



Доброго дня, Codeforces!
Сегодня, 19:00 начнется первый раунд Открытого чемпионата Москвы и МО по программированию (КРОК).
Это будет обыкновенный двухчасовой Codeforces раунд со взломами и падением баллов во время соревнования. В Раунд 1 допускаются все, кто прошел Квалификацию и зарегистрировался на соревнование. Также вне конкурса допускаются к участию все остальные зарегистрировавшиеся на раунд. Как обычно, раунд будет рейтинговым для всех. Для прохождения в Раунд 2, Вам нужно набрать не меньше баллов, чем участник на 300-ом месте (при условии положительного числа набранных баллов).
В раунде вас ждут несколько задач, примерно расположенных по возрастанию сложности. Разбалловка за задачи стандартная (500-1000-1500-2000-2500). Во время раунда задачи тестируются системой только на претестах, а системное тестирование состоится после окончания соревнования. Претесты не покрывают все возможные случаи входных данных, так что тщательно тестируйте свои программы!
До окончания раунда категорически запрещается публиковать где-либо условия задач/решения/какие-либо мысли и соображения о них. Запрещено общаться на тему задач, обсуждать условия и проч. Будьте честными и пусть в Раунд 2 пройдут сильнейшие. После того как раунд завершится, можно будет обсуждать задачи и решения.
Хочется отдельно отметить, что раунд может показаться сложным для участников из div2. Не забывайте, что рейтинг будет пересчитан только для тех участников, которые сделают хотя бы одну посылку по задаче.
В подготовке сегодняшнего раунда участвовали: Ripatti, havaliza, haas, RAD, Gerald, MikeMirzayanov, Delinur. Огромное всем им спасибо за проделанную работу!
Всем удачного Раунда!







Рейтинг будет пересчитан для каждого дивизиона в отдельности?
Сюда кажется забыли запилить пост.
Не отсылается решение, множественные сообщения с багом и женщиной. Пробелы вставлять не помогает.
Послалось, когда удалил половину ненужных инклудов и using namespace std.
Admin plz look in to it. I received a mail that I qualified for round 1 and I also registered for round 1 as usual but now I am trying to submit solutions but it gives me access denied what is the problem admin plz look into it asap.
I am too receiving the same problem ...
Now I had "access denied" too, but using the "Submit" tab (rather than submitting from problem page) helped.
Same here!
Расскажите, как решать С, пожалуйста.
Спираль размера k+2 — это квадратик минус спираль размера k минус еще одна клетка. Спиралей куб, каждую пересчитываем из спирали меньшего порядка за O(1). Перебрали все, сказали ответ.
Заметим, что квадрат размера
kлежит в середине квадратаk+4. далее понятноПусть d[r][c] -- сумма в спирали размера k - 2, начинающейся в клетке (r, c); nd[r][c] -- то же самое для спирали размера k. sum(r, c, k) -- сумма в квадрате размера k; a -- исходный массив. Тогда nd[r][c] = sum(r, c, k) - a[r + 1][c] - d[r + 1][c + 1]. Так можно пересчитывать d от k - 2 к k и каждый раз проверять все ячейки. Сложность O(n·m·min(n, m)).
хм, а я начинал с каждой клетки раскручивать спираль с центра... раскручивал не по клеточкам, а отрезками и когда на очередном витке получалась корректная спираль, то проверял с ответом... сложность O(N3), но отнимать спиральки круче, у меня более косячное решение...
На чем ломали A и B?
на ТЛ?
Да.
Что, много кто 2 * 109 засылал? У меня в комнате ни одного не было
Скажите пожалуйста,мне не понятно, надо ли было делать защиту на ввод больше 2 * 10^9 в задаче А?
Входные данные всегда корректны и соответствуют условию
Дело в том, что если ваша программа делает n операций, при этом n равно 2 * 10 ^ 9 — это не укладывается в ограничения по времени, слишком медленно. А проверку ввода делать не обязательно.
Если вы о вводе взлома, то там проверяется, что все входные данные подходят под условие.
Если про задачу в целом, то это, чтобы можно было использовать стандартный 32битный тип, даже не знаю как использовать 64битный в своем языке.
Сейчас, как всегда, найдется толпа тех, у кого 2*10^9 зашло)
UPD: только поняла, как решали влоб(вначале показалось, что копировали строку и проверяли)
На тупом проходе по обеим строкам, что получало TL, например, на тесте:
B: 4 4 .#.. ..## .#.# ..#. нельзя решать for i 1-n for j 1-m
на В ломали на ТЛ видимо тестами 1000 1000 где последняя строка заполнена точками (и подобное)
1000 1000 где все звёздочки тоже успешно ломалось (меня так взломали)
Умудрился прочитать в самом начале тура
CD как "3 наместника, каждому по n/3 городов". Только за двадцать минут до конца решил всё-таки перечитать сэмпл, понял, что я дурак, и засабмитил на последней минуте.Хороший контест.
Все-таки это задача D :)
Ты еще и не прочитал что это D, а не С:)
Я люблю тебя, C++!!:D
ML — наш вердикт!
Мне не понятно, как будут пересчитывать рейтинг? Отделят дивизионы и пересчитают внутри своего дива?
The problems were quite tricky. I've hacked someone at every problem I've solved (A,B,C) :-)
what kind of tests?
...the largest possible!
What's the corner case for A? I saw a lot of hacking.
I don't tnink it shows that problems are tricky. Just somebody can't understand that naive algos are slow enough.
Wooooo~~,how exciting for the first time!
Как D решалась?
Чуть-чуть случаев. Разбили на две доли. Либо в обеих долях количество вершин делится на три (тогда очевидно), либо в одной остаток 1, в другой — два. Будем считать, что в первой — один.
Теперь если в первой доле есть вершина, не соединённая хотя бы с двумя из второй, убиваем этот треугольник, дальше — очевидно. Иначе в ответе, если он есть, бывают только тройки из одной доли или тройки ("2 из первой", "1 из второй"). Очевидно, что вторых троек будет 2 по модулю три, иначе не сойдутся остатки. Также в ответе, если он есть, можно сделать так, чтобы вторых троек было ровно две. Отлично. Нашли все вершины из второй доли, несоединённые хотя бы с двумя из первой, взяли две любые, выкинули два треугольника, дальше — очевидно
Только там есть ещё несколько случаев, когда граф несвязный.
А в чём проблема несвязного графа?
Ну вот, у вас упало. В том, что если есть несколько компонент, доли каждой компоненты можно раскидать в долям всего графа двумя способами. Поэтому нельзя сразу абы как раскидать их по долям.
Всё равно непонятно. Я в своих рассуждениях нигде не пользуюсь ни связностью, ни тем, что разбиение на доли единственно. Когда доказываю отсутствие ответа — мне всё равно, из какого разбиения на доли он был получен.
Я понял, у меня просто решение другое — я перебирал все варианты, включая количество и размер компонент связности и в каждом случае либо получил ответ, либо убедился, что его нет. Сорри.
Там действительно не важно как разбросаны доли... я рассмотрел маленькие случаи, все они подходили под общую схему решения... ниже описал...
Упала, потому что в одном месте вместо
<=написал<Каких например? Казалось бы, упомянутых случаев должно быть достаточно
Когда компонент несколько надо разобраться с тем, как доли компонент раскидать по глобальным долям.
Если решение существует, то оно существует для любого варианта раскидывания, разве не так?
Похоже что так, у меня прошло. Либо я очень везучий :)
Нет. Например: 6 4 1 2 2 3 4 5 5 6 Если выбрать доли 1,3,4,6 и 2,5 — то решения нет. А если 1,3,5 и 2,4,6 — то есть
(1,3,5) (4,6,2) — решение, см. последний случай
Раскидаем каким угодно образом наши города по берегам. Обозначим количество на городов на левом берегу a и на правом берегу b. Тогда если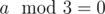 , то ответ очевиден (разбить на тройки на берегах). Если
, то ответ очевиден (разбить на тройки на берегах). Если 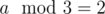 , то поменяем города берегами, тогда станет
, то поменяем города берегами, тогда станет  . Теперь попробуем найти на левом берегу город, у которого нет моста с двумя городами на правом берегу. Если такой имеется, то удалив эту "троицу" переходим к случаю когда
. Теперь попробуем найти на левом берегу город, у которого нет моста с двумя городами на правом берегу. Если такой имеется, то удалив эту "троицу" переходим к случаю когда 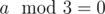 . Вот, а теперь на чем всех ломались. Рассмотрим тест:
. Вот, а теперь на чем всех ломались. Рассмотрим тест:
Т.е. для города на левом берегу не нашлось такого города, тогда в таком случаи должно найтись два город на правом берегу, которые не соединены с двумя городами не левом берегу и так чтобы все 4 города которые мы выбираем на левом берегу были различные. Но раз до этого мы не нашли слева города, который не соединен мостом с более чем один городом, значит он не соединен максимум с одним и для поиска двух наших городов справа можно использовать жадный алгоритм. И опять же после удаления двух "троиц" мы переходим к случаю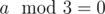 .
.
I will comeback next time!
me too :)
тот факт, что я опоздал на контест на 30 мин, не испортило мне впечатление от контеста. замечательный контест
Взлом вслепую... мне сегодня везет...
02:00:00 D Успешный взлом участника...
Is there going to be any wild card round like we saw in VK cup??
Have you read the Announcement?
ya... no mention about any wildcard round... but was still hoping :)
No mention = no round
Были какие-то баги с отправкой. Из-за этого на минуту позже отправил A и C :(
Отправлял через выбор файла, при нажатии кнопки Отослать появлялась страничка с Access denied. Видимо, потому что страница долго была неактивной — со второго раза получалось нормально.
For problem B, if using DFS, what's the time and space complexity?
Can you explain how do you find shortest path with dfs?
You would need to include the distance in the state. This makes the time and space complexity quite large for this problem, but I guess that if in another problem, you really wanted to do it, you can do it.
For this problem, I guess the risk is not high time complexity but stack overflow?
If someone thought it can be solved by DFS, please let me know.
It is both, I think the maximum result for the distance is around 2000 , so 2000*1000*1000 sounds slow even if you deal with the stack overflow.
How did you get 2000*1000*1000? What's about BFS when the result is 2000?
Talking about DFS, and since you need to include the distance in the state, and the maximum distance is 2000, and there are 1000x1000 cells, then a very sloppy estimation is 2000*1000*1000 (I bet it is much smaller with cropping, but still).
In BFS (Actually a Dijkstra variation), the distance is not part of the state, so this is not a problem.
Let the function prototype be dfs(x,y,dist,dir). The stop condition of the recurrence is x == n-1 or y == m-1. So param dist is not a decisive factor of time complexity but only stack usage.
In a DFS, You can visit different (x,y,dir)s with different distance values.
That's right. But I still thought 2000*1000*1000 is a wrong way to estimate although I agree DFS might be slow.
I will try to implement a DFS version which passed systest or failed due to TLE. We may discuss further via private messages then. Thanks.
For problem B, unsuccessful solution was Dijkstra with O(n^2 + m). On
1000 1000with all#:n = 10^6,m = 2 * 10^9.2 * 10^9 + 10^6is TL.DFS was even a more stupid idea, i think.
Depends on how you build graph
Yes, but I wrote this to show the solution which passes pre-tests, but is not correct
you can make every point in a number. It only cost 20 long long to represent a line. so the build graph time is O(n*m*20)
По-разному перегружать одну и ту же функцию для int и Integer — это жесть...
ArrayList a; int i; a.remove(i); // пытается удалить по индексу
Integer j; a.remove(j); // пытается удалить число j из массива
А зачем использовать Integer? Оно только между угловых скобок нужно, в остальных случаях int не хуже
В том-то и проблема, что я использовал int, а мне надо было удалять конкретное число из массива. Теперь буду внимательнее смотреть на то, какая функция вызывается в действительности.
В какой задаче так надо делать? Удалять число из массива это как бы долго.
Я в D так делал. Когда уже выделил 3 или 6 вершин с разных берегов, которые можно соединить, я их удалял. После этого на каждом берегу оставалось количество городов, кратное 3, и все легко делилось. Можно было и без этого обойтись, но я никак не думал напороться на подобное.
ОК, я-то D не решил)
Я тоже — не успел разобраться, в чем дело. Хотя может решение и так неправильное. Посмотрим на дорешивании, когда откроют.
list.remove((Integer) i)
Is the result of the last query in the sample case of Problem E right?
n = 5, k = 1, r's and a's are given as (1 5 4 1 2) and (4 4 3 2 2), respectively, and the last query asks if the 1st and the 4th members can be together in a group. But their age difference is 2, which exceed k(= 1), so they cannot be in the same group.
My misunderstanding or what?
Condition on ages doesn't look like "no 2 members have ages with difference greater than k", but like "each age of the member of the group should have difference no greater than k with group leader".
I see, but the problem also requires that one of the two members given in the query be the leader, doesn't it?
"It's possible for x or y to be the group leader.", not required.
Интересные очень задачи, мне понравились, жаль только что я не смог найти баг в задачах А и Б, а через 5 минут после контеста нашел! Готов поспорить что такое бывает с каждым :)
tourist, не, не слышал.
У него такое тоже бывает.
Только в случае Гены задачи все равно проходят, даже если он находит в них баги только после контеста.
Надо сделать новое звание, с рейтингом 2900+, и с названием турист.
У меня B 2 раза упала на претесте 6, потом перечитал условие, оказалось, забыл, что надо -1 выводить, если нет решения -_-
Overly long explanations for Problems A, B and C
I liked this contest, wish I didn't fail so much in problem A so I could have tried D.
One cute way of solving C without using the "shape" array is to define a spiral of size 1 as simply a single square. The recurrence then follows quite naturally for larger spirals.
Как там писал Шмелев? Снимите с меня весь рейтинг за сегодняшний контест! Перепосылка по А из-за того что у меня ножницы режут камень, час тупости над В когда не мог правильно посчитать асимптотику решения и еще не сданная С из-за косяка в реализации. Фак мой мозг.
Жирным выдели, чтобы в глаза бросалось. А то вдруг еще не заметят — и не снимут...
И так снимут;)
Если и снимут, то мало, у меня и так рейтинг уже ниже плинтуса.
Div. 2 приветствует тебя! :)
UPD По крайней мере мы тебя всегда ждём :)
Машет ручкой на прощание...
А вот нет!
Подождем еще немного...
На вторую Дейкстра плохо заходит:(
+1. Меня на ней ещё и взломали =(
Так тебе же лучше, что взломали. Раньше узнал — лучше срегаировал
Так-то оно да, только взломали за 10 минут до конца )
Та вроде все ок должно быть. Надо немного аккуратней написать, наверное...
Зачем извращаться с дейкстрой? Сила BFS с нами.
Я вот мог в красные пойти, благодаря таким вот Дейкстристам, Флойдистам и т.д. Но вот затупил во второй, тоже (сначала просто жадность написал)... И этим умножил свое итоговое место на 2.
Спасибо мне? :)
Да... Спасибо) Хотя не сильно и помогло) Это мне спасибо за +100:)
И Вам спасибо, но мне тоже не сильно помогло
У меня все точно так же печально... Сейчас попробую под Делфи сдать, обычно в 2-3 раза быстрее работает... Обидно будет, если пройдет.
И это хорошо!
Граф же невзвешенный!
Ну у меня получился 1-0 граф. Я понимал, что все должно быть проще, но придумав Дейкстру, решил сразу писать.
На таких графах можно дек писать... и вот он бы тут прошел... лентяй я...
Можно считать только переходы в соседние и повороты, и будет 0-1 граф с O(MN) ребрами.
Я там явно граф не строил, а просто перебирал в BFS для данного x все y, если мы еще этого не делали, и для данного y — все x, если мы еще этого не делали. В сумме таких переборов будет N + M.
Я тоже явно не строил. Вообще, у этой задачи стопицот разных решений. Каждый писал, что приходило в голову. =)
Только далеко не все сис. тесты проходило:)
А можно рассмотреть двудольный граф из столбцов и строк.
То есть, ее все-таки можно было решать Дейкстрой. =) Круто.
Откройте дорешивание плиз)
+
Присоединяюсь к просьбе!
// а я думал, что оно автоматически открывается после окончания систестов, нет?
Не всегда.
Все админы пошли спать наверное, других вариантов нету...
I don't remember when I was so lucky as in this contest, watching the system test was too exciting... (I fell to place 300)
why there is no practice after the contest? and the problems are not available in problemset also.
Можно ли подобрать такие n и m, чтобы было a^n = b^m.
Чего?
Какое отношение это имеет к прошедшему контесту?
Традиционная рубрика "Вопрос по теме" :D
Why is Dijsktra for B too slow? 1000 * 1000 * lg(1000000) * 4 = 80 million, which should be doable in 2 seconds. Unless the server is very slow today ... :(
True story
It's kind of pointless to use Dijkstra when your graph only contains edges of weight 1. ;)
0 and 1.
But BFS is enough, throught
BFS when weights are 0 or 1 is Dijkstra, just optimized for such low edge weights.
Use deque and it's still BFS.
Yes. Boundaries between these algorithms are not so crispy. A BFS when weights are 0 or 1 is both a BFS and Dijkstra :)
Even with normal BFS using a single queue, if you use it to find the shortest path, you are applying Dijkstra's idea. The original Dijkstra algorithm didn't use a heap. It was just the concept to expand the current shortest path first. When you do a BFS to calculate the minimum path, you do exactly that. Specially if you use a deque, you are no longer just doing a search, you are already following the same algo but with a deque instead of a heap.
So, Dijkstra works in this algorithm, just use a Deque instead of a heap.
Can you please share how you use to a deque to make it work?
Some edges have cost 0 and some edges have cost 1.
Normally, you have a queue and push all edges to the back of the queue.
If you have a deque, you can push edges that do not increase the current distance (edges of cost 0) to the front of the deque. And edges that increase the distance, cost 1 to the back of the deque. Afterwards, it is the same as a BFS.
It works because it guarantees the node with the shortest distance is always at the front of the deque.
There was no need to write Dijkstra, especially with heap. Didn't you think about any simpler solution?
The complexity of Dijkstra with a heap is O( log(|V|) x (|V| + |E|) ) I think that the usual Dijkstra solution has |E| around 4x4x1000x1000 and |V|=4x1000x1000 (There is a node for each pair between each cell and each of the 4 directions. And for each of those nodes, there are 4 edges towards other nodes in case the cell it is a column).
Your complexity estimation seems to be |V|x log(number of cells), quite smaller. O( log(|V|) x (|V| + |E|) ) is 5 times larger and yields 9 digits.
I see, I missed out the number of edges. So I need around 400 million operations in the worst case.
Still, that is on the order of 100 million operations, so it should pass? =D
Set has a high constant (as compared to others algo like bfs..), so it would not pass
I see many people (including me) got WA on pretest 5 in problem C. I think the problem is setting the initial maximum value to 0. We should set it to a large negative value.
Написал правильное решение по A, лишь в строке
неправильно поставил знак :(
Неужели КРОК запретил CF юзать свои задачи в дорешке?
СВОИ задачи? С каких пор они принадлежат КРОКу, если авторы (как я думаю) никакого отношения к КРОКу не имеют?
Капитан Прямолинейность?
Окей, как тут можно понять криволинейно?
свои == принадлежат тебе
Может мне кто пояснит, в чём проблема этого решения по B? Не вижу причины TL. Заранее спасибо.
Возможно, лист по памяти раскидывает. Попробуйте вектор.
Нет проверки цвета строки (столбца) при добавлении в очередь, из-за этого в худшем случае в ней будет n*m элементов вместо n+m и общая сложность будет O(n*m*(n+m))
Не согласен, всё присутствует if (a[i][nom]=='#' && (!b[i][nom])){ if (a[nom][i]=='#' && (!b[nom][i])){
Запуск на MS и GNU C++:
1484918 06.04.2012 22:06:14 Commandos B — Тайная комната MS C++ Полное решение 360 мс 29800 КБ
1484905 06.04.2012 22:05:34 Commandos B — Тайная комната GNU C++ Превышено ограничение времени на тесте 46 2000 мс 14600 КБ
Код одинаковый
Согласен, был неправ, замена list на vector помогает: http://codeforces.me/contest/173/submission/1485048
Да, помогает, но всё-таки это жутко подозрительно, когда скорость работы программы отличается на 2 компиляторах в 5 раз
Не в компиляторе дело. list это связный список, почти любая операция с ним — cache miss, поэтому тормозит.
Ну как сказать.. на MS стабильно проходит же, и очень быстро... А почему лист медленней понятно
Возможно у MS другая реализация list'а
Перегружусь под дебиан, это уже интересно. Результат ниже...
Не в первый раз вижу, как list тормозит. На каком-то из варшавских контестов в Петрозаводске чекер с list тоже работал очень долго (минуту?), а замена его на vector заставила работать ~6 секунд. Видимо, у самих поляков на другой ОС + другом размере кэша всё работало приемлемое время.
у list'a в g++ size() за линию работает, возможно из-за этого
Если так то точно из-за этого
так и даже вкратце написано зачем они так сделали
Поменял на !koords.empty()
1485260 06.04.2012 22:43:46 Commandos B — Тайная комната GNU C++ Полное решение 450 мс 29800 КБ
Так я ещё не разочаровывался...
Локальные тесты (компилятор gcc version 4.4.5 (Debian 4.4.5-8))
с koords.size():
real 1m8.310s
user 1m6.944s
sys 0m0.196s
с !koords.empty():
real 0m0.160s
user 0m0.144s
sys 0m0.020s
Причина очевидна.... Такой подставы не ждал :\ Постоянно пишу на компилятор GNU C++ :\
Написал while(q.size()>0), зачем-то исправил на while(!q.empty()). Чувствую себя ясновидцем ^_^
Thanks for the great contest . There was lots of div 2 participants in the contest so please prepare more problems for div 2 like the VK 2 contest .
Сегодня столкнулся с одной проблемой. При посылке задачи А, используя компилятор Microsoft Visual C++ 2005+, правильное решение получило неправильный ответ на первом претесте, так как выдавало ответ 0 2 вместо 3 2. В то же время на GNU C++ 4.6 решение прошло.
Сократив код (это не решение задачи А), который способствует AC, я получил вот такой код, который зависит от компилятора на первом же тесте (0 2 вместо 3 2). Кто-то может объяснить, почему?
UPD. Если добавить в функцию win, в начало строку printf("smth\n"); то программа начинает работать правильно даже в VC++.
а Вы пробовали без gets?
Да, scanf; cin, getline со string'ами тоже пробовал. Результат тот же.
Возможно одна из прог не дочитывает переход на новую строку в scanf(n)
Пробовал в "Запуске" выводить строки после того, как считал. Все правильно, но тем не менее результат 0 2.
K.I.S.S.!
Отлично работает в сочетании с freopen!
Да, работает просто отлично, сам раньше так писал. Но вот тут это не поможет, уже проверил. Проблема не в считывании строк.
Да, да. Дело в win. Кажется это ошибки оптимизатора, он забывает свапать, так как дальше одинаковые строки идут.
Если завершить win вот так
, то всё заработает. Но если убрать
cout << A << B;, то программа не завершится.Да, спасибо, вполне вероятно. Кстати, если заменить swap на "ручной", то будет работать тоже. Если бы не эта проблема, то мог бы на 3 места выше оказаться :) С сегодняшнего дня буду тут все на гнушке сдавать.
C GCC как бы тоже не всё хорошо.
Очередные баги в оптимизаторе. Вот такой минимальный код в Debug выводит 1 1, а в Release — 0 0. Причем никакой assert или cerr уже не помогает.
Спасибо. Да, плохо получается, когда баги не в решении, а в оптимизаторе... Хотя частично сам виноват, что копипасту сделал. Обычный цикл бы уже помог.
В g++ работает нормально с -O2. В Visual C++ 2010 Express не работает.
I got about +10 hacks in A by using this case
These hacks saved my score after failing A and B. I was so lucky. Nice contest, by the way! :)
Я ВЕРНУЛСЯ!
Я тоже)
Посоны я с вами)
Не знаю как обстоит дело с другими задачами, а в E тесты были слабыми. У меня прошло решение 1484343 с тупым багом: не обрабатывается случай, когда у нескольких людей совпадает r. На тесте
оно выдаёт 3 вместо 4.
+0 rating change. This is the second time it happened to me!
+0? You're an optimist;) I have simply 0, without plus..)
Почему турист занял первое место? его же нет в таблице результатов.
поставьте галочку "вне конкурса"
По умолчанию.
Поставьте галочку "неофиц." в таблице
tourist у необязательно участвовать чтобы выиграть)))
Оххх, в 0.29 написал авторское решение по D, но в некоторых случаях забыл вывести "YES". Минут 35 искал ошибку, только после этого сдал B и C и только после этого сдал D в 1.45. КМП прямо-таки :)
Авторам спасибо за контест!
Can someonw tell me whats wrong in the submission(for Prob B)..Solution...
Можете объяснить реализацию задачи А. (разбор всмысле)
http://codeforces.me/blog/entry/4289
There's inconsistency in final standings and rank in member's profiles, take Petr for example, he finished 3rd, but on his profile page the graph shows Rank: 4
There is one unofficial participant above Petr
thanks for reply, I think usually official rank is displayed
Rank shown in profile should be the rank used to calculate rating, which includes unofficial participants in this contest
Ну пипец.. Пропустил и очень обидно :(
У меня так же получилось с VK Round 1. К счастью, там был wildcard...
Since the editorial doesn't seem to be coming, could someone share the ideas of their solutions to D and E?
You can try to get something from the editorial in russian.
I didn't see that, thanks.
It looks like the author has been translating the editorial as we speak. It's now ready in English too: http://codeforces.me/blog/entry/4289