


Congratulations to all those who have cleared the SnackDown Pre-Elimination Rounds and advanced to the SnackDown Elimination! An intense competition is about to begin where only the top 52 teams will move on to the SnackDown Onsite Finale.
The Elimination Round will have an ACM ICPC style rank list. As mentioned above, 52 teams (Top 25 Global + Top 25 Indian + Best Girl’s team Global + Indian School team) will be invited to the onsite finals. While the top 32 teams (15 each Global & Indian + Best Girl’s team + Best Indian School team) will get an all expense paid trip to Mumbai, India, the remaining 20 teams will be provided with accommodation and local travel in India. However, if any of these 20 teams win the competition, their travel fair will be reimbursed as well. It’s a win-win situation.
Also, top 300 teams will be getting SnackDown 2016 merchandise from CodeChef.
The CodeChef SnackDown 2016 Elimination Round begins at 19:30 HRS IST, 19th June.
The problems have been set and tested by kevinsogo (Kevin Charles Atienza), Antoniuk (Vasya Antoniuk), CherryTree (Sergey Kulik), kingofnumbers (Hasan Jaddouh), PraveenDhinwa (Praveen Dhinwa) and the translations are written by huzecong (Hu Zecong) for Mandarin , VNOI Team for Vietnamese , CherryTree (Sergey Kulik) and Antoniuk (Vasya Antoniuk) for Russian, with PraveenDhinwa (Praveen Dhinwa) as contest admin and grammar verifier. I hope you will enjoy solving the problems. Please feel free to give your feedback about the problems in comments below.
Hope to see an exciting competition in the SnackDown Elimination!







Gentle Reminder !! Contest starts in 5 minutes !!
How many problems will be there
Please wait for a little more time !! You will find yourselves :)
5 authors, so by the pigeon hole principle atleast 5 problems! :D
How to solve Coloring a Tree ?
Iterate over the number of colours you use (let it be x). You fix the colour of the root. Then you simply choose x-1 vertices out of n-1. And multiply it by ncr(k, x) * x!. Sum up the values for all possibilities of x, ranging from 1 to k. :)
Thanks. Got it. Can this also be done by defining a recurrence.
Remove X edges, you get a forest of (X + 1) trees. To color these (X + 1) trees, we need to use (X + 1) different colors.
There is C(n — 1, X) ways to choose X edges, A(k, X + 1) = C(k, X + 1) * (X + 1)! ways to assign (X + 1) colors to these trees.
So the answer is Sum(C(n — 1, X) * C(k, X + 1) * (X + 1)!) for all X from 0 to min(n, k) — 1.
I use a recurrence in this method too, to calculate ncr(n, r) using the formula ncr(n, r) = ncr(n-1, r) + ncr(n-1, r-1).
dp(n)(k) = dp(n - 1)(k - 1) * k + dp(n - 1)(k)
Let there be tree of length n-1 , now to attach any leaf you can give it a unique colour with the first term and change it colour to the node to which it is going to be attached.
That is why I was surprised why were the constraints so low!
Can you share your code
What is the complexity of rwalk
Subset sum. O(N * MaximumPossibleSum)
I got TLE , same complexity! :(
Mine passed in 2.12 s. Border line?
mine solution also get tle :/ same complexity. i have also optimized space by making dp array of boolean[2][sum]
You can improve that by a factor of two.
can you plz explain how?
Since you know the total sum, once you know the sum of the positive terms you can calculate the sum of the negative terms later.
you may use boolean[sum] if you go right-to-left
If author sets 50 tests with maximum contraints, I think many accepted submissions will fail!
Exactly. Because of this constraint I thought we must solve problem with a probabilistic solution !!! I shuffled array 1000 times and find the min solution !!! After I couldn't get ACC , I switched to DP solution and it got ACC!
Now , Codechef servers are so fast or tests were small ?!
u can make it 32 times faster with bitset
can u elaborate a little bit
you case use sum/32 integers and check whether particular value is true or false by checking that bit is 1 or 0 .suppose u want to check 56 is true or false then u check 24th bit of 2nd integer because first 32 are in 1st number next 32 are in 2nd number etc...
How does this make solution more time efficient? Wouldn't it just decrease memory consumption by a factor of 32?
yes,boolean takes 1 byte while using int you can save memory of 7 bits.
bitset can do and , or , xor operations in O(N / 32).
So knapsack dp can be done like:
Can you share your solution?
code
In knapsack you will store weights of each knapsack in arr[i]. How will store the value(profit) you get from that particular weight?
Please move the problems to practice ASAP.
When will the editorial get posted? Great Problems BTW, was only able to solve 3.
We will have a replay on Monday. Editorials will be posted afterwards.
They will be moved to practice after monday then?
Why are solutions not public ?
Replay not mentioned on codechef website
Problem "Yet Another SubSegment Sum Problem" uses persistent segment tree is the same as a problem in Russian Code Cup.
It can also be done by using a merge sort-tree and binary search.
Can you please explain how?
You need the sum of A[i] and B[i] where l ≤ i ≤ r and A[i] / B[i] ≥ D / C , now lets sort the array by nondecreasing A[i] / B[i] , and assign rank[i] = position of i when sorted according to A[i] / B[i] . So now you have points {i, rank[i]} with Values A[i] and B[i] . You need to precess queries in a subrectangle which can be easily done with persistent segtree.
To do it without persistent segtree , Build a segtree with a vector in each node , Lets say segtree is on the index and the vector is sorted according to the ranks , now in segtree query , just make a binary search on the vector in segtree node and return the sum.
How will keeping a vector in each node of segment tree not exceed memory limit?
It's O(nlogn) in memory.
Why stack in codechef is too tight? In problem "Alliances", dfs with recursion will get RE!
We had included a note section specifically for this reason. We will try to get the stack size increased though.
Yes, but once you notice it (which wasn't easy — putting note at top and bolding it would help), the fix is trivial. Just google "codechef stack size", and you find out that you're allowed to perform setrlimit() call.
Anyone knows how to solve NUMSET?
I did this and got WA, then found my mistake after contest. I don't know if it is right or not.
We will take all numbers greater than 31 which are prime(at most once). Now we are left with 2 types of numbers, 1.) Those less than or equal to 31 and 2.) those which have 1 prime greater than 31 and others less than or equal to 31 in its prime factorization. Lets call this prime which is greater than 31 in the second kind of numbers as big prime. Now we can do a bitmask DP in which we either take a element or not take it. There is an additional condition, we can take only 1 element from all numbers which have the same big prime. And if we take a number, we set the corresponding primes less that 31 in our mask.
First, notice that any number is divisible by at most one prime larger than 31. For each prime larger than 31, create a bucket of all numbers divisible by it. Also create a separate bucket for number not divisible by any of them. Now for the primes less than or equal to 31 (there is only 11 of them), use dp + bit mask. If you used a number add the mask of the primes less than or equal to 31 that divide this number and go to the next bucket (except if it's the bucket where the numbers are not divisible by any prime larger than 31).
Hope this helped.
I was thinking of maximum clique problem
Verdict: WA.
I considered primes less than 1000 (168 of them) and then considered all a[i]'s as single element such that prime divides a[i].
example: 2 2 7 7 12
loop from 168th prime till 1st prime and check.
prime 7 divides 3rd and 4th so our array becomes : 2 2 1 1 12 and cur_ans = 1.
prime 2 divides 1st , 2nd , 5th so our array becomes : 1 1 1 1 1 and cur_ans = 2.
I don't know why this does'nt work. I got WA with this approach.
Complexity: O(168*n)
Do you really hope to solve NP-hard problems in polynomial time ;)?
Sometimes in special graphs it is possible.. Did you try using Strzelecki's method in this task?
It seems that methods named by polish high schoolers are not spreading that fast :P.
I don't even know this :C
Yeah, my comment was my way of saying the same :P.
What is Strzelecki's method?
counterexample: 2 3 30
Counterexample for what? For well known and approved method? Are you joking? ;)
Relax kpw29. He gave counterexample to my naive attempt in solving NUMSET.
http://codeforces.me/blog/entry/45516?#comment-301316
Ahh, okay. Strzelecki's method is incorrect, too ofc. But for trolling it's a "well known and approved" way of problem solving. There was a guy who solved Swistakk's task on Polish OI using a linear clique finding (and got a 100).
My precious task ;__;... That was a real bummer for me to hear that many heuristic solutions passed since I personally consider that task as one I am most proud of :<.
First add prime numbers to the set, then random_shuffle and greedy algorithm. Solution accepted :)
Can you provide your code
How to solve ARITHM?
My approach is not so clean but this is how I did it:
If n is odd, then the progression looks like ... a-r a a+r ... as you can see, the sum of the progression is a*n. So a=C/n, and a-(n/2)*r>0
If n is even, then we have something similar: ... a-r a+r a+2*r ... a+(n/2)*r, the sum of the progression is an+(n/2)*r, so 2*a+r=(2*c)/n, we should also check that the first element is positive.
Given sum, we need to find some positive start and delta, such that:
If answer exists, then delta is either 1 or 2.
Can you explain how the delta is only 1 or 2 if solution exists?
If the first person gets a candies and the delta is d, the sum is equal to a*n + d*n*(n-1)/2. If in some solution, the delta is k for k > 2, we can also find a solution with a delta of k — 2. This will decrease the sum by n*(n-1), which we can make up for by increasing a by n-1. We can keep applying this to decrease the delta by 2 at a time until the delta is either 1 or 2.
If you manipulate with the the standard AP sum formula, it is easy to see that we basically need to find a(first value) and d(common difference) such that ((2·C) / n - (n - 1)·d) = 2·a. So basically you need to come up with d such that ((2·C) / n - (n - 1)·d) is divisible by 2 and ((2·C) / n) > (n - 1)·d). This can be done using some simple if else based on parity of ((2·C) / n) and (n - 1)·d. You can see the code for the conditions, they are straightforward.
We know that the sum of an A.P. can be written as (n/2)*(2*a + (n-1)*d) = c ,
So rearranging terms we get 2*a + (n-1)*d = (2*c/n) , if (2*c isn't divisible by n) , answer is NO.
So, the problem amounts to checking if it's possible to get a >= 1 , d >= 1 integers, such that 2*a + (n-1)*d = (2*c/n) , this could be easily checked by taking gcd of (2,n -1) and using extended euclid's.
what is the meaning of "-1.00" running time in WA verdict of SEGSUMQ?
I asked the same in comments but got no reply, hence asking here.
I got confused that there might be some problem/bug with flushing of output, since it is an interactive problem.
its TLE
But why does it show WA?
Spent a lot of time trying to find bug.
Note : later I changed from pairs of long long to double implementation, and got AC.
It seems, after you add
ios_base::sync_with_stdio(false); cin.tie(0);into your codefflush(stdout)will cause problems? Our team lost 8 TLE submissions because of this. In despair we changed our code intocoutcommands withendland it magically got AC... What the hell.This happened with me as well. I changed it to scanf() and it passed :/
because of cin.tie(0) all the answers will be displayed at the end not after each query thats why you got tle.
it's ok as long as you flush
kinda logical not to expect synchronisation when you explicitly turned it off.
I am getting TLE for RWALK .My approach is O(N*Sum)? http://ideone.com/MdgKiX
OMG! I wasted more than 2 hours fighting with RTE because I was so reckless that I ran DFS! And of course there was a limit on stack -_-. Guys, are we in 20th century? First time in my life and in pretty long competitive programming experience where I actually suffered from stack limit xd. Moreover I used some method of getting rid of it which worked locally, but gave instant RTE on platform xd. Fortunately second method of getting rid of it worked, but at that moment contest was completely wasted for me.
Btw is there really some faster way of solving cubes than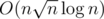 which gave TLE for me?
which gave TLE for me?
Our solution is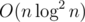 I believe
I believe
So naturial question coming after such statement is "Could you describe your solution?" :). I used a fact that there are at most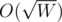 different lengths of favourite words (where W is of course summed length of all favourite words) and using that we can even enumerate all possible occurences. I gave it a shot since if we are not allowed to enumerate occurences then this problem is very probably far above my skills and uses some suffix shit, so it was the only possible way for me to solve it :p.
different lengths of favourite words (where W is of course summed length of all favourite words) and using that we can even enumerate all possible occurences. I gave it a shot since if we are not allowed to enumerate occurences then this problem is very probably far above my skills and uses some suffix shit, so it was the only possible way for me to solve it :p.
If I knew the solution I'd descrive it but I know just bunch of keywords: aho-corasick, tree of suflinks, 2d-segtree.
You may ask Kostroma for details
We passed by enumerating occurrences in a little over 2 seconds (time limit is 3). Did you use BITs?
Yes, I used BITs. However I couldn't make separate static array for every favourite word, because that would result in MLE, so I chose to implement them using unordered_map. Using typical map would make my solution be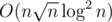 and technically unordered_map gives access in expected O(1), but constant factor is large. Was there way to make it more clever?
and technically unordered_map gives access in expected O(1), but constant factor is large. Was there way to make it more clever?
For each word, make a list of all the towers which contain it. Then you can use a BIT on those towers only. You have to do a binary search to find the actual left and right indices for each query, but that only adds a constant factor.
OK, I'll try. Build Aho-Corasick on interesting strings and maintain the states in which the end of each of n strings is currently situated. The idea is to consider only occurrence of the longest interesting string ending in that position.
Let's build the tree of suffix links T for our automaton. After appending a symbol to some string, we move the pointer to the state in automaton and consider the longest interesting string ending there. Then add 1 to the value in state corresponding to this string in automaton. To obtain the sum of occurrences of some string, we should take the state corresponding to it and find the sum of values in its subtree in T. So we can represent the tree T as its euler tour and build a segment tree on it, one for each of n strings Si.
OK, then we can notice that there is no need to build this trees separately for each of n strings, we can build T once and for each Si use only vertices, in which some values are added for Si — so we build online segment trees for each string containing only useful vertices. Then we can also merge these structures to obtain a big segment tree on them, the overall memory we need will be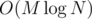 , if we have M appends overall. In fact we don't merge structures, but add the value for all segment tree vertices from the leaf to the root. So, now we can answer the query of type 3 in
, if we have M appends overall. In fact we don't merge structures, but add the value for all segment tree vertices from the leaf to the root. So, now we can answer the query of type 3 in 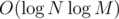 time. The update on the query of the 1 type takes also
time. The update on the query of the 1 type takes also 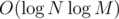 time.
time.
To answer the queries of type 2, we need to build the similar segment tree, but after adding 1 to the vertex corresponding to the current maximal interesting string of Si, we need to add -1 to the deepest ancestor of this vertex, having some descendant which already was increased for Si. It is not that hard to find this vertex, using the idea of the task Alliance.
Mine solution with similar complexity passed (with treap for BST). It used hashes also. So those scary things with Aho-Corasick, 2d-stree and other complex stuff were not mandatory
How do I upsolve?
After they move the problem to practice, remove the contest code name (in this case SNCKEL16) from the url to get the practice version.
One waits for them to add problems to practice.
They have replay contest today After that go to same problem and remove SNCKEL from url to go to practise version of same problem
Someone please provide his code for NUMSET...
Code
The solutions for this contest have been made public and problems have been moved to practice section.
Editorials can be found here
https://www.codechef.com/problems/COLTREE This problem is still not visible?
The problem is now visible.
If the intended complexity of RWALK was O(N*sum) as given in the editorial, then why were the constraints set so high? What is the point of forcing contestants to fit the solution in TL by reducing constant factor? I spent a lot of time trying to find an asymptotically better solution during contest, thinking this wouldn't pass.
I faced the same issue during contest and this wasted some 20-25 minutes of mine, trying for a better approach. I finally gave up and tried this one expecting TLE, but it passed. The constraints should reflect the intended complexity more appropriately. :\
Can someone explain the logic behind hitting closest to sum/2 in RWALK problem
in Egor solution : https://www.codechef.com/viewsolution/10541898
I couldn't get the intution behind " return sum — 2 * i; "
EDIT: GOT IT . It is balanced partition problem http://people.csail.mit.edu/bdean/6.046/dp/dp_4.swf Leaving it for reference for others