


Here are the solutions to all problems.
Div.2 A
Just alternatively print "I hate that" and "I love that", and in the last level change "that" to "it".

Time Complexity: 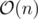
Div.2 B
First of all, instead of cycles, imagine we have bamboos (paths). A valid move in the game is now taking a path and deleting an edge from it (to form two new paths). So, every player in his move can delete an edge in the graph (with components equal to paths). So, no matter how they play, winner is always determined by the parity of number of edges (because it decreases by 1 each time). Second player wins if and only if the number of edges is even. At first it's even (0). In a query that adds a cycle (bamboo) with an odd number of vertices, parity and so winner won't change. When a bamboo with even number of vertices (and so odd number of edges) is added, parity and so the winner will change.

Time Complexity:
A
Consider a queue e for every application and also a queue Q for the notification bar. When an event of the first type happens, increase the number of unread notifications by 1 and push pair (i, x) to Q where i is the index of this event among events of the first type, and also push number i to queue e[x].
When a second type event happens, mark all numbers in queue e[x] and clear this queue (also decreese the number of unread notifications by the number of elements in this queue before clearing).

When a third type query happens, do the following:
while Q is not empty and Q.front().first <= t:
i = Q.front().first
x = Q.front().second
Q.pop()
if mark[i] is false:
mark[i] = true
e[v].pop()
ans = ans - 1 // it always contains the number of unread notifications
But in C++ set works much faster than queue!
Time Complexity: 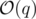
B
Reduction to TSP is easy. We need the shortest Hamiltonian path from s to e. Consider the optimal answer. Its graph is a directed path. Consider the induced graph on first i chairs. In this subgraph, there are some components. Each components forms a directed path. Among these paths, there are 3 types of paths:
- In the future (in chairs in right side of i), we can add vertex to both its beginning and its end.
- In the future (in chairs in right side of i), we can add vertex to its beginning but not its end (because its end is vertex e).
- In the future (in chairs in right side of i), we cannot add vertex to its beginning (because its beginning is vertex s) but we can add to its end.

There are at most 1 paths of types 2 and 3 (note that a path with beginning s and ending e can only exist when all chairs are in the subgraph. i.e. induced subgraph on all vertices).
This gives us a dp approach: dp[i][j][k][l] is the answer for when in induced subgraph on the first i vertices there are j components of type 1, k of type 2 and l of type 3. Please note that it contains some informations more than just the answer. For example we count d[i] or - x[i] when we add i to the dp, not j (in the problem statement, when i < j). Updating it requires considering all four ways of incoming and outgoing edges to the last vertex i (4 ways, because each edge has 2 ways, left or right). You may think its code will be hard, but definitely easier than code of B.
Time Complexity: 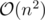
C
Build a graph. Assume a vertex for each clause. For every variable that appears twice in the clauses, add an edge between clauses it appears in (variables that appear once are corner cases). Every vertex in this graph has degree at most two. So, every component is either a cycle or a path. We want to solve the problem for a path component. Every edge either appear the same in its endpoints or appears differently. Denote a dp to count the answer. dp[i][j] is the number of ways to value the edges till i - th vertex in the path so that the last clause(i's) value is j so far (j is either 0 or 1). Using the last edge to update dp[i][j] from dp[i - 1] is really easy in theory.

Counting the answer for a cycle is practically the same, just that we also need another dimension in our dp for the value of the first clause (then we convert it into a path). Handling variables that appear once (edges with one endpoint, this endpoint is always an endpoint of a path component) is also hard coding. And finally we need to merge the answers.
Time Complexity: 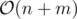
D
Assume r < b (if not, just swap the colors). Build a bipartite graph where every vertical line is a vertex in part X and every horizontal line is a vertex in part Y. Now every point(shield) is an edge (between the corresponding vertical and horizontal lines it lies on). We write 1 on an edge if we want to color it in red and 0 if in blue (there may be more than one edge between two vertices). Each constraint says the difference between 0 and 1 edges connected to a certain vertex should be less than or equal to some value. For every vertex, only the constraint with smallest value matters (if there's no constraint on this vertex, we'll add one with di = number of edges connected to i).
Consider vertex i. Assume there are qi edges connected to it and the constraint with smallest d on this vertex has dj = ei. Assume ri will be the number of red (with number 1 written on) edges connected to it at the end. With some algebra, you get that the constraint is fulfilled if and only if 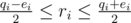 . Denote
. Denote 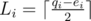 and
and 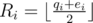 . So Li ≤ ri ≤ Ri. This gives us a L-R max-flow approach: aside these vertices, add a source S and a sink T. For every vertex v in part X, add an edge with minimum and maximum capacity Lv and Rv from S to v. For every vertex u in part Y, add an edge with minimum and maximum capacity Lu and Ru from u to T. And finally for every edge v - u from X to Y add an edge from v to u with capacity 1 (minimum capacity is 0).
. So Li ≤ ri ≤ Ri. This gives us a L-R max-flow approach: aside these vertices, add a source S and a sink T. For every vertex v in part X, add an edge with minimum and maximum capacity Lv and Rv from S to v. For every vertex u in part Y, add an edge with minimum and maximum capacity Lu and Ru from u to T. And finally for every edge v - u from X to Y add an edge from v to u with capacity 1 (minimum capacity is 0).

If there's no feasible flow in this network, answer is -1. Otherwise since r ≤ b, we want to maximize the number of red points, that is, maximizing total flow from S to T.
Since the edges in one layer (from X to Y) have unit capacities, Dinic's algorithm works in 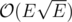 (Karzanov's theorem) and because
(Karzanov's theorem) and because 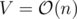 and
and 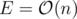 Dinic's algorithm works in
Dinic's algorithm works in 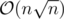 .
.
Time Complexity: 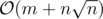
E
First, we're gonna solve the problem for when the given tree is a bamboo (path). For simplifying, assume vertices are numbered from left to right with 1, 2, .., n (it's an array). There are some events (appearing and vanishing). Sort these events in chronological order. At first (time - ∞) no suit is there. Consider a moment of time t. In time t, consider all available suits sorted in order of their positions. This gives us a vector f(t).

Lemma 1: If i and j are gonna be at the same location (and explode), there's a t such that i and j are both present in f(t) and in f(t) they're neighbours.
This is obvious since if at the moment before they explode there's another suit between them, i or j and that suit will explode (and i and j won't get to the same location).
Lemma 2: If i and j are present in f(t) and in time t, i has position less than j, then there's no time e > t such that in it i has position greater than j.
This hold because they move continuously and the moment they wanna pass by each other they explode.
So this gives us an approach: After sorting the events, process them one by one. consider ans is the best answer we've got so far (earliest explosion, initially ∞). Consider there's a set se that contains the current available suits at any time, compared by they positions (so comparing function for this set would be a little complicated, because we always want to compare the suits in the current time, i.e. the time when the current event happens). If at any moment of time, time of event to be processed is greater than or equal to ans, we break the loop. When processing events:
First of all, because current event's time is less than current ans, elements in se are still in increasing order of their position due to lemma 2 (because if two elements were gonna switch places, they would explode before this event and ans would be equal to their explosion time). There are two types of events:
Suit i appears. After updating the current moment of time (so se's comparing function can use it), we insert i into se. Then we check i with its two neighbours in se to update ans (check when i and its neighbours are gonna share the same position).
Suit i vanishes. After updating the current moment of time, we erase i from se and check its two previous neighbours (which are now neighbours to each other) and update ans by their explosion time.
This algorithm will always find the first explosion due to lemma 1 (because the suits that're gonna explode first are gonna be neighbours at some point).
This algorithm only works for bamboos. For the original problem, we'll use heavy-light decompositions. At first, we decompose the path of a suit into heavy-light sub-chains (like l sub-chains) and we replace this suit by l suits, each moving only within a subchain. Now, we solve the problem for each chain (which is a bamboo, and we know how to solve the problem for a bamboo). After replacing each suit, we'll get 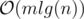 suits because
suits because 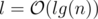 and we need an extra log for sorting events and using set, so the total time complexity is
and we need an extra log for sorting events and using set, so the total time complexity is 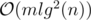 .
.
In implementation to avoid double and floating point bugs, we can use a pair of integers (real numbers).
Time Complexity (more precisely): 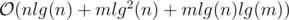







Thanks for the quick editorial =D
For Div1B/2D, can someone help elaborate a bit more about how to transit from dp[i] to dp[i+1]?
Tags are so sad! Thanks anyway, nice problem set! :)
They really are..
Would some kind gentlemen please explain problem A (Div 1) in simpler terms? Thank you!
It is basically like this : You have an array with all terms initially 0. Operations: op1 : for the x we must a[x]++. op2 : for the x we must a[x]--. op3 : for the first t operations of type 1 i.e for x[1],x[2],....x[t] decrement the values if they are not already updated (ie not already read). if(x[i] != 0) x[i]--; so here brute force will time out . So op1 and op2 are similar . But for 3d one instead of updating all the first t we will update this time , if the previous update time was lesser than current . (I.e we need not read something that has already been read) you can check the update time in code of some submitted solution.Queue is maintained to keep track of last updation time of a particular element . So since each time element is processed at max once O(Q + T). Hope i helped , this is my first explanation on CF so please be kind on me :)
Oh, lord, I meant problem B (Div 2), but thank you anyway :)
Why "lastcontest" in Tags? :(
Last contest before IOI
NOPE! My last contest.
Why? Is there any reason?
Because people usually give up when confronted with some hardship instead of shaking off the dust, standing up and moving forward :)
I enjoyed Ur contest amd sir. Finally I am specialist nw. Thanks to u.
Come on, don't be so depressed. You have many great rounds before. Looking forward to your next contest!
I don't think he's depressed. He's probably just tired of competitive programming and wants to do something new.
Oh, maybe you are right.
Yeah, this is the case. But why do you care anyway? Number of downvotes to the announcement of my last contest says my contest ain't that popular...
Why so sad? Sometimes something goes unplanned,this time the tasks were hard but it is not your fault,you can't predict such things,the problem is that a lot of people can't accept fail,most of them just don't know how many time you have to spent to fully prepare a problem.
I like your problems and I think your contests were very educational for me , specially your math and query based problems ...
I hope you continue your work but if not we will miss your interesting ideas and heros like Duff ... :(
Hope you bests in IOI.
My attempt to Div2 D (Ant Man). is it valid?
mark
sas visited. start froms, find the next unvisited position with minimum jump cost. Let it bey1.mark
y1as visited. start from 'y1', find the next unvisited position with minimum jump cost. Let it bey2.... doing like this, we get a greedy path: s — y[1] — y[2] — ... — y[n-2] — e
For convenience we can say s = y[0] and e = y[n-1].
Let's assume this is not the optimal path. then there exist some i,j such that exchanging y[i] and y[j] decreases the total cost.
But exchanging y[i] and y[j] causes following change:
from
to
But
There is contradiction. Therefore the greedy path is optimal.
cost[j-1, j] <= cost[j-1, i] for all i.
this is wrong. It is for all i that wasn't visited.
What is the reason for TLE in Div2C/Div1A on tests ~40-70? Can you look at my code and tell me?
Edit: I had a bug:
last = xinstead oflast = max( last, x ). After fixing that, I got AC.Nice contest, thank you amd.
Sorry to talk about this, but I think shouldn't pass problem B (or D in Div.2). Because, I was writing a simple greedy algorithm and it actually pass the system test!! What???
Can you describe it please?
http://codeforces.me/contest/705/submission/19710317
It works as follows: Start with a direct edge S->E. Then keep adding a new node (chair) from 1 to N, excluding S and E. For each chair, find the best location to insert in the path. Thus, we have a very simple greedy solution, though I don't know if it's correct.
I think it is not correct(but pass 0_0). For example, now you have 4->1->3 state and trying to add 5. And for example cost of 4->5->1 (if insert between 4 and 1) is less than 1->5->3 (if insert between 1 and 3) — you will have 4->5->1->3 state next and will never get right 4->2->1->6->5->7->3.
I have noticed that it doesn't work if you iterate in a different way. (Not 1 → N)
Though the reversed (N → 1) way seems to be fine
So it looks like this algorithm is incorrect,is it?
How did you come up to this conclusion?
can any red coder give us proof?
Fair player, respect!
Div2C/Div1A: Has anyone tried Sqrt decomposition?
Aren't the time limit for Div2 — C (Python) too strict ?
I got TLE on test case 52, which was apparently doing "1 1" x 300000 times. Code for the same:
arr.append(<something>). Solution : 19707083 :(I got TLE on 84, than on 55, and only after removing code of deleting values from list — acc. I think test 52 is doing something interesting in the end, not just "1 1". I think your problem too in "app[app_index].remove(read_pointer)". Try to create pointers for each app (and save them in dict). My accepted (sts[v] — such pointer for app[v]): http://codeforces.me/contest/705/submission/19712655
https://wiki.python.org/moin/TimeComplexity Delete Item O(n)
Could anyone please explain the Ant man (DIV2 D/DIV1 B) problem more thoroughly/easily? What property allows us to solve this TSP problem in polynomial time? What is exactly dp[i][j] here? Is this optimal solution for first i vertices, or something like "parts" of optimal solution? How do we update dp? Wouldn't this require iterating over all the components?
Suppose the following simpler problem: we need to get from chair 1 to chair N and visit each chair exactly once, you can jump from one chair to any other. If you are currently on chair i, it costs li to jump anywhere left and ri to jump anywhere right. Can this problem also be solved in O(N)2 ?
Edit: this problem can be reduced to original like the following: assume that landing is free and that jumping off the chair is costs x * 1e8 so that we can neglect the distance between two chairs. And that s = 1, e = N So the same approach should be working for this problem.
Please help me with this problem 705A - Халк, I don't understand why this code (1968850) doesn't write anything in the output of test case 11 (it's very awful for my friend who had passed the pretests). However, when I resubmit this code again after the contest Codeforces Round 366 (Div. 2), it's (19712336) AC!!! MikeMirzayanov, I hope you will look at this comment and take justice back to my friend nghoangphu. Thank you very much !
inductive proof for cycles in Div.2 B:
if f[x] = x — 1, then for any c in [1, x], we have:
It seemed that the conclusion also holds if we can always split an connected graph into two connected graphs until there is only one vertex in each graph.
Another proof: Suppose there are
mvertices in the cycle. In each turn,onecycle will be replaced withtwocycles and the number of cycles is increased by1. After the last turn, the number of cycles will bem(one vertex in each cycle), so the number of turns should always bem - 1.For div1B/div2D, how comes that we can solve this problem in O(n^2)? For small values of n I know how to solve the TSP probblem with dp and bitmasks. For me the Antman problem is just like TSP. What actually differentiates them and makes it solvabale in O(n^2)?
In the original Traveling-Salesman Problem, there is no pattern in how your input graph or what costs are there on the edges. For many classic NP-hard problems exist particular restrictions that make them solvable in polynomial time using some observations (ex. Minimum Vertex cover is NP for a general graph, however for bipartite graphs it's reduced to the maximum edge cover using the observations that make up the [König's theorem.](https://en.m.wikipedia.org/wiki/König%27s_theorem_(graph_theory)) . In this particular problem, observations can be made on the fact that the costs on the edges are not random (rather dependent on distance, orientation and the vertexes) and even that the graph is complete.
ignore, same question above
Почему если в задаче С использовать обычный массив и переменные co — количество запросов первого типа и ind — до какого запроса первого типа мы уже читали, и при очередном запросе типа 3 просматривать от ind до t, а потом обновлять ind = t, то получаем тайм лимит на 53 тесте (http://codeforces.me/contest/705/submission/19713056), а если юзать set, то все тесты проходит не больше чем за полсекунды (http://codeforces.me/contest/705/submission/19713545) . Ведь наоборот, должно быть больше времени во втором случае, как минимум вставка нового сообщения происходит за log(количество еще не прочитанных сообщений), для запроса третьего типа, каждое непрочитанное сообщение обрабатывается за O(1), так как мы двигаемся итератором по префиксу сета, а при запросе второго типа, каждое еще непрочитанное сообщение приложения x тоже обрабатывается за log(количество еще не прочитанных сообщений). В первой же программе, каждое из этих действий делается за O(1) и общая сложность O(q). Единственная накладка — это постоянно заполнять и очищать очереди для типов приложений, но ведь это точно также происходит и во второй программе. В общем какая то мистика. Буду благодарен, если кто — нибудь прольет свет на эту тайну)
I have understood. ind = t is not correct. In this case time complicity is O(q^2). I need to write ind = max(ind, t). It is correct and time complicity is O(q) and few faster than the solution with Set.
I am having trouble making my solution (19714564) for Problem C pass.
Here is my algorithm:
But this fails the 3rd test case. Please help.
Event 3 is processed incorrectly: the fact that there are some unread application x events (byApp(x) > 0) does not imply that those events are among the first t events. E.g. given 3 4 1 1 2 1 1 1 3 1, your code will delete the second addition event "1 1" whereas it should not have.
byApp(x)>0 does not necessarily mean that the top m messages must contain unread x. unread x may appear in the later message while x in top m messages has already been read.
Can somebody plz explain that why are we marking the numbers in div2 C.
We mark the notifications so we don't count them twice.
Can someone please tell me where I am wrong DIV2 C .My code is http://codeforces.me/contest/705/submission/19705093 Thanks.
It looks like the issue is the same — please see my comment above http://codeforces.me/blog/entry/46450?#comment-309097
I've finally got accepted for problem E. I want to share a bit different geometric view on the same solution as author's, but it may be easier to understand.
First, let's apply Heavy-Light decomposition and split each query into parts in such way that each parts belongs to a single path of HLD. Now we can solve problem on a line segment.
parts in such way that each parts belongs to a single path of HLD. Now we can solve problem on a line segment.
Let's introduce real-value coordinates on the segment (i. e. points have x-coordinates in range [0, len] where len is the length of a HLD segment). Draw an Oxt plane where t means the time. Each trajectory of a query looks like a segment (possibly, degenerate) on Oxt plane, and what we asked is to check if any two segments share a point, and if so, find the point with smallest t-coordinate.
If we had to just check an existence of such point, we could use a well-known sweeping line algorithm that iterates through endpoints of segments in order of their t values and stores segments in some balanced binary search tree checking neighboring pairs of segments for intersection on any insertion/deletion. But this algorithm can be slightly modified in order to find also the point with minimum t-value: all we need is to keep the current known lowest intersection (in sense of t) and stop our algorithm when we pass it.
Div2 D , was quite a difficulty jump. Most of the people got AC by using some kind of greedy technique i.e. so they considered a list of vertices in the order of visiting them . which initially contains S,E(path S->E) . then for every i from 1 to N they will try to place i inside the path list in a greedy way (which ever position leads to minimum result, S->i->E).
So basically , the question is that this is not DP , surely its not as we are not trying every permutation .So how can we be sure that the solution is right . Though i am not sure , but i think theres actually no need to do a perfect dp . For the moment lets consider this method to be wrong and consider there exists a path in which vertex A should have been placed before placing vertex B where B<A . But we know that Xb<Xa .Okay so if given 3 vertices C<B<A . we already have C in our list , now including A before B will not be a better solution because Xa-Xc + Xa-Xb > Xa-Xb + Xb-Xc . so including B before A is always better . can anyone provide more clarity ? or may be explain the given editorial in a better way ?.btw the problem was great .
For example you have 4->2->1->3 and inserting vertex 5 that in the answer is between 6 and 7, at this moment it can happen that insert 5 between 1 and 3 not the best, but answer is 4->2->1->6->5->7->3 http://codeforces.me/blog/entry/46450?#comment-309049
What is Karzanov's Theorem?
If anyone could explain it or just provide a good source, I'd appreciate it :)
My approach to C (even though I did not participate) was segment trees. We add 1 for unread notification, and 0 for read notification and get the sum to answer.
Basically push all notifications into vectors (apps). If type is 1, push the notification and update the value to 1. If type is 2, start from the first notification that was not read during the most recent time where the query gives type 2 and the same app. (This prevents TLE) Then iterate over the vector and update the tree value to 0. If type is 3, we update the "currenttime" value.
Then we get the sum from the currrenttime~end. (Because we don't need to look at notifications before "currenttime")
This gives a solution in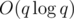 Implementation: http://codeforces.me/contest/704/submission/19718386
Implementation: http://codeforces.me/contest/704/submission/19718386
In Div1-B, does component here mean "connected component"?
PS: And can anyone explain the solution more clearly? I can't imagine how it work.
A pictorial description and sample code of editorial would help.
many of you couldn't understand the solution for DIV2 D/Div1 B
so here is my solution , hope it will help you
suppose you have a directed graph (there is an edge between every i and j ) and you have to find a path from S to E by visiting each vertex once
obviously each vertex except S and E should be linked with two different vertices
dp[i][j][k] represents minimum cost to reach the destination such that among the last i elements, j of them want to be linked with another vertex and k of them have an outgoing edge which is not connected to anything yet.
now we will consider each vertex separately ,we have three cases
a vertex with just outgoing edge (if that vertices is S)
dp[i][j][k] = min(dp[i+1][j-1][k] + x[i] + c[i], dp[i+1][j][k+1] -x[i] + d[i])
a vertex with just incoming edge (if that vertices is E)
dp[i][j][k] = min(dp[i+1][j][k-1] + x[i] + a[i], dp[i+1][j+1][k] -x[i] + b[i])
a vertex with incoming edge and outgoing edge
dp[i][j][k] = min(
dp[i+1][j-1][k-1] + 2*x[i]+a[i]+c[i] (an edge form vertex x to vertex i (x<i) and an edge from vertex i to vertex y (y<i))
dp[i+1][j][k] + a[i]+d[i] (an edge form vertex x to vertex i (x<i) and an edge from vertex i to vertex y (y>i))
dp[i+1][j][k] + b[i]+c[i] (an edge form vertex x to vertex i (x>i) and an edge from vertex i to vertex y (y<i))
dp[i+1][j+1][k+1] -2*x[i]+b[i]+d[i] (an edge form vertex x to vertex i (x>i) and an edge from vertex i to vertex y (y>i))
)
it can be proved that for any (i,j) k will be the same , so we can only memorize dp[i][j] and the complexity will be o(n^2)
First of all thanks for trying to shed some light on this problem that I can't wrap my head for 12 hours already.
What if destination is not in last i vertices? It would be INF? There are j elements without outgoing edges, k elements with outgoing edges that go nowhere, but what if two elements are connected? How can we conclude k then? And of course, why this approach won't work if I take a TSP (say I enumerate all vertices from 1 to N somehow) and apply this DP?
j is the number of vertices that doesn't have any edge going from another vertex to it.
no it wouldn't be INF , it would be the minimum cost to make a path from S to any vertex by visiting each vertex (from the last i vertices) exactly once
and if S in not in last i vertices it would be the minimum cost to make a path from any vertex to any vertex by visiting each vertex (from the last i vertices) exactly once.
look at the dp equation, if not either S or E in the last i vertices then (for any (i,j) ) j will be equal to k
otherwise the difference between j and k will be at most 1, now you can make it dp[i][j][d] where d represents the difference between j and k, so you can conclude k .
it can be proved that for any (i,j) k will be the same .
here is my submission for a better understand.
to be honest I'm not sure why this approach won't work for TSP
but in somehow?? I think it's impossible to enumerate all the vertices, because in this problem
dis(i,j) < dis(i,j-1) regardless of jumping and landing and that make this approach work.
I can't understand anything. Can you suggest similar problems which can help?
I'm sorry but I don't know any similar problems
but here is my submission , it will help you to understand the solution
In your submission,solve(i,j,k)means
solve(i,j,k):= with j,k conditions, the sum of cost that is increased by adding point[i],point[i+1],...point[n-1].
And in your memo[i][j], memo[0][0] is finally changed.
Because your solve(i,j,k) makes possible transitions and right end condition of the recurrence.
In addition,first of all, memo[n][0] is fixed to 0, after that, each memo[i][j] is fixed only when the best is fixed.
After adding i points,
Thus,k corresponding to j is only one in all possible right conditions.
Is this right?
I really want to know how to simply conclude k,too.
Finally accepted thanks to you :D submission
But there is something I'd like to emphasize, when (j == 0 && 0 == k) and (indexing mode) < i <= (last index) then we stop and indicate that this way won't lead to the intended solution because remaining vertices/chairs can't go to any chair on the left and likewaise, chairs on the left are fully connected to each other without an edge going to the right side, thus we end up having at least two disjoint components.
I've got a problem about the solution. Is there the possibility that the paths form a circur ? Just In dp[i][j][k] = min(dp[i+1][j-1][k-1]+2*x[i]+a[i]+c[i])?
Excuse me,I thought I had got your point about the solution.But my code got wrong answer at test5.I don't know where the problem is.And different from your code,I used simple loop instead of dfs to solve the problem.So I really want a simple loop version of the solution,could u give me an example?
Sorry to say, but not a very nice editorial. There are no codes of author too.
Edit: Sorry, I didn't see the link before.
There's a link to a gitlab page with all the official solutions. https://gitlab.com/amirmd76/cf-round-366/tree/master
Hello,
For Div.2 problem C, I had an idea during the contest using Segment Tree. We can build the tree on the events sum, then we can query and update our tree, but my solution was not fast enough (for queries of type 2).
I am really interested in solving this problem using Segment Tree. Any help?
Kindly find here my submission.
Here is my solution with Segment Tree. Actually, solution in editorial is easier.
Can anyone explain why div2D is not np hard problem?
I can't understand why it's not np hard.
Consider the middle chair
If you choose one on the right to jump on, you will pay the same amount of money regardless of your choice (which one to choose on the right side), similarly, if you choose one on the left, you will pay another constant value regardless of your choice
So basically, each chair has 4 states:
previous chair and next chair are on the right side
previous chair and next chair are on the left side
previous chair on right side and next chair on left side
previous chair on left side and next chair on right side
For S chair:
next chair on the right
next chair on the left
For E chair:
previous chair on the right
previous chair on the left
You can use dynamic programming to solve it keeping in mind that the cost of jumping from a chair and landing on another just depends on the direction
You can see my submission here
You describe the status by using dp[i][left_go],but there are three arguments:i,left go and sit right,how can you make sure that the status are the same?
In 1B or 2D, what I overlooked was the constraint "1 ≤ x1 < x2 < ... < xn ≤ 109". After reading the editorial and checking many solutions I still couldn't understand why the applied approach is correct. Reading the question again explained everything. Just posting about this in case someone else is stuck with something similar. BTW, nice question! Thumbs up!
How does this help? With sufficiently large values for Ai-s, Bi-s, Ci-s, and Di-s, won't Xi-s get abstracted away?
Because of the condition for this problem (not just the constraint mentioned above), you can know exactly what is the cost to add a new vertex into existing path only by knowing the unconnected endpoints, and without knowing which vertices this new vertex connected to -> solvable in polynomial time.
Can anyone please point out what's wrong with my approach for DIV2 D for this contest. I have been trying to find the minimum time from source chair to all the other chairs initially (except end). After iterating over all the chairs I update the source node with the label for the chair which resulted in minimum time.
This is my submission
can somebody please tell me why the 10 line of judge's answer in test case 4 of problem A (DIV1)
is '3' shouldnt it be '4'?