


Good day for all!
I invite you to participiate in the Codeforces round 313, which is prepeared by me and tunyash. Each of us is prepared four rounds then it is our fifth of ninth round to your notice. I figured out almost all problems (except D div.1), wrote the statements and analysis of all the problems, and tunyash has developed all problems.
Gerald is not coordinator yet and you probobly missed him. In this round you will meet him again and help him in his ordinary life problems.
I want to thank Zlobober, our translator Maria Belova (Delinur) and MikeMirzayanov and all Codeforces team for this platform.
This round will be held in unusual time — 17:00 Moscow Time.
Contest finished! Welcome to editoral:
Short editoral.
Extended editoral.
Div.1 scoring distribution:
500 — 1000 — 1500 — 2250 — 2250
Div.2 scoring distribution:
500 — 1000 — 1500 — 2000 — 2500
I wish you to enjoy solving problems!
Congratulations to winners!
Div. 1:
1. jqdai0815
2. qwerty787788
3. SirShokoladina
4. ainu7
5. Endagorion
Div. 2:
1. goons_will_rule
2. lbn187
3. crawling
4. loveannie
5. Jagabee







This is always my first thought when I see 313 anywhere:
:)
Wow!I'm looking forward to the coming contest!
>mfw there's finally a round after a long time
I think Zlobober is dead. It's a long time he doesn't reply anyone.
Don't you think it's a bad idea to joke about someone's death?
Nope
He's not joking. he is so serious.
but why so serious ???
I think he said that nick (Zlobober) wasn't online for a long time :)
Another unusual time! I'm happy because I'll be able to sleep before 02:00... though it might collide with others' schedules.
I can sleep before 12:00
it is so funny
Really Don Rosa drew it like this :o? It's like a profanation made by a saint ;__;
17:00 ? Srsly? Every normal people work in this time (in Russia) -_-
Normal people earn money from home :P
Are programmers normal people? :D
:D
you are funny always :D
It is only people in our time zone, who works without flexible schedule. It is very few people. Every contest time not comfortable for someone.
"Every contest time not comfortable for someone." — of course, but the time 19:00 — 20:00 is more convenient for more people IMHO.
And hence we must schedule all contest in this time, ignoring all other people?
It's not for me :D. Currently it will be 7-9 AM in my timezone, so I can just go later to work, but 9-11 AM will be too late :P
Yeah, Burgerland is relevant enough.
I hope I don't oversleep. 7am is too early for me.
I can call to wake you up.
New feature of CodeForces — contest reminders?
MikeMirzayanov there were 7 rated contest in June but so far only 2 in this July . We all want more frequent rated contest :)
We take 'usual time' CF rounds at 01:30, and it takes two hours, so if you are a student or have a schedule and you REALLY want to participate, you should spare your sleep.
I'm not saying that the time CF rounds start should iterate over and over. I just want you to know that there are many people around the globe who cannot(or wouldn't) participate because of the time zone. Give us some chance, please.
Thanks guys for taking the time doing all this work!
313 is a holy number for Muslims :)
i think it's a good time for china coders
which rounds did you prepare?
You can find all the rounds of Sammarize here
Sammarize: 79, 94, 110, 194
tunyash: 122, 144, 176, 213
3.13 is my birthday! Hope there be a rating harvest!
tagged "codefores" :p if its a mistake, surprisingly it was done before :p
UPD: tag was removed :p
thx :)
:)
" Scoring distribution will be known closer to the beginning of round ," this time there is new sentence ;) !!!!!!!!!!!!!!!!!!!!!!!
tnx for usual time
During contest:
Now we've got problems and I don't think we can solve them. We got nothing figured out.
---Idea!---
Yes, yes, I can see it now! And you don't know how nice that is!
( https://youtu.be/QcIy9NiNbmo?t=1m33s + https://youtu.be/XPBwXKgDTdE?t=1m31s + https://youtu.be/oKar-tF__ac?t=1m38s + https://youtu.be/XPBwXKgDTdE?t=45s + https://youtu.be/cMPEd8m79Hw?t=51s )
I almost do.
Anybody know at what time the practice problems will be unavailable for judging because of this round! It's very important for me to know... thanks!
My last contest before IOI!
I hope I can practice with this round.
Good luck to IOIers. (Not everyone, hence it is possible :P)
Good luck for your round Sammarize :D
I'm very excited to take part in it!
My previous dorm room no. was 313 . Loved that room :P hope this contest is some kind of good luck charm for me!
wow...scoring distribution occurred so soon :D, really unusual round
it seems that 313 has lots of significance :/
Can't hack... Codes don't open...
I didn't have brave to submit something, but problem set is very nice ! I like first four problem ( in div 2).
UNSUCCESSFUL HACKING ATTEMPT AT 19:00:00
We need achievements at CF so baaaad.
self PR time: cfa.yuldashev.net
geometry geometry and geometry :P
Div1 B has already been given for training to the Junior National Team in our country and the teacher who gave us the problem said that she took it from some Russian site... And announcing the thing for odd length wasn't fair, I needed to resubmit. And it wasn't even added to the statement...
The statement clearly said "If we split string a into two halves of the same size". You can't do that if it has odd length. If anything, it's unfair that the announcement caters to people who can't read.
EDIT: Ok, I reread the statement more carefully, and I see why the clarification was necessary. "If we split a into two equal halves, then some things are equal" can also be understood as "For every possible way to split a into two equal halves, some things are equal". In this case, if a has even length, there is of course exactly 1 way to split it. But if it has odd length, there are 0 ways, so indeed the things are equal for every way. However, this would imply that the answer is always "YES", which is inconsistent with the sample tests, so you should notice that something is wrong before submitting.
So, clarification is indeed necessary, I retract my slightly rude comment above, but I stand by my claim that it's impossible to read it in a wrong but consistent way.
"If we split string a into two halves of the same size..."
If size is odd you can't divide it into two halves of the same size, do you ?
It's a formal consequence of the statement: string of odd length cannot be divided into two halves of equal lengths, therefore strings of odd length are equivalent iff they are equal
Okay, my bad, however it would be better if there was such sample. And still, the problem is known and I guess a lot of people just coded it with no thinking :)
Can someone please help me catch the mistake in this code? It never gives correct answer but I think the reasoning behind it is corect.12182932
Essentially I am trying to sort the strings(swapping the halves of the blocks), first in blocks of length 2, then blocks of length 8 and so on. sorting for all blocks of powers of 2 that divide the length of the strings.
Blocks can have odd length (e.g. string of 6 letters has 2 blocks of length 3).
Oh yeah, so I had to make d the greatest odd factor of the string length and then the blocks should be of length 2d, 4d, 8d... right? thank you.
Problem C (div 1) is an old problem.
Also div1 B :)
Also div1 A :)
you can find the solution of div1A/div2C easly on the internet :/ it's not fair
can u provide me link to div 2C answer on net?
http://math.stackexchange.com/questions/1370145/area-of-irregular-hexagon-with-all-angles-120-degrees
You still had to figure out that you only need to calculate the area and divide it by the area of a equilateral triangle
Problem
Code for old problem
Code for new problem
At least my idea of solving the same.
Does solution for DIV 1-B is just simply write a recursion function that check what the problem statement said?!?
I think NO. It will be TL. I've used something like merge-sort in O(NlogN).
Well , I got AC , with the recursion function , the problem is only O(lgn)+n , not even O(nlgn) .12177343
T(n) = 4 * T(n/2) + O(1) So it's actually n^2.
Isn't T(n) = 4*T(n/2) + O(n)? O(n) as we need to compare strings if they are of odd length. The complexity is n^2 even for this, but still.
You are right.
how about hashing?
Your complexity is much more actually.
The only difference from your code to my code (12180789) is that I used
strncmpand I got TLE. I replacedstrncmpbyforand... AC -.-".strncmpnevermore.Let's define the following operation on string S: We can split it into two halves and if we want we can swap them. Then we can recursively apply the operation to both of its halves.
Now we need to make the observation that if after applying the operation for some string X, we can obtain Y, then after applying the operation for Y we can obtain X.
And for the given two strings, we can recursively find the least lexicographically string that can be obtained from them. Let's say that those strings are A' and B'. If A'==B' then the answer is YES, otherwise it's NO.
But it seems like almost nobody made those observations since the problem is known and most of the Russian-speaking contestants may have seen it before :)
By the master theorem, your solution would have O(n^2) complexity.
I wrote this recursion and it didn't got TL. I think that it is because I used random to choose the order in which I call recursive function.
No. I removed this randomization, but it still works.
Solution with random (265 ms): http://codeforces.me/contest/559/submission/12169720
Solution without random (1435 ms): http://codeforces.me/contest/559/submission/12183383
I wrote a naive recursive implementation and got AC 124ms here: 12177962
I still don't get how my solution ran so fast.
No random, no optimizing, no anything.
It is probably the order of the recursion call. Check 12187196 and 12187385.
There is something called luck related to this problem. And seriously, letting us pass O(n^2) solution is not good at all.
It has nothing to do with luck. Look at this C++ code:
What will be the output when you input x = 0 and y != 1?
Yep, but the thing is that you already know this test case and you are sure that first of these equalities will be true. Imagine that y != 1 in all of the test cases and pretests wouldn't contain case x = 0, but final tests would. That's where you are more lucky than someone, who sent
cout << (((1 / x) == 5) && (y == 1)) << endl;and got RE (if I'm not mistaken) after final testing.I agree with you, order matters in this example. But my point was that C++ optimizes
booloperations. If first operand of&&evaluated tofalse, then other operand does not compute. Applying this reasoning to solutions with 4 recursive calls in a(A&&B)||(C&&D)manner, we can conclude that there are maximum of 3 calls actually made. Let's look:-If
A == trueandB == true, then neitherCnorDare computed, because||already evaluates to true-If
A == false, thenBdoes not compute, becauseA&&Bisfalsefor sure-If
C == false, thenDdoes not compute-At last, if
A == false,C == true,D == true, we get 3 recursive calls, which is maximum.So, basically, solutions written in C++ in this manner are not O(n2), but rather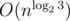 .
.
Maybe i'm missing something, but what about A=true, B=false, C=true, D=true? Then we will get 4 calls. Why isn't it possible?
Let's use = sign for equivalence. Then we have:
a1 = b1
a2 ≠ b2
a2 = b1
a1 = b2
We know that equivalence relation is transitive, so:
a2 = b1 = a1 = b2
But we suggested that a2 ≠ b2. It means that such situation is impossible.
Looks like
A=true,B=false,C=trueandD=falseis still possible, for example, whens=XXandt=XY, and that's 4 computations.If we take the meaning of A, B, C and D from the statement, then:
A = 'X is equal to X' = true
B = 'X is equal to Y' = false
C = 'X is equal to Y' = true
That's contradiction.
Right you are, my bad!
But: another example, checked by writing a program this time.
s=XY,t=XXA byproduct of checking is that this example is unique (if we don't consider symmetrical cases).
That is brilliant! My apologies for claiming that 3 calls are sufficient.
Wow, it passed the final test. I'm surprised...
What the the possible end configurations in C? I got a point, an equilateral triangle, a trapezoid, a rhombus. What did I miss?
Can anybody please see my Div2 E code, and tell me if it is TLE because of python, or my algorithm needs optimizing? :( Wasted 4 submissions on this.
http://paste.ubuntu.com/11920717/
No, a O(H*W*log(N) ) algorithm wont pass with H,W=10^5 and N=1000. The proper solution is O(max(H,W)*N). I couldnt get it correct in time, though...
No the correct algorithm is O((W+H) + N^2). The W+H comes from precomputing binomial coefficients.
I feel like problem C(Div1) is famous. I couldn't solve it but I'm pretty sure I've seen it around more than once.
I saw it on some codechef contest, I am 100% sure. After that my friend and I was talking about it. I will find it :)
https://www.codechef.com/CDCRF15R/problems/CWAYS/
http://codeforces.me/gym/100589/problem/F
Thanks, that is it :) I could be orange, but I'm fair :D
Projecteuler 408, and I also see this problem in several contests.
Yup! Solved it on codeforces itself
How to hack Div1B, those who just recursively check equivalence?
It passed the systest, so the correct question is, how to prove its runtime is better than O(N^2).
I coded my B as a recursive function satisfying T(n) = 3T(n / 2) + O(n), which is n1.5 approximately. This is much less likely to fail than a O(n2). You can check my code for details on how you do the reduction on number of checks needed.
Clever. But that doesn't explain why some people passed without using this trick, for example 12178491
I don't think there is a test case for this solution which will run N^2. ANDs would eventually cancel two extra recursion calls.
Really good observation
Didn't actually check your code, but I guess you wrote
A?B:(C&&D)instead of(A&&B)||(C&&D)whileB,C,Dis compute only when needed.Can you explain why you can go directly to the return statement in your if without checking the else?
If you're asking about my solution, what it does is:
Use ~ to denote equivalence. Note that it is transitive.
Say A splits in a_1, a_2. B splits into b_1, b_2. If a_1 ~ b_1, it suffices to check that a_2 ~ b_2. Indeed, if the other case holds (a_1 ~ b_2 and a_2 ~ b_1), then b_2 ~ a_1 ~ b_1 ~ a_2, so we would get that a_2 ~ b_2 anyways.
Otherwise, a_1 is not equivalent to b_1, so just check a_1 ~ b_2 and a_2 ~ b_1.
Why did mine fail then? High constant?:/
I think so. Copying substring is way too slow to pass this problem. A char* solution can pass it easily and unexpectedly. 12182556
I know recursion enough good, because I couldn't invent something smarter for half hour and some guys solve it in 5 minutes :)
Anyone got accepted problem C(Div.1) using O(n^2*log(10^9)) time ? :\
No... But I got accepted in O(N^3)...
O(N^3) how? I did it in O(N^2).
Well my solution is pretty stupid, it calculated useless values. My dynamic programming is F[A][B] = number of paths from black cell A to black cell B without passing any other black cells along the path. Computing every state takes linear time so O(N^3) in total. The question is — why doesn't it time limit? I'd bet on weak tests.
Answer for every question, Codeforces is very fast :)
2000^3 is OK for CF servers :D
But not for multiplying! Even 10^8 multiplications gonna catch TL!
You have O(N^2), actually. Your solution computes F[A][B] only for states, that have the same A.
Oh.. well that's lucky then :D
I promise to always precalculate modulo inverse from now! Rank 64 to Rank 213 :(
When can we use the training problems again? Now it seems blocked...
Ok, so problem B was in an ACM training around a year ago, and C was in a Slovak OI nationals around 6 years ago. Naturally, I knew the solutions of both by heart.
D: Pick's theorem was obvious, but I couldn't figure out how to cut down the boundary part to better than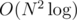 in contest. Oh well, time to keep going with those 480.6 pushups.
in contest. Oh well, time to keep going with those 480.6 pushups.
UPD: Just did E, it was much easier for me than D. I've got to be more daring...
Div.1 pC let me recall this problem : ICPC 2009 Asia Phuket Regional — Your ways
When I practiced it, I misread it as problem of today.
Is there anyone else who saw "
Judge protocol is inaccessible" error during challenge process? I saw that error and submitted the same wrong hack submission again. Several minutes later, all the submissions which gave that error were rejudged and considered "unsuccessful hacking attempt", so I got plenty of minus scores :pI particularly didn't like this round considering problems B and C were old problems and problem A was just simply googlable.
Plus, then you read comments about how simple brute force passed in B and O(N^3) passed in C.
A was googlable. ? oh damn. I could have been purple .
"A+B problem" is also googlable xd. Funny how people can think of googling such adhoc and simple things.
It all depends on how you are approaching the problem. Most people, I think, thought of finding the area of the special polygon.
Its a formula which you can a) derive for hexagons in the contest, or b) google and get answer in a minute.
Come on, don't make so categorical judgements :)
Open standings of div2 and you'll see that 70% of contestants there wasn't able to solve this problem. One which is simple for you — isn't that simple for someone else.
Moreover, it took me 3 attempts to solve this "adhoc and simple" one :) At least I didn't google it...
Maybe I didn't express it clearly, but mainly I wondered who even bothers of writing such things in Internet out so that they can be easily googlable :P.
Did anyone get Accepted in Div1-B using hashing? My solution 12181985 failed and not sure why.
Yes 12179329, Time Complexity O(nlog^2n)
Equality check using only the hash may give you a false positive. You should do the actual string comparison in case of matching hashes, to be sure. But then you risk getting a TLE on something like test 89, like I did: 12185730 :)
Yep, also tried using hashing and got TLE on 89 12171361
but why? my solution also used hashing and got TLE on 89
it turned out that the reason of the TL isn't the actual string comparison of matching hashes but the fact that the branching factor for each recursive step is 4 then, in the worst case, the overall complexity is O(n2).
If you try to choose randomly the order of recursive calls you make for each recursive step I guess it is hard to create a test case that requires 4 calls for each recursive step.
This is the AC solution using hashing (and just using the equality check of hashes to determine equivalence) with random order of recursive calls: 12187657
Hashed successfully, using several primes: 12176236
I got it accepted using hashing after changing the order of recursive function calls. (http://codeforces.me/contest/560/submission/12188786)
Here is an O(nlgn) solution of div1 B: Let the input strings be S and T, find the lexicographically smallest strings which are equivalent to S and T respectively, and check if they are equal. code : 12173245
Why does 12166408 fail? Precision problems? It seems to do the same thing as everyone else.
(int)(ans + 0.5)?
I think this is to print closest integer to ans. So, if ans is something like 0.9999 due to precision errors, we want to print 1.
Edit: I didn't see the solution actually and thought you were asking why is that being done. Of course, you are right, that is the mistake.
It should say (int)(ans+0.5) but it says (int)ans+0.5.
Operator precedence strikes once again.
Oh wow, he's gotta be mad.
Yeah,
(int) ans + 0.5should be(int) (ans + 0.5)(12185888).Is there any reason behind writing "(int) n", but not "int(n)"? Is latter variant considered something like bad style? It always seemed ok and even more logical for me, but you, W4yneb0t and ainu7 wrote it another way.
As far as I understand it, (int)n is called a typecast, while int(n) is called a constructor, with the difference being that one of them causes stupid bugs like this and the other doesn't. I write int(n) in my own code.
Multiple sources (cplusplus.com, wikibooks.org) state that both are called type casts. Perhaps it doesn't hurt to think of the latter one as a constructor though.
The reasons to use
(int)nnotation are perhaps tradition and/or C portability: this was the only notation available in C.Anyway, I just used whatever was in the source, trying to make the edit minimally intrusive.
Personally, I prefer to write casts as
(int) (n)in C++, since this notation is extendable to(long double) (n + 1)without change of form.Could someone tell me why this code got TLE? DIV 2D Code
Doesn't substring() makes a new array and copy the exact string? It may take a lot of time.
Instead, save the string in global variable, and give only the index (of left and right bound for both string) to the recursive function.
In your code for the return value instead of t1||t2 try t2||t1 Make "equivalen(a1,b1)&&equivalen(a2,b2))||(equivalen(a1,b2) && equivalen(a2,b1)" this "(equivalen(a1,b2) && equivalen(a2,b1)||equivalen(a1,b1)&&equivalen(a2,b2))"
For problem Div1 B I used divide and conquer but for the case when strings size is odd I called another function, this was the only reason I got TLE for test 91, I wrote code for this case in caller function and AC now. I checked "status" page and some of you have TLE for 91, so keep in mind my sad story.
Anyone else experiencing this problem for div 2 problem D?
In the question for operation 2, we have to recursively check for condition a or b and if either one if them is true. In the recursion code, if we check for condition b first then a, then I got an AC, if I check for condition a first then b I got a TLE (test 89)
TLE solution: http://codeforces.me/contest/560/submission/12186384 AC solution: http://codeforces.me/contest/560/submission/12186179
If first condition is true then your function won't run for second condition. So order affects running time.
But that means the test cases are weak right? If at all bruteforce recursion was to fail, then both codes should have got a TLE
Test cases weren't strong but it's hard for problem setters to fail all possible brute-forces. Though here we have two naive solutions and both should get TLE.
Yes, I can understand that its hard for problem setters, it would be nice if a few more test cases are added now (maybe reverse strings from original cases).
They could just set higher constraints. 200k is not enough sometimes.
I'm doing a farewell party for some of my rating. They were supposed to leave around now, is the plane delayed?
Good contest! But... It seems that the testcase for div1 Problem B is not strong enough. My first submission failded a case that I wrote(It prints YES but the answer should be NO). So I resubmitted it after revising. And then I used this testcase to hack someone's program. Though the hacking attempt is unsuccessful(because this program can pass my testcase), it shows that the testcase is feasible. But now I find that my first submission can also pass this problem...... I am not very happy because this resubmission made my goal -400. :( By the way. How can I show this testcase that I wrote? Maybe many of you want to check your program with this. Thank you.
I can't understand why my solution of div2 problem D gives WA on test 8: 12186517. It tries to make the smallest string (from both given) using the operation: swap partitions if the first is greater than the second. Than checks if the two strings are equal.
char a[2][200001],n;
Thanks a lot :). I'm so stupid.
Can someone explain why My Div2D got tle?? 12186568 latest submission 12188078 Thanks in advance
http://codeforces.me/blog/entry/19331?#comment-241912
Sorry,I actually do not get your point. Can you please elaborate your ideas. I see a lot of code passed regardless of there calling order. And my last submission 12187805 also gets timed out at case 6. Thanks in advance.
This is my latest submission 12188078 . Still TLE on case 6. Please Help.
You have O(n2) solution, because you do 4 checks. If you use this construction:
Then it will be at most 3 checks (because of boolean operators optimization and the equivalence relation), which will be O(n1.5).
Got TL in D div2 with python3, but the same code was accepted with PyPy. How to figure out how to send?
exactly the same thing! %) Sometimes Python is faster, sometimes Pypy (( I should have used C++
ratings up :)
Div1 C used in this contest is simply the copy of this problem. https://www.codechef.com/CDCRF15R/problems/CWAYS/ Author didn't even change the logic and used the same problem.
I'm pretty sure the authors didn't see this problem (you see there are not many participants in the contest you gave link at). Sometimes it happens — same natural ideas come to mind of different people.
Thanks for the problemset I really enjoyed it. But wasn't problem B Div. 2 Easier than problem A?
Finally became an IGM! Donald Duck and Taylor Swift gave me power :D!
Me too, custom tests saved me from fails, slow and steady wins the race.
I think test cases for div1 b should be revised and solutions should be rejudged
Why? Did correct solutions not get AC? If not then there won't be any rejudge.
Yes. Depending on which case you handled first, you could TLE. See http://codeforces.me/blog/entry/19374.
12188567 vs. 12188586. The only difference is in the commented/uncommented line.
Both solutions are wrong, all correct solutions got AC.
Good. But why many incorrect solutions can get AC?
So if I thought about the complexity before writing the solution I don't solve it, and if I write the solution without thinking I solve it? is that fair?
It's bad that some wrong solutions get AC but it's impossible for setters and testers to prevent it for 100%. Is it fair? It's not cool that some people have more points than they should but well, we all had the same possibilities to use this situation — so it's fair for some definition of "fair".
I can't imagine a yellow/red coder writing an O(n^2) solution for a problem where n<=2*10^5
But you are right, it's impossible to prevent it 100%
I can imagine a yellow/red coder writing an solution or properly optimising something to make his solution pass.
solution or properly optimising something to make his solution pass.
And statistically, such lucky situations are negligible when the problems are tested properly. People who don't have the skill will just drop down again eventually.
I wrote optimized O(N^2) solution for N = 2*10^5 in contest before (and it passed).
You're not the first to think of this problem. If you solve it, tell us. Adding tests after the contest has its downsides.
Actually,someone i know proves that the complexity is O(n^1.57)
If A and B are equivalent, it will only recurse at most three subtasks so complexity is T(n) = 3T(n/2) that is approximately O(n^1.57)
If A and B are not equivalent, it will recurse four subtasks only if two subtasks are equivalent so complexity is T(n) = 2T(n/2)+O(n^1.57) it's also O(n^1.57)
EDIT1: I made a mistake to let T(n) = 3T(n/2) in the first case since the subtasks might not be equivalent ! But after further calculations i still believe the complexity should be O(n^1.57) Plus, i wrote a program to calculate the times of recurses and it's about 10^9 which Codeforces is still able to run in 1s
Second one gives N^1.57 lg N
And mine too 12188078 I have no clue why I am getting TLE.
can anyone explain div2 c. My approcah is dividing the hexagon into four triangles and calculate the area of the individual triangles and then summing them up gives area of hexagon and later divide the area of hexagon by area of the equilateral triangle .is it correct or am i going wrong somewhere ?? please tell the other methods to solve this :)
Your idea is correct, you just have to implement it carefully
Div2/Ccan any body tell me what's wrong with my code , i used these theory :area of a triangle abc = 0.5 * b *c * sin(A)
area of a triangle abc = sqrt((a+b-c)*(a-b+c)*(b+c-a)*(a+b+c))
this the code :
First, decimal representation of C++ is "." not ","
You defined
sin120as0,86602540378443864676372317075294but you should change,to.Second, you calculated variable air4 with wrong formula.
Heron's formula is
sqrt(s(s-a)(s-b)(s-c))wheres = (a+b+c)/2If you rewrite the formula and fix it right, code should be
air4 = sqrt((a+b-c)*(a-b+c)*(b+c-a)*(a+b+c))/4.;Third, you used cout and printed double , without any setprecision, converting to integer or something. Answer can be large, and cout will use scientific notation such as 6e+006
Your code should be fixed as
cout << (int)( (air * 4)/sqrt(3));(?)However, this might not correct.
If you fix all the things, you might not get accepted because of real number error. To prevent this, rounding answer to nearest integer is preferred.
cout << (int)( (air * 4)/sqrt(3) + 0.5 ); adding 0.5 can be used rounding answer to nearest integer, if answer is positive.and the code got accepted. 12190712
Using real number is dangerous, so you should be noted.
By the way, this problem can be solved with simple method, not using real number or any complicated method.
Thanks a lot , i really appreciate it . btw i already solve it , i was just trying this methode :)
NORTH KOREA DOES IT AGAIN!
I got strong suspicions against black_horse2014. First reason being of course that he's from North Korea :P.
"00:17:22 A Accepted [main tests] 00:30:36 B Accepted [main tests] 00:35:09 C Accepted [main tests] 01:16:57 D Accepted [main tests]"
His times for A, B, C were 17, 13 and 5 minutes which seems unnatural, but doesn't sound impossible. However in his previous contest we can find this:
"00:13:12 A Accepted [main tests] 00:39:13 A has been locked 00:49:40 B Wrong answer on pretest 5 [pretests] 00:53:46 B Accepted [main tests] 00:54:38 C Wrong answer on pretest 8 [pretests]"
That B and C looks highly suspicious.
I dunno, there are a lot of things missing that lead to suspicions towards other Best Koreans.
a relatively similar template and coding style
I took 35 minutes to solve A+B+C as well (10 minutes on reading A,B,C,D and solving A; 9 on solving B, 16 on solving C), that doesn't mean I cheated; he could've tried to solve C first, had a bug or missing idea and found it after doing A+B
the minimum gap between submits in this round is 5 minutes, not seconds; in the previous one, there's a huge gap between solving and locking A that could've been spent on C, it looks like typical behaviour of someone who's unsure if the solution is correct even if it passes samples and getting AC on B boosts that confidence enough to submit; and there's still a minute gap; compare with 0 seconds and 14 seconds
The templates in B and C are different, but they have something in similar at least (chkmin and chkmax). It's not as clear as RNS's conduct in Looksery Cup. Still, your suspicion isn't unreasonable and CF should look into it.
Yes, some people might prefer submitting a few solutions at once.
Also, I hope you don't use the word 'Korean'; many people mistake North Korea(Democratic People's Republic of, communist, nuclear, ...) as South Korea(Republic of, `88 olympics, Seoul, ...). There's even a joke about South Korean people scaring foreigners, saying something like 'I’m from North Korea!'.
Yeah, what I used is http://knowyourmeme.com/memes/best-korea.
Oh... well, memes are hard to catch. Thanks!
In problem D, I got TLE in system test 91 due to my habit of using long long every-time. After the contest, I converted all the long long to int and same solution was accepted :(
Just curious. Why there's no "Congratulations to the winners!" since Round #312?
Anyway, congratulations for winning the round and good luck for your IOI jqdai0815!
UPD: it's been added.
For Div2 E, is there any notation as to how the points are placed? For example, is (1, 1) the top left of the board or the bottom?
(1, 1) is top left.
No Euler circuits, so an easy win for jqdai0815 :P
Also no tourist :P
A significant piece of code in his Div.1 D(12174436):