


Hello Codeforces Community,
Welcome to our first ever Long Contest!
We're glad to invite you to participate in April Circuits. It starts on Saturday, April 23, 2016 21:00 IST. The contest will run for 8 days.
The problem-set consists of 7 traditional algorithmic tasks and 1 approximation task. For traditional algorithmic tasks, you will receive points for every test case your solution passes. For the approximation task, your score depends on the best solution in the contest so far. All tasks will contain subtasks which are designed to be approachable by beginners.
Problems are prepared by Errichto and johnasselta has tested them. So, you can expect the problems to be in a good shape, and quality. :)
The contest will be rated. It is a new line of contests and we recommend to read the contest rules beforehand here. This contest is a completely experimental contest, but that has got nothing to do with the problem-set which you guys will be getting, which will be a quality, standard problem-set. Though, the problems aren't extremely hard and strong participants should be able to solve all of them. So they can fight with each other on the approximate problem.
From the next month itself, we can see some major changes happening to this line of contest, with the major focus on upsolving. Wait for it! inserts thug life meme
Oh, by the way, the top 5 participants will receive HackerEarth T-shirt and top 3 of them will also be awarded cash prizes:
First: $100 Amazon gift card.
Second: $75 Amazon gift card.
Third: $50 Amazon gift card.
Good luck to all the contestants!
--
The contest is over! I hope you enjoyed it. Congratulations to the top 5, great work. Which one was your favorite problem from the set, by the way? :)
It's weird that the top 3 do not have a CF profile. (Or, I failed to find their profile.) So, I've added HE links for their profile.







(drawn by my sister)
Wow! She's quite talented!
Set #2 is out for the contest.
All problems are unlocked. You can still start and climb the leaderboard. Submitting time doesn't matter (as long as you solve an approximation problem). There are 7+1 problems and two days left. Good luck!
Why does the scoreboard show my total time incorrectly?
Lol, it's an overflow issue. I added your times by hand and I got 1072 hours, 27 minutes, 55 seconds. In other words, it is one month (31 days) plus 328h, 27m, 55s. Next time you should try to get exactly one month to get 0:00:00.
Someone will take a look at this issue.
Aha,, For some reason, the utility that converted seconds to HH:MM:SS assumed that total_time will never be more than 30 days. Pushed a generic fix for that. Thank you for pointing out. Also, Thanks to Errichto for the deduction.
Auto comment: topic has been updated by belowthebelt (previous revision, new revision, compare).
Was it the intended solution for 2A — Bear and All Permutations to compute the solution locally and just divide the resulting (hardcoded) numbers by the primes in the testcases? I did it that way and it almost felt like cheating, but it seems almost everyone did it the same way.
I too felt some guilt for precalculating values! The editorial provides the same approach. https://www.hackerearth.com/april-circuits/algorithm/2a-bear-and-all-permutations-1/editorial/ My Java code took around 30 mins for
N=1 to 12.Carsten Eilks has a CF profile. He participated in one Div-2 Round and secured a rank of 108 (230 including the Div-1 contestants) by solving 5 out of 7 problems.
Because several people asked me to explain my solution to problem 1B — Bear and Leaderboard, and because the official editorial is awful, I explain my solution here.
In the problem, it is necessary to maintain participants' number of points (I'll call it score) and to print the sum of participants' hashes after each query, where the hash is defined as score times place. Because computing the answer each time is too slow, the first idea is to keep the current value and update it as participants' scores change.
As a result of each query, the score of exactly one participant changes, and the new score is greater than the old one. His place may also change as a result. What about other participants? As it happens, those participants whose score is greater than or equal to the old score and strictly less than the new score have their place increased by one, and everyone else's place is unchanged (this can be seen from the definition of place in the problem statement). So, to compute the change to the answer, it is necessary to know the current participant's old score, new score, old place, new place, and also the sum of scores of other participants whose place increased as a result of the query.
Now, these values can be computed using various data structures like balanced search trees and segment trees, but for me, Fenwick trees look more simple and efficient. While they offer everything I need, they have a limitation: the indices must be small enough. I want to have participants sorted by score, so it is natural to use score as an index, but the scores can be up to 5·1011, which is too large. So, the second idea is to compress the scores. To do this, I put all possible score values into an array (there are at most q + 1 such values), sort them and remove duplicates. Afterwards I can use binary search to map each score value into an index in that array.
In the solution, I use two Fenwick trees. The first one, fCount, is used to compute places. For each participant i, I increase fCount[scorei] by one. As a result, a sum on a prefix of fCount is equal to the number of participants whose score is less than or equal to some value. From this, a participant's place can be trivially computed by subtracting the result from n + 1. The second tree, fPoints, is used to compute sums of scores: fPoints[scorei] is increased by scorei, so the sum of scores of a contiguous subset of participants (sorted by score) can be computed as the difference between two prefix sums.
These two trees provide me with all the information I need to maintain the answer. Also, in the course of processing each query, I update the trees to keep their contents in sync with the participants' scores. This solution uses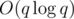 time for preprocessing and
time for preprocessing and 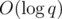 time for each query, so the overall complexity is
time for each query, so the overall complexity is 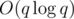 (an array of size n is allocated to keep track of the scores, but it could be replaced with a map if n could be very large).
(an array of size n is allocated to keep track of the scores, but it could be replaced with a map if n could be very large).