least ceil(n/2). Let the length of s be r. Then, ans[n] is minimum over ans[r]+y+(2r-n)*x=ans[r]+2rx+y-nx. Once you find such r, take minimum with ans[n-1]+x.
We actually need the minimum value of ans[r]+2r over r=ceil(n/2) to n-1. So I maintain a segment tree for these values. Once I have calculated the value of ans[n], I update it in the segment tree.
Hope this helps! :)
/
Apparently, somebody cared and asked me to clarify it. So your argument is invalid. :)
Please someone explain us the "E" problem!!
It`s simple dynamic programming. Create an array of positions,and then use this method to calculate next position.
dp[1]=x; dp[i] = min(dp[i — 1] + x, dp[(i + 1) / 2] + y + (i % 2) * x);
Why is this correct?
EDIT: Nevermind, I see it now.
Well, DP is like magic :).
Can you prove its correctness?
In optimal case the sequence of operations could never have a Delete operation just after an Add operation. As they'll cancel each other's effect and will increase cost, so we could just remove those two.
Also, there can't be two remove operations consecutively in optimal case as before any consecutive chain of remove operations, there will be copy operation (As add is not allowed before any remove and the sequence couldn't start from a remove). So, the operation string will have a sub-string like (Copy, Remove, Remove), and we can always reduce such a sequence to (Remove, Copy) to have the same effect with reduced cost.
So finally we have two rules :
1) There can't be any add operation before remove operation.
2) There can't be any remove operation before remove operation.
So if there's a remove operation, then we can be sure that the previous operation to it was a copy operation. And hence we can merge those two to a single operaton.
So the modified operations are :
1) Copy : (cost y)
2) Add : (cost x)
3) Copy (Double entire string) and Remove one character. : (cost x + y)
The modified operations are incremental and will always increase the size of the string so a O(N) DP is easily possible now.
I don't see how the cost will always be reduced with (Remove, Copy). Aren't you assuming that cost(p)<=cost(q) , p<q ?
n=8 => 1->2->4->8
n=7 => 1->2->4->8->7, 1->2->3->6->7
If x==y, then clearly cost of 7 > cost of 8.
Can you please explain how you arrived at your conclusion?
He doesn't make that assumption anywhere.
If you have Copy then k times Remove you can as well have (k/2) times Remove then Copy. Ta-dam you just saved (k/2) remove operations. Now you can repeat that until you get 1 remove operation ( k -> k/2 -> k/4 ... k==1 ).
Example:
Case 1: x letters -(copy)-> x*2 -(remove k times)-> x*2-k letters
Case 2: x letters -(remove k/2)-> x-(k/2) -(Copy)-> (x-(k/2))*2 == x*2-k
Case 2 will always be cheaper since you just remove fewer times.
Nice DP!!!
Please, can you explain why if write "dp[i / 2]" solution gets wa6, but if write "dp[(i + 1) / 2]" solution gets ok?
dp[(i+1)/2] + (i%2)*x + y represents a duplicate operation and a remove operation (when i is odd), if you use dp[i/2] you won't consider those operations
Thanks, I understand.
Lets say , we currently have 2 a's in the string, if we duplicate and add element we get 5 a's in the string. Similarly, if n=5, if we remove and are going to de_duplicate we will get 2 a's right. But why are we going to a string having 3 characters.(5+1)/2 after spending x+y.
why my recursive dp solution not working 20081091
Your solution is wrong, your recursion as cycles.
dp(x+1) -> dp(x-1) for example
Is there no open hacking this time?
hacking is open...
I have no clue how people managed to come up with logic of building odd matrix without googling the solution,this algorithm is way confusing on first look.
Damn, I could google it!
Sample test case helped in finding pattern xD. And then it was easy to prove why the pattern works.
Can someone post any link to understand the pattern for C or explain it here. I still dont get how to generate it. Some people have implemented very nicely. like this and this
For a 7*7 matrix: empty cells are even numbers.
http://uploadpie.com/VrpZe
I just follow the method for constructing a magic square of odd order.
I've made a square of odd numbers rotated by 45 degrees like this for n = 7
0001000
0011100
0111110
1111111
0111110
0011100
0001000
Statement for B problem asked for a a which may or may not exist in the array. The question statement was ambiguous. Many coders faced the difficulty that they understood that it may any integral point and they were giving the geometrical median, whereas the question was asking for any x in the array. Please make clear statements.
No, the answer doesn't require to be exist in the array, but you can prove that the minimum answer always exist in the array.
I asked in problem B if the point X is one of the input points but even the answer didn't show that it must be one of the input points
It doesn't follow from the task, but this can be proved.
how to prove that ot will be the optimal if we take the point from the input there are many optimal solution we could have by other points not in the input !
The sum changes monotonically between x[i — 1] and x[i].
Obviously that the answer point can't be to the left of the left input point and to the right of the right input point. Then assume the answer point is not one of input points and distance to the nearest point in the left is d1 and in the right — d2, the amount is S and also there are k points to the left of out. Then if we choose the nearest point in the left the sum is S — k * d1 + (n — k) * d1 = S + (n — 2 * k) * d1. And if we choose the nearest right point the sum is S + k * d2 — (n — k) * d2 = S + (2 * k — n) * d2. One of these numbers is less than S. So choosed point is not the answer.
if N is odd then there is only one answer and it is in the input.
if N is even there can be many answers but there have to be at least one of them in the input.
that's because the left most answer is always one of the given points
Can we solve F with trie data structure?
You mean F?
yes F, sorry for typo!
looking at tourist's solutions makes me feel so stupid
Well, you can always look at mine's to feel smart :)
can anyone hack this solution, as the value for accumulating sum is taken as int. http://codeforces.me/contest/710/submission/20059546
I think it can't be hacked. Because count1 will always equal to count2, so it doesn't matter whether they overflow or not. And the code will always output coords[N/2 — 1] if N is even, and that's the correct answer.
Was it possible to solve problem D using ternary search?
B* xD xD
Tests of problem C are all possible inputs! and someone are trying to hack !!!
problem B ) please guys now i understand the optimal solution is to get a point from the input to be the optimal .ok ! but i don't know why the element in the middle of the array is the answer not the middle of the all distance ? proof please!
You could also try out all the points and pick the best one.
http://codeforces.me/contest/710/submission/20051324
i did saw it before and i liked it but i want to understand why the middle element ? i can do ternary too can't i ?
For example if you have n = 7 and the following points
1 3 5 7 9 11 13
Let's say we choose the middle point ( 7 ). If we try to move it to the left we'll end up adding 2 ( 7 — 5 ) to the total distance 4 times while decreasing 2 from the total sum 3 times which means that the total distance will be greater than the distance we would've had by choosing the middle element.
Same goes for moving the element to the right.
EDIT: If you meant why the middle element and not the middle of all the distances, that's because you need to choose an element from the array.
why the middle element and not the middle of all the distances?
that was my question ..but thinking in it i think selecting a point from the array will be better
Suppose you have two points, you can easily see that while you are in between them the sum of distance is constant and the smallest and the leftmost point is the point on the left(and an integer as it is an input point), but if you go right of the right, sum of distance increases and so is if you go left of the left. Now consider 3 points, for the extreme points the answer lies between them, now forget them and consider the middle point, for a single point the answer lies on the point itself because deviating from it will increase the value of distance from it to a nonzero value and since it is in between other two points it is the answer. Next, consider 4 points for the extreme two points least sum points lies between them and for the middle two between them and points between middle two also lies in the middle of extreme so the answer is left of the two middle points as it is the leftmost satisfying above conditions. And so on...
hi there , i think there is a problem in your judge , during the contest i submited the true answer , but i received the wrong answer , i checked that answer and there is no wrong thing in my output , here is my code :
http://codeforces.me/contest/710/submission/20061137
any ideas ?
The sum on the main diagonal for n = 3 is 8 + 9 + 7 = 24 which is even.
Oops , i didn't check main diagonals in my code , all my focus was on rows and columns , sometimes brain doesn't work during contest ...
What is the idea behind problem F? A dynamic Aho-Corasick?
I'm struggling with this! :-(
My approach is SQRT decomposition. Lets have a constant B equal to about 2000.
If a query of 3rd type has length less than B we can simply check all substrings and get the answer. The complexity is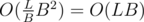 , where L is the length of the text.
, where L is the length of the text.
If a query of 3rd type has length greater than B we can make an O(N) or O(L) approach, because there are at most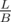 such queries. We can build a tree of the suffix links (if we use suffix automaton) or failure links (if we use Aho Corasick). The edges are of form "link[u] -> u". Then to for every such query we will build such a tree. Now for every string in the set D, we update its end state's subtree with 1. Now to get the answer to the current string, we go through all of its prefix states and query them (vertex query). So the problem becomes subtree update and vertex query. The whole query can be done in
such queries. We can build a tree of the suffix links (if we use suffix automaton) or failure links (if we use Aho Corasick). The edges are of form "link[u] -> u". Then to for every such query we will build such a tree. Now for every string in the set D, we update its end state's subtree with 1. Now to get the answer to the current string, we go through all of its prefix states and query them (vertex query). So the problem becomes subtree update and vertex query. The whole query can be done in 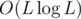 time.
time.
The overall complexity is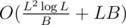 . We want
. We want 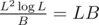 to have almost the same complexity for the 2 types of queries of 3rd type. Thats why we pick B about 2000.
to have almost the same complexity for the 2 types of queries of 3rd type. Thats why we pick B about 2000.
I solved the problem with a generalized suffix automaton during the contest but it can be easily replaced with an Aho Corasick. Link to submission: 20062687.
If a query of 3rd type has length greater than B,for each query,you will build a tree,what's the complexity about making a tree,is the total length of strings in suffix automaton? And there are L/B queries,how to calculate complexity?
If the query is of 3rd type and it's heavy (has length ≥ B) we build the tree on all string in the automaton. We can easily build it in O(L). There are at most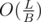 heavy queries because every heavy query has length ≥ B. This means that to solve all heavy queries we have complexity of
heavy queries because every heavy query has length ≥ B. This means that to solve all heavy queries we have complexity of 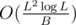 .
.
Another interesting way to solve it is to keep logM automata. When adding a string, you create an automaton of size 1, consisting of that string. While you have two automata of the same size, merge them, obtaining one of double the size. The merge can be done using the typical Aho Corasick build procedure. To handle the erase operation, we can keep another logM automata, composed of the erased strings. We will handle these the same way we did for the above. Therefore, the answer of a query will be query(all) - query(erased). This achieves a complexity of O(sumlengths * logM). This idea was discussed here. 20053668 implements it, to some extent.
If you prefer not to use SAM or Aho Corasick, you can insert the strings of length < SQRT into a trie, and for each of the rest you build the KMP automaton. This method achieves O(sumlengths * sqrt(M)). You can check out 20058436 for more details.
Wow! The first solution is really cool! Thanks for explaining it :)
By the way there is another possible solution with hashes. We can see that there are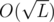 different lengths of strings. That means that we can store all hashes for a given length in a hashtable for the corresponding length. This way we can simply create a
different lengths of strings. That means that we can store all hashes for a given length in a hashtable for the corresponding length. This way we can simply create a 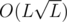 solution with hashes.
solution with hashes.
But there may be more than sqrt(L) hash values, so the time complexity may be more than O(Lsqrt(L)) I guess?
There can be at most O(sqrt(L)) distinct lengths because the sum of the lengths doesnt exceed L, so in the worst case, which is 1 + 2 + .. + k = l equivalent to k * (k + 1) / 2 = l, k is of order O(sqrt(L)). To answer a query we will traverse all the O(sqrt(L)) hash tables, which we can query in O(1), along with some partial substring hashes on our query string.
Oh I understand now. Thanks for the explanation.
But I think this method might not be fast enough. My submission get TLE.(20105952) Maybe if the time limit is 10s then I can pass?
You can pass it, if you are careful when implementing it. Try to get rid of unnecessary modulo operations, instead of keeping an unordered_map of unordered_maps you can keep a set or an unordered_set of fixed size, and one set to keep track of the distinct lengths.
L.E.: 20106642 is my accepted code, following this idea.
I'm a rank beginner. Can somebody shed some light on the arithmetic progression problem? I brute forced it and it gave me several TLEs. I have a hard time figuring out just by looking at other people's submissions.
I'd appreciate it if someone could point me to the correct number theory algorithm or lemma. Thanks.
I think E can also be solved using bfs with priority_queue. Did anybody try it?
I've already done it in C++ and got TLE.
I treat this problem as the shortest path problem. At first I got TLE when x is small and y is large, that's because the distances of the nodes are updated quite frequently. Then I set the initial distance of the i-th node as i*x, so the distances won't be updated too frequently. Then I got AC.
You can also see my submission for details 20059443
Nice idea!when I got TLE,I thought it cannot get Accepted by Spfa!Help a lot!
It can be solved with Dijkstra after a few observations.
Once we're done, we push all relevant states with their initial distances to the Dijkstra's queue and run it. It runs instantly. See here -> 20087826
For the problem B
a same position could have more than one points?
Yes. But since we only need to output the position of the optimal point so it doesn't matter.
Where can I find the editorial please?
Did anybody solve problem D? Can anybody give me an approach for this problem?
We can assume that b1 <= b2 (otherwise let's just swap(a1, a2) and swap(b1, b2))
Sequence 1: b1, b1+a1, b1+2*a1, b1+3*a1, ...
Sequence 2: b2, b2+a2, b2+2*a2, b2+3*a2, ...
1) Let's find minimum K>=0 such that b2+K*a2 belongs to the sequence 1.
b2+K*a2-b1 must be divisible by a1. It's enough since b2+K*a2-b1 >= 0.
K*a2 = b1-b2 (modulo a1)
Let's denote GCD(a1,a2) = a_gcd
1.1) If (b1 — b2) is not divisible by a_gcd, there is no solution to this. The sequences do not have any common numbers, thus the answer to the problem is 0.
1.2) If (b1 — b2) is divisible by a_gcd:
K*(a2/a_gcd) = (b1-b2)/a_gcd (modulo a1/a_gcd)
We can use any algorithm to find "modular multiplicative inverse": https://en.wikipedia.org/wiki/Modular_multiplicative_inverse
2) The first common element of Sequence 1 and Sequence 2 is A = b2+K*a2
Next elements will be A+LCM(a1,a2), A+2*LCM(a1,a2), ...
If you know A and LCM(a1,a2), it's easy to find how many of these numbers belong to interval [L, R]
I solve it with 2 brute force solutions.
0) if a1 < a2 swap a1/a2 and b1/b2
Brute force #1: a1 > 1000 iterate first sequence and check if point in second.
Brute force #2 a1 <= 1000, if b1 < b2, required increase b1 to be >= b2 Scan b1, b1+1, b1+2*a1, ... b1+1000*a1 to find a first common point, if not exists answer will be 0 As we know first common point and also need know a step it will be lcm(a1,a2) Now we have one progression and need know count of points in interval [l,r] it possible done in O(1).
That's all.
Problem D, test 84: 1643097 -1745072283 4818 -1699409409 1391770030 14101637
How about constraint L <= R?
Validator was fixed. Tests 84 and 126 were removed. Solutions that failed on 84th test were rejudged and got Accepted. There were no solutions failed on test 126.
I believe that somebody hacks using these tests. This is rejudged?
This is my hacks:
Test #126: http://codeforces.me/contest/710/hacks/250257
Test #84: http://codeforces.me/contest/710/hacks/250285
I implemented aho corasick algorithm on problem F and I got idleness limit exceeded on test 1, I wonder what is the cause? It's the first time I encounter this problem so I don't have an idea where the problem lies. =/
[submission:http://codeforces.me/contest/710/submission/20107516]
UPD: Didn't noticed the solution is required to be online. =P"
When will the editorial be posted?
Here is my solution to Problem D,may be easier to understand.
Some restriction like:
If we combine these,we can get some scale like L1 < = k' < = R1
Then,we need k' be integer which means a1 * k' - a2 * l' = b2 - b1 has integer solutions and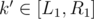 . This can be solved used exgcd.
. This can be solved used exgcd.
If u are still confused,here is my code.
This round is important and must have an English Editorial.
Codeforces is a good international site.
Please don't limit us by only releasing in Russian. I kindly request you to release an English version.
Sorry for the late translation. It's ready now.
Who will continue to prepare next educational rounds?
When will the next educational round start? It is a good idea to have a educational round on every Sunday.
Yeah my friend I agree with you .., eagerly waiting for education Round 17