



Сегодня, 25-го апреля в 18:00, начнется VK Cup 2016 - Уайлд-кард раунд 2.
Участникам раунда будет предложено максимально продвинуться в решении одной сложной и необычной задачи. Официально в этом раунде смогут принять участие команды чемпионата VK Cup 2016, которые прошли в Раунд 2, но не оказались среди тех топ-100 лучших по его результатам, кто проходит в Раунд 3. Кроме того, этот раунд будет открыт для всех желающих для неофициального участия вне чемпионата. Зарегистрироваться на раунд можно будет в любое время пока он идет.
Продолжительность раунда — одна неделя. После ее окончания мы выберем последнюю попытку, набравшую положительный балл, каждого из участников и проведем финальное тестирование.
Удачи!
UPD 1: К сожалению, выяснилось, что большинство текущих тестов были недостаточно разнообразны и не покрывали различные сценарии работы тестирующих систем. Тесты в системе были обновлены, все решения будут перетестированы. Возможно, процесс перетестирования займет существенное время. Кроме того, была обновлена функция начисления баллов (её монотонность сохранена). По этой причине порядок начисленных баллов уменьшился. В условие добавлено ограничение на количество попыток (до 20000). Ознакомьтесь с обновленным условие задачи для выяснения подробностей.
UPD 2: Системное тестирование завершено. Поздравляем победителей! Напоминаем, что лучшие 20 команд будут приглашены в Раунд 3, который начнется 7 мая в 18:05.
UPD 3: Тестирование завершено! С учетом дополнительного тестирования, следующие команды завоевали право участия в Раунде 3:
- Geisterkirche, aan93
- komendart, zloyplace35
- Arthur, Ferathorn
- slava.sh
- Lo_R_D, vas.and.tor
- mHuman, stas99
- pashaD4RW1N, krock21
- Kaban-5, pavel.savchenkov
- magnickolas, sslotin
- BotanIQ, agsagds
- sergileon, Auster
- reconst, Raven_gg
- Naduxa, DimonK
- Infoshoc
- KingArthur, awoo
- WiBk, alex700
- Jace_Beleren, Jovfer
- diko, Omrigan
- jvmusin, NikitaMikhaylov
- MrDindows, I_love_Tanya_Romanova
- nijikilling, maxplus
- aytel, kokokostya
- kuzmichev_dima, Timur_Keks
- tyamgin, Sokolov
- Mogby
- alex_chukharev, dashakisik
- alex.tsitsura
- WasylF, stostap
- passick, yurboss







Это мой первый Уайлд-кард раунд,поэтому,пожалуй,спрошу:"Раунд будет рейнтигованым?".
Нет.
Как можно отослать архив ?
Вы можете выбрать в качестве языка решения C++ Zip / Java Zip
Что значит
Ожидается корректный ZIP-архив? Какой архив считается корректным ?Как генерируются/откуда берутся входные данные?
Данные взяты из настоящих данных тестирования Codeforces, используются попытки по задачам идущих контестов и задач из архива. При экспорте использовались промежутки времени продолжительностью в 1-6 часов. В качестве тестов к этой задаче мы старались подобрать такие времена, которые соответствуют различным сценариям тестирования (во время соревнования, дорешивание, проверка множества авторских решений и т. д.).
1000 тестов на задачу — не очень похоже на реальные архивы.
А разве в реальности, если решение падает на тесте, то остальные тесты не должны игнорироваться?
"В реальности", как правило, проверка ведётся на всех тестах до первого теста, на котором решение упало, дабы как-то сепарировать причину падения (чисто для статистики, надо полагать) и для демонстрации участнику прогресса/регресса по задаче (не принёс ли фикс бага какой-то другой баг).
А вот тесты после того, на котором упало — да, обычно игонорируются, (особенно в случаях, когда правила ACM)
Да, игнорируются. Специально для этого соревнования мы реджаджили в режиме "тестировать на всех тестах" все попытки в избранных промежутках времени.
Прочитал условие, интересует 2 момента:)
1) это первая интерактивная задача на КФ (как мне кажется), стоит ли ожидать их на грядущих контекстах?)
2) если решения участников планируется использовать для ускорения тестирования на КФ, то зачем такое большое ограничение на количество задач?
UPD: наверно большое количество задач будет имитировать режим дорешивания.
VeeRoute был в таком же стиле
Что означает в семпле в выходных данных два подряд идущих -1 :
-1 -1? Как вывести мое желание не тестировать ни одно решение ни на каком тесте ?И как понять, что
все вердикты в данном тике были получены от интерактора?каждый тик вам приходит список вердиктов накопленных с последнего тика, список заканчивается строкой "-1 -1"
Допишите, что надо выводить "-1 -1", если нет намерения ничего тестировать.
Where is the tutorial for round 2 ?
Moscow time is not UTC, by the way.
Thanks for editorial, I just saw it.
##########################################
Думаю для подобных контестов имеет смысл добавить возможность отклонения решения (к примеру когда отправил решение а потом понял что оно зацикливается и будет постоянно упираться в тл), и возможность переключатся между несколькими (2) наборами тестов, к примеру маленький набор тестов (для поверхностной проверки решения, проверки времени выполнения) и полный набор тестов. Тогда появится возможность быстро узнать приблизительный вердикт не ожидая прогона всех тестов.
Ну вообще, и та и другая проблема должна решиться с появлением пакета для локального тестирования.
Подскажите, правильно ли я понимаю условие:
Считается, что решение протестировалось целиком, если оно было протестировано либо на всех тестах задачи, либо, если задачи решена не полностью, протестировано на всех тестах до первого вердикта RJ (включительно).Пример: Задача решена не полностью, проходит тесты с 1 по 5, на 6 тесте валится. Пусть, если бы задача проверялась на тестах 7-10, то завалилась бы на 7, 8, 10, а на 9 бы прошла. Тогда имею ли я право проверять задачу например в таком порядке (метка (x) означает, что решение не прошло тест): 9, 5, 3, 7 (x), 1, 2, 6 (x), 4?
В итоге, как и требуется (если я правильно понял требования), задача протестирована на всех тестах вплоть до первого RJ (а именно 1, 2, 3, 4, 5, 6).
Интуиция подсказывает, что авторам обычно выдают вердикт в духе RE#x, где х — первый тест, не пройденный решением, так что если решение завалилось на 7ом, проверять тесты после 7го не обязательно, но убедиться в том, что все до 7го проходит, надо
Хотелось бы услышать однозначный ответ организаторов на этот счёт.
А в чем там собственно вопрос и неоднозначность? Вроде как это условие весьма четко сформулировано.
Что понимается под фразой "протестировано на всех тестах до первого вердикта RJ"? На всех тестах по порядку от одного до текущего или на всех тестах от того, с которого начал участник и до текущего? Конкретнее: если решение упало на 7 тесте, должно ли оно быть протестировано на тестах 1-6? Если второе, то важен ли порядок тестирования?
Очевидно, на всех тестах по порядку их нумерации, а не того, как вы скармливаете их инвокерам.
И почему это должно быть очевидно?
Многолетний олимпиадный опыт подсказывает =)
С точки зрения реального опыта — это очевидно, но по условию это никак не запрещено, и даже очень выгодно делать.
Я вот потратил кучу времени, чтобы понять почему у меня не проходит второй тест, добавив тестирование "не по порядку до первого RJ". Дескать я не все задачи протестировал.
Да, именно так.
Вы можете тестировать в любом порядке, главное, чтобы решение было протестировано на всех тестах до первого RJ в порядке нумерации тестов. Например 0-OK, 1-OK, 2-OK, 3-RJ. В каком порядке вы получили эти вердикты, и получили ли вы лишние вердикты для следующих тестов — неважно.
Слишком много -1
Можете задать какие-то ограничения на количество решений, которые программа получит в ходе одного теста, и на количество тактов до последнего принятого решения? Заранее спасибо =)
Жюри может запостить сэмпловое решение, которое набирает хотя бы один балл? Стыдно, но мы что-то не можем разобраться с форматом взаимодействия с системой (при том, что фидбэк приходит спустя ~20 минут).
3 основных момента (у меня валилось на 3ем):
конец списка новых задач помечается -1;
конец списка вердиктов помечается -1 -1
в конце вашего вывода обязательно нужно вывести -1 -1, после чего сделать flush
Is this round rated or unrated?
Probably unrated since it is not an usual round.
Задачи и решения — это одно и то же, или нет? Может быть несколько разных решений на одну задачу?
Да, может. Каждая посылка имеет свой id который равен колву посылок что произошли раньше, и id задачи на которую отправлена. В первом примере это видно
Задача и решение — разные вещи. Люди отправляют решения задачи, а система определяет, прошло ли решение тесты или нет.
Добавьте возможность отсылать несколько файлов на Go, пожалуйста.
Написал решение, дабы проверить ввод-вывод
Временно отключена возможность посылать решения VK Cup 2016 — Уайлд-кард раунде 2.
Давайте поможем Даше провести VKCup...
Второй день мучаюсь с решением на Java 8 ZIP. Только что посмотрел Статус и не смог найти ни одного решения с данной опцией, которое бы набрало больше 100 баллов после того как включили отмену выполнения после первого упавшего теста. Есть такая проблема или мне показалось?
Я думаю, что интерактор для джавы, считает вместе с временем участника еще и частично свое время, я засекал суммарное время между моментом времени как я отвечу flush на очередной запрос, и приму первое число из следующего запроса (это я считал за время, которое работает решение жюри). И для второго теста ассерт срабатывает, решение жюри съело 15 секунд, мое решение съело менее 6.2 секунд (около посылки показано ~12секунд)
PS: Я могу конечно же ошибаться, но все же лучше, чтобы жюри проверили свой интерактор, и прокомментировали, что все ок/не ок на их стороне.
Решение на 2000 баллов со всех тестов это ведь шедулер жури? Может, его опубликовать как пример?
Когда будет доступен пакет для локального тестирования?
Приношу извинения команде Codeforces за свои злые слова в сторону скорости тестирования. Писать шедулер — не мешки ворочить, как оказалось...
Не знаю, что не так с моим кодом, но решение с
printf("%d %d\n", -1, -1);набирает положительные баллы, а решение сprintf("-1 -1\n");набирает ноль, из-за нехватки памяти. Да... Это какая-то мистика...Что значит "ТЕСТЫ пронумерованы в порядке их появления"? В порядке появления где?
Если я начинаю тестировать с последнего теста, то он останется под последним номером?
Странный вопрос. Тесты пронумерованы от 0 до testN - 1, где testN — количество тестов задачи. А решения пронумерованы с нуля, в порядке появления. Это же логично.
Я вижу, что многие застревают на втором тесте по TL. Есть ли кто-нибудь, кто нашёл причину?
Причина: этот тест самый большой в наборе. Используйте быстрый ввод/вывод.
У меня одного интерактор работает безбожно медленно, а потом выдает страшные цифры, вроде этих: ok Finished in 7197110 ms ?
Эти цифры означают, что ваш шедулер получил вердикты по всем посылкам за 7197110 миллисекунд — 719711 тиков.
Все равно не знаю как на Linux, на Windows он работает дичайше медленно. Или интерактор работает совсем точно? другими словами, реально "ждет"?
Что значит вердикт IDLENESS_LIMIT_EXCEEDED?
Обычно это означает бездействие программы (например, ожидание ввода с клавиатуры)
Спасибо, что не за день до конца раунда.
Семплы совпадают (будут совпадать) с первыми 10 тестами в системе?
Можно ли ожидать, что финальные тесты качественно не будут сильно отличаться от текущих?
10 тестов в системе совпадают с тестами из архива с интерактором? Есть ощущение, что нет, т.к. локально интерактор тестирует все без ошибок, на сервере же WA 3. Или может отличается то, как работает интерактор?
Такая же проблема! Прошу обратить на это внимание. Все мои посылки до обновления работали и проходили 20 тестов, сейчас же wa3 и никаких идей, что бы это могло быть.
Я выяснил, что в моем конкретном случае это был баг, который локально не всплывал, а на кф как раз проявлялся. Но это означает (скорее всего), что предоставленный в архиве интерактор отличается от того, что на сервере. Плюс я имею разное количество баллов за некоторые тесты у себя локально и на сервере -> отличия в области генерации рандома?
А где в этой задаче рандом?
Поддерживаю вопрос. Локально всё работает, на сервере memory limit.
Когда будет обновлённый локал раннер? За час до конца?
В архиве с интерактором второй(а может и не только второй) тест багнутый. Там в одной задаче 0 тестов. Надеюсь, на реальных тестах такого не будет:(
...
2000 40
2000 43
2000 49
2000 59
1000 29
2000 0 // вот тут
1000 54
2000 29
2000 34
1000 36
...
Не проверял, но если это так, то мне все больше и больше нравится этот Уайлд-кард
В коде интерактора есть проверка на это.
Спасибо, значит я криворук, не заметил строчку
Стоит ли ожидать, что финальные тесты будут примерно аналогичны претестам по времени работы? Если нет, то что стоит ожидать? Очевидно, что решение, которое может протестить 20000 сабмитов, работающих по 1000 тестов каждый, невозможно написать, поэтому формальные ограничения из условия почти бесполезны и наверняка макстеста по ним нет.
Все тесты будут взяты из реальной жизни реальных сценариев работы Codeforces. Но количества инвокеров будут разнообразны, как и сценарии. Некоторые мы смоделируем синтетическим образом, например, пошлем почти сразу много авторских решений по большому число контестов.
А в случае таймлимита или какого-нибудь другого лимита тестирование будет прерываться?
Будем тестировать на всех тестах.
Будет ли доступен сам набор финальных тестов после проверки? Пусть не для тестирования на сайте, но хотя бы для локального. Чтобы можно было сравнить различные свои решения и понять, правильный ли мы сделали выбор, не заслав нелогично работающее решение, но берущее больше баллов.
Вопрос все-таки был не про разнообразие и способы генерации, а про объем тестов и, по сути, отсутствие формальный ограничений.
Например, сейчас в максимальном претесте (втором) 1 инвокер, 170 задач и всего 3011 посылок. Думаю, что в реальной жизни реальных сценариев Codeforces были ситуации с похожей структурой, но с в 2 или в 3 раза большим количеством посылок. Если эти случаи включить в финальные тесты, то подавляющее количество решений просто получит TL. К тому же, не зная ограничений, нельзя написать решение, которое всегда будет успевать отрабатывать, так как данные поступают в потоковом режиме и никак не узнать заранее количество посылок, которое придется обрабатывать.
так нам никто не скажет ограничение на суммарное количество тестов по всем задачам? (хотелось бы увидеть число меньше 10 000 * 1 000 = 10 000 000)
Понимаю, что я наверняка немного отстал от событий (только сегодня появилось время посидеть над задачей). Есть вопрос, почему решение получает 100 балов? Никакого TLE или ML нету.
Скорее всего вы не до конца тестируете решения.
то есть?
Я просто отправляю задачу кнопкой "Отослать".
Имеется в виду не до конца тестируете посылки (из задачи).
Все, понял, спасибо большое :) Жаль только, что поздно спросил.
Откройте коды других участников, пожалуйста. Очень не терпится посмотреть магию топовых участников. :)
интересен скорее ход мыслей и сам вид оптимизаций
Как думаете, насколько в этом году топ изменится?
Думаю, очень сильно.
Мое "топовое" решение теряет очков 200 при совсем незначительном изменении некоторых констант =)
Можно код, пожалуйста? =)
Я не топ, но вот такое решение набирает 3300 очков — сначала отсылаем по 1 тесту от всех нетестированных попыток, а затем все подряд у кого TL меньше, пока есть свободные инвокеры
Это плохая черта нелинейной шкалы рейтинга, вводит в заблуждение. (До того как сделали реджадж было нагляднее, ИМХО) Мне кажется даже решения 3500 и 3300 на самом деле отличаются на качественном уровне.
UPD. После того как открыли коды, обнаружились большие залежи магии в константах у многих в топе, видимо на финальных тестах действительно может все сильно поплыть.
Отсылаем тест на посылку, у которой в тестировании на данный момент находится наименьшее число тестов. Если таких несколько, то выбираем наиболее раннюю посылку. Такое решение безо всяких коэффициентов и подгонки набирает почти 3600 баллов.
3510 примерно, если я правильно помню свои попытки.
3592.389 баллов, если быть точным. submission/17691303.
А когда будет финальное тестирование?
Работаем над этим. Codeforces по-теневому продолжает скрытые перетестирования, чтобы собрать статистику для тестов. Я надеюсь запустить всё сегодня ночью.
Такой рандом можно просто объяснить тем, что были тесты гораздо более толстые, чем тест #2 на претестах, и по сути, выжили лишь те решения, которые были быстрее. Если глядеть статус попыток, половина(UPD: видимо даже больше) имеет время 15000 мс. Вообще, я не в том положении, чтобы негодовать или не радоваться, но это довольно неприятно, когда нет нормального представления во время тура о том, какого размера будет самый тяжелый тест, ясное дело, что кейс с произведением максимальных чисел солюшенов и тестов выглядит непроходимым и на него нельзя ориентироваться.
Более того, джаву кажется поставили в нереальные условия. Позже перепишу наше достаточно быстрое решение (как мне казалось) на плюсы, если будет дорешка. Более 15с может быть у плохих решений из-за не оптимальный стратегии. И у джавы, возможно у практически любого решения. Хочу сравнить например свое (джава/плюсы), у меня подозрения что 14 ТЛ тестов превратятся в меньшее количество. Наше 9 старое место получило именно столько ТЛ. Следующая серьезная заявка джавы — 21 место по-старому. Сейчас получили 68 и 67 место с примерно равными баллами, так что думаю у ребят ровно те же 14 ТЛ. Интересно посмотреть на таблицу без ТЛ за ввод...
+1, не зря же мы с Kaban-5 выше пытались прояснить ситуацию с временем работы. В итоге за что боролись, на то и напоролись -- ограничений так и нет, много TL-ей, как можно было понять, что решение медленное, если оно на претестах работало адекватное время, непонятно. У нас правда на C++, но довольно громоздкое, есть константы, напрямую влияющие на время работы. В конце мы решили, что раз про финальные тесты ничего не известно, то не будем париться и оставим посылку с временем 10 секунд на 2 тесте.
P.S. мы в английской ветке
У нас я считал r * s * log (s) с маленькой константой и джавой. Если я не просмотрел багу. Где r количество посылок, s количество активных посылок — которые уже поступили, но еще не обработаны. Худший случай, синтетический, и то должен был бы уложиться в 10 секунд, но вычитать данные для худшего случая мне кажется не реально. Поэтому мы ориентировались на 2 тест как на макстест и оставляли запас.
У нас видимо на каждом тике происходит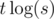 операций с большой константой.
операций с большой константой.
Все-таки хотелось бы услышать мнение администрации на этот счет. Например, я считаю, что пусть не для прошедшего соревнования, но для подобных случаев, когда не указано явных ограничений + финальное тестирование происходит на сервере + данные поступают в потоковом режиме, единственным разумным выходом является позволить тестировать посылку на финальных тестах без указания количества баллов раз в X минут или часов.
Или найти способ выкинуть ввод вообще или из учета времени. Второе не знаю, возможно ли, но мне кажется должен быть способ.
Ну я говорю не только про ввод и джаву, а (пишу одно и тоже уже 4-й раз), про отсутствие ограничений и невозможности гарантировать успешное выполнение кода на тестах, которых жюри посчитает адекватными.
Перечитал Ваше первое сообщение, согласен полностью. Макс тест, по-моему, не реально просто считать на си со всеми оптимизациями. Так что да, не на что ориентироваться. И многие решили что можно на 2 тест ±.
Everything has changed again. Will we be updated when standings are final?
It's all in God's (or Misha's) hands.
Добавьте, пожалуйста, возможность протестировать другие свои решения!!! Очень интересно сравнить:)
Для избежания высоких нагрузок на кф, можно просто ограничить кол-во попыток для участника в день:)
А на претестах работало максимум 9 секунд.
Интересно, а само решение Михаила Мирзаянова прошло бы финальное тестирование? Он ведь сам на Java пишет.
Дык авторское решение вроде как не было оптимальным по договоренности. + в джаве как и везде все зависит от ввода. я так понимаю, львиная доля времени — чтение....
А решения внеконкурсных участников потестированы не были?
По-моему у меня остались баллы с предварительного тестирования и никого со здездочками в топе я не увидел
Да, упустил этот момент. Конечно, сейчас запущу тестирование.
Апеллировать по поводу нереального ТЛ для джавы бесполезно? Или можно придумать компромисс? Две команды из "топа" пострадали похоже.
Более чем две.
На джаве вроде всего 4 финальных попытки. Поправьте если ошибаюсь.
Господа минусующие, а пояснить позицию?
Все знают что джава медленнее? Да, но это официальный язык. И это значит, что на ней надо писать аккуратнее, а не то, что вообще не использовать. Тем более тут даже подчеркнули, что можно использовать, введя Java zip как вариант посылки.
Плюс на моей памяти (последние пять лет) это первый прокол в установке ТЛ под руководством Михаила Расиховича на официальных контестах. Собственно когда обсуждали на чем писать внутри команды, финальный аргумент был что-то типа "Мирзаянов контролирует, не будет хрени с ТЛ для джавы". Избаловали нас качеством саратовского ЧФ.
Сергей, по TL решение упало у 61 команды из 106. Т.е. пострадали 58% участников контеста. И мы оказались в их числе, хотя наше с Geisterkirche решение работало всего 5 секунд на 2 претесте. А мы специально переписали код с Java на C++ и выкинули все элементы алгоритма, заметно замедлявшие программу, но укладывавшиеся в TL по 2 претесту.
Даже не знаю, какой компромисс можно предложить в данной ситуации.
Понимаете в чем штука, на джаве 10+ тестов похоже вообще не возможно вычитать. Хотя это гипотеза, дорешки пока нет. Изначально такой жести по ТЛ не анонсировалось. По-хорошему надо было предупредить, что финальный набор тестов будет в разы жестче. И предупредить, что джаву для серьезной попытки брать не стоит, так как не придумали, что делать с таким количеством ввода-вывода.
Сейчас было бы уместно позволить 4 командам реджадж со сменой языка и старым алгоритмом без каких-либо оптимизаций. Ибо перекос по времени работы получился не реальный.
PS: Кстати, было бы интересно посмотреть вашу статистику по тестам.
а правда на счет "фирменной футболки"? (здесь должен быть стесняющийся смайлик) А куда её пришлют? Вероятно сюда. Я и забыл об этой странице :)
Будет ли возможность дорешивания ?
Большое спасибо за интересный контест! Желаю проводить побольше таких на Codeforces (и не только в качестве этапа VK Cup)!
Выскажу некоторые комментарии и предложения:
Условие задачи должно более однозначно ограничивать максимальный размер теста. В этом контесте все понимали, что максимальный тест (с 1 инвокером и 20000 посылок по задачам с 1000 тестов по 30000 миллисекунд) превышает TL по времени работы на несколько порядков, но никто не знал насколько сильно финальные тесты будут по объёму превышать претест №2.
В начале контеста было бы полезно опубликовать самое простое решение, проходящее претесты с любым ненулевым результатом, а также гарантировать прохождение этим решением финальных тестов.
Результаты по каждому тесту стоит нормировать на лучший результат по каждому тесту (как делается во многих TC Marathon), а не на результат авторского решения, которое на некоторых тестах работает во много раз хуже оптимального, необоснованно повышая относительную стоимость этих тестов.
Хотелось бы больше разнообразных тестов (и претестов, и финальных, и тестов для локального тестирования).
Я внимательно изучил доводы всех отписавшихся в комментариях и провел несколько собственных экспериментов. Спасибо за фидбек!
Действительно, несмотря на то, что претесты содержали наборы данных с почти 20000 попыток и различным числом инвокеров, некоторые тесты основного набора оказались существенно более требовательным к ресурсам. В самом деле, у ряда участников было мало причин подозревать своё решение в недопустимо медленной работе на основных тестах. Поэтому я решил сделать немного лояльнее набор системных тестов и перетестировать решения с повышенным в два раза ограничением по времени.
Я уверен, что это неправильно расстраивать перетестированием участников, кому было объявлено о проходе в следующий раунд. Поэтому в Раунд 3 будут приглашены все те, кто выступил не хуже, чем наименее успешный из уже объявленных проходящих в Раунд 3. Таким образом, после окончания тестирования ожидается, что список прошедших в Раунд 3 несколько расширится (посмотри насколько).
Интересно, до какой степени все-таки контест помог Codeforces, и автора почерпнули идеи для шедулера который реально используется на платформе? Если да почерпнули, то не стоит ли открыть тесты и запустить дорешивание ограничив количество посылок?
Итоги пока еще не подведены окончательно, поэтому, мне кажется, дорешка до сих пор не открыта. Дорешка, как финальный удар молоточка судьи, после оглашения вердикта.
Возможно действительно этот раунд что-то изменил. Сегодня мои решения на сервере проверялись очень-очень быстро — на >100 тестах за 3 нажатия F5 подряд. :)
Пока никак не помог. Как появится время я посмотрю используемые идеи лидеров, но не уверен, что всюду пойму код.