


Problems proved to be much harder than we expected. There were some corner cases we didn't include in pretests, so many solutions failed, which was definitely a mistake. Anyway, I hope you find this problemset interesting!
Problem A. GukiZ and Contest
Very simple implementation problem. Just implement what is written in the statement: for every element of array, find the number of array elements greater than it, and add one to the sum. This can be easily done with two nested loops. Total complexity O(n2).
Solution: link
Problem B. ZgukistringZ
First, calculate the number of occurences of every English letter in strings a, b, and c. We can now iterate by number of non-overlapping substrings of the resulting string equal to b, then we can calculate in constant time how many substrings equal to c can be formed (by simple operations on the number of occurences of English letters in c). In every iteration, maximise the sum of numbers of b and c. Number of iterations is not greater than |a|. At the end, we can easily build the resulting string by concatenating previously calculated number of strings b and c, and add the rest of the letters to get the string obtainable from a. Total complexity is O(|a| + |b| + |c|).
Solution: link
Problem C. GukiZ hates Boxes
Problem solution (complete work time) can be binary searched, because if the work can be done for some amount of time, it can certainly be done for greater amount of time. Let the current search time be k. We can determine if we can complete work for this time by folowing greedy algorithm: find last non-zero pile of boxes and calculate the time needed to get there (which is equal to it's index in array) and take with first man as much boxes as we can. If he can take even more boxes, find next non-zero (to the left) pile, and get as much boxes from it, and repete untill no time is left. When the first man does the job, repete the algorithm for next man, and when all m men did their maximum, if all boxes are removed we can decrease upper bound in binary search. Otherwise, we must increase lower bound. Total compexity is 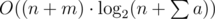 .
.
Solution: link
Problem D. GukiZ and Binary Operations
First convert number k into binary number system. If some bit of k is 0 than the result of or opertion applied for every adjacent pair of those bits in array a must be 0, that is no two adjacent those bits in array a are 1. We should count how many times this is fulfilled. If the values were smaller we could count it with simply dpi = dpi - 1 + dpi - 2, where dpi is equal to number of ways to make array od i bits where no two are adjacent ones. With first values dp1 = 2 and dp2 = 3, we can see that this is ordinary Fibonacci number. We can calculate Fibonacci numbers up to 1018 easily by fast matrix multiplication. If some bit at k is 1 than number of ways is 2n — \t{(number of ways bit is 0)}, which is also easy to calculate. We must be cearful for cases when 2l smaller than k (solution is 0 then) and when l = 63 or l = 64. Total complexity is 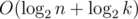 .
.
Solution: link
Problem E. GukiZ and GukiZiana
First we divide array a in  groups with numbers. Every group in each moment will be kept sorted. For type 1 query, If we update some interval, for each group, which is whole packed in the interval, we will add the number it is being increased to it's current increasing value (this means all the elements are increased by this number). If some part of group is covered by interval, update these elements and resort them. Now, let's handle with type 2 queries. When we want find GukiZiana(a, j), we search for the first and the last occurence of j by groups. One group can be binary searched in
groups with numbers. Every group in each moment will be kept sorted. For type 1 query, If we update some interval, for each group, which is whole packed in the interval, we will add the number it is being increased to it's current increasing value (this means all the elements are increased by this number). If some part of group is covered by interval, update these elements and resort them. Now, let's handle with type 2 queries. When we want find GukiZiana(a, j), we search for the first and the last occurence of j by groups. One group can be binary searched in 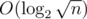 , because of sorted values, and most groups will be searched. Of course, for the first occurence we search for minimum index of value of j, and for the last occurence maximum index of value of j in array. When we find these 2 indexes, we must restore their original positions in array a and print their difference. If there is no occurence of j, print - 1. Total complexity is
, because of sorted values, and most groups will be searched. Of course, for the first occurence we search for minimum index of value of j, and for the last occurence maximum index of value of j in array. When we find these 2 indexes, we must restore their original positions in array a and print their difference. If there is no occurence of j, print - 1. Total complexity is 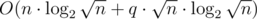 .
.
Solution: link






Hi this was my exact solution for problem E; but I get MLE. Can anyone tell me why? 11555983
I personally can't find anything wrong with your code..
I had the same problem, it was because I used set. When the complexity is for queries is O(Q*sqrt(n)*log2(sqrt(n))), my code would generate at the worst case up to 300000000 new set, which is definitely not ok.
Could you tell me why my code is giving TLE test #23? 11554583 I think my algorithm is O(4*26*|a|). I can't find the error :(
Because multiply of minC * let[2][i] can be more than int. MinC <=1e5, let[2][i] <=1e5 . Very tricky. I have the same problem.
When declaring the variables as global in the same code it works O.o 11560581
I had the same problem, you have an uninitialized variable
ans, so it's value can be anything.And in our case it was a large value, so the program keeps printing the second string until it gets TLE.
A bit too hard for Div2, the solution ideas are great though. Not even sure if it was a good or a bad round, to be honest.
is there an online/offline solution of Problem E using Segment Trees?
I have a different solution for problem E that works in less than one second for the given test cases.
This is my submission: 11560232
What is the complexity of your solution? If a type 1 operation creates at most 2 new segments, and you iterate over all these segments in every type 2 operation, doesn't it make it O(N*Q) in the worst case?
Yes, theoretically, something like that. If half the operations are type 1 and half are type 2, and all the type 1 operations create new 2 segments and are small enough so that no segment ever goes beyond 109, then the total number of operations would be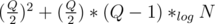 , or something like that, but it seems the test data is very weak, that's why I said "for the given test cases" in my original post.
, or something like that, but it seems the test data is very weak, that's why I said "for the given test cases" in my original post.
It's difficult to design test data for such unusual solutions. Nice solution by the way, it seems for the given test cases, even my O(√N*Q) solution is a tad slower than yours.
This solution 11556101 seems to use your last idea, but I'm not sure why it passes, as it appears to be pretty-much brute force. Any ideas why?
Why greedy solution for problem C works? I get idea intuitivelly, but hav no good proofs. Why we should at first go the farest pile?
Someone has to go there inevitably, so just send the next student and make him collect as many boxes as possible there. If he still has time, make him collect some on his way too, always the ones most to the right (clearing the farthest piles of boxes first means the next students will have to walk less, thus saving time).
To clarify the explanation in the comment above (this helped me understand myself, so thought I might just elaborate): in any valid schedule, at least one student s has to collect boxes from the last pile. Suppose he doesn't move all the boxes at the last (non-empty) pile, but instead spends time moving boxes at an earlier pile. This means at least one other student s' also arrives at the last pile to move boxes. But s can move more boxes at the last pile instead for s', and transfer some of the box work at the earlier pile to student s', since s' had to pass through the earlier pile anyway to get to the last pile, so it doesn't cost any additional moving for s'. By repeated such exchanges, s will end up moving all the boxes he can (within the time limit) in the last pile. If he still has time left, he might as well help move some boxes in second to last (non-empty) pile since he has to go through the earlier pile to arrive at the last pile anyway. And we repeat.
Also, I think this implies that the opposite greedy strategy of sending students one at a time and make them move any left-most boxes before moving onto the next pile is also provably correct (let's call a schedule obeying this constraint "front-first" schedule). This is because given a "back-first" schedule that runs in time t, we can easily transform it into a "front-first" schedule that runs in time t.
I modified the sample solution to use this strategy and passed all the tests.
Thanks for explanations. Really cool idea with front-first. I think about it and can't proof that it is optimal strategy too.
Hello.
Here is my submission for problem B.
On test 3 my code can output a string K of 4 non-overlapping strings: ab, ab, ab, and aca. However, the sample output was only 3 non-overlapping strings.
Any help?
There are only 4 'a' letters, but your algorithm output has 5.
Why doesn't a simple greedy one work for Problem C?
Imagine what happens if you have 2 students and [2 1] array of boxes. The optimal way takes 3 rounds, the greedy algo takes 4 rounds.
Thanks a lot for the explanation, we missed it.
Even I had a similar algorithm. But the greedy strategy I applied was from 0 to n. As the students move into the piles, they clear the boxes. The problem comes when you need to take care of multiple piles of length 0. Also Consider 2 5 3 7 Initially when 3 are lifting pile 1, 2 would have reached 5 and by the time the previous 3 reach the second pile, the two already there would have lifted two boxes. A thing similar to this, I am unable to find in your code. Shouldn't there be a while loop saying while(boxes(i)>0)...
What's wrong with my solution for problem D? Why did I get wrong answer on test 16?
My code
This test case asks you to count numbers below 264 but you stop at 260 (or so).
That's the loop I used to calculate binary-bit array of k.
Since 2^60 = 1 152 921 504 606 846 976 > 10^18, no number k will have 60-th bit equal to 1. The same is true for bit 61, 62 and 63-th bit of k. So, it isn't necessary to check if these bit equal to 1 (their default value is 0).
And the final loop I used to calculate the answer:
It has covered all bit of k (from 0 to l-1).
(Please tell me if something in this comment was wrong)
Sorry, didn't notice that. In this case the problem is that last positions are filled with zeros, not '0' characters.
Oh, I totally forgot about this. Thanks a lot!
Is there a way to/place where we can see how many of the participants in a given round were in division 1/ division 2 at the time of participating?
http://codeforces.me/contestRegistrants/551
That helps, but that includes people who didn't actually end up participating?
I think so.
Even if I were smart enough to figure out the solution for problem E, I would never risk implementing an algorithm of such high asymptotic complexity in a programming contest.
Hello guys,I am little weak in strings :( Can anybody explain me what was asked in DIV 2 B.In simple words and the editorial too :).Many thanks
We want to use letters in string A, to build as much B or C as possible.
e.g.
A: keekeejj
B: kee
C: ej
we can make K : kee kee jj,so we have 2 B,we get 2
if we make K: kee k ej ej, we have 1 B and 2 C,we get 3
so we can make K:keekejej or ejejkeek or ejejkeek...
editorial: we can enumerate if we make 0 B, how many C we can make
if we make 1 B, how many C we can make
....
and we get max B + C
Hope it helps.
That was helpful . But I guess it will get TLE?
Depends on the way you implement it! I got TLE twice during the contest, had to reduce the number of times I did string formation to a minimum.
Time complexity is O(n),n is max number A cobtains B,and here is my submission.
11561839
Why is it necessary to enumerate through 0 B, 1 B, 2 B, 3 B... MAX B?
I thought that we can just test MAX B, and then MAX C with what's left. And then use the same thing but with MAX C first and see which way is greater?
I did it ,too. But cannot past pretest.I wonder why.
It doesn't work on this case:
aaaaaabbbbbb aab abbThanks to zadrox for the test case! Link
So the answer is not necessarily going to maximize string B or C. We can sometimes get a greater answer if we use a combination of B and C.
On problem B,the same method,but i got a TLE,who can help me?11562139
I did the same thing as you. The only difference is that i iterate the b string only till a. size() /b. size() and store the count after taking i times string b in a new_count, for later reference, to reduce no of times it's calculated.
Don't know if that made a difference...
my submission —11556629
I used BIT for problems A @@ lol so stupid. I wasted my time :(
Problem B: Can anyone explain why the greedy method would fail here? Taking max(maximum b then c, maximum c then b) from string given
Sorry, I meant this: If b = "aab", c = "abb" and a = "aaaaaabbbbbb", greedy answer is 3, but real answer is 4: "aab" + "abb" + "aab" + "abb".
Thank you for your reply very much.
test
aacaacbbaac
aac
ab
greedy algo: 3
correct answer: 4
Which test case am I missing for Div 2 A ? 11549286
I replace your comparetor to this one and got AC:
bool mycmp( pair<int,int> a,pair<int,int> b) { return a.second < b.second; }
Submition: http://codeforces.me/contest/551/submission/11584228
You forgot "return" at your comparator:
if(a.second < b.second) true;
Of course, for the first occurence we search for minimum index of value of j, and for the last occurence maximum index of value of j in array. When we find these 2 indexes
how we can find 2nd index? with hash of values,but then how update?
You can binary search both of them through the sorted groups of elements, which are sorted by value and index.
elements, which are sorted by value and index.
on each sorted subgroup: we should binary search on indexes,but what is the answer for this segment? I mean,it's MAXindex-MINindex on segment,and how you are finding them?
You don't have any segment in query, you just need to find minimum and maximum position of occurrence of some number j in array (if I understand your question).
ohh I got it,so stupid question :)
Problem B was very similar, albeit a little bit more general, to this problem: http://codeforces.me/contest/519/problem/C
The idea (How many to take form the first kind, how many to take form the second kind?) is exactly the same.
Surprisingly, it was solved by 1750 coder, in contrast to this contest.
Why compexity of C is
O(n*log n)? In your solution upper bound of binary search is suma_1+...+a_n. And for every call of binary search you useO(m)operations . So I think that total compexity must beO(m*log(a_1+...+a_n)).PS. Sorry if I wrong but I have no idea how did you get your compexity .
UPD . I'm not sure that every call use
O(m)operations . It can be something likeO(m+n)but it's compexity must depends ofm(your compexity doesn't depend ofm)You are right, if we want to be strict total complexity is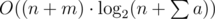 . Look at the lower and upper bound before binary search in the solution.
. Look at the lower and upper bound before binary search in the solution.
Where can I find the I/O test cases for problem B? I need it because my code fails test 7 and i want to find put what is so special about that test.
You cannot, but I see from checker log of your submission 11559886 that your solution cannot be obtained by swapping letters of input string.
Yeah, I know, but i can't create that bug :(
One thing you can do is:
1) make test cases by yourself.(I usually write script. it's not that hard)
2) Run someone's AC solution and your solution
3) Compare outputs
Test which your code fails contains 100000 "a" characters in string a, and b = c = "a".
In problem D, why the case l=63 and l=64 has 0 as answer ?
Actually, they don't. I'm sorry if I wasn't clear in editorial, 0 is solution when 2l ≤ k, and you must be careful when l ≥ 63 because 2l cannot fit into long long then.
http://codeforces.me/contest/551/submission/11571171
On my pc it's giving the correct answer, but on codeforces output, it shows zero ? Can you look at it please for once ?
1ll << linstead of1l << l:)It seems to me, or E is easier than C and D? There is the obvivous usual sqrt-decomposition. I think many people would solve this problem, if it were C or D. Because so many of the participants look at the complex problems after the contest, as they do not solve B, C, D, and have no reason to look any next. All the more that the time limit allowed to send the solution with the high constant (I have send solution for q*(6*sqrt(n)*log(sqrt(n))+n) instead of the author's q*sqrt(n)*log(sqrt(n)). Thanks for the contest!
10 seconds is probabily too high for time limit, but Zlobober proposed this. Problems B and C are harder than usual, but I don't see why is problem D so hard. From my point of view, it has quite straight forward solution, but there are cases that require extreme care when dealing with them, and it proved to be wrong not to put them in pretests.
Yes, you are right. Though I think D would be even more interesting if n,k,l and m were all <= 10^18.
Any ideas on how we will handle it if l was not guaranteed to be a power of 2?
Given the constraints in the original problem, I can't think of any solution.
Keep doin' it til' ya do it :)!
I had some 30 incorrect submissions in this problem :( But got it finally :)
Problem D. Can someone explain me? Why for test 3 3 2 10 answer is 9? In my opinion, answer should be 5. All possible combination Thanks!
0 3 3
3 3 0
3 3 1
1 3 3
2 3 3
3 3 2
3 3 3
1 3 2
2 3 1
You haven't considered 0 0 3. (0 and 0) or 3 = 3. Why I'm not right?
0 0 3
(0 and 0) or (0 and 3) = 0 or 0 = 0
Thanks!
Is there an online/offline solution of Problem E using Segment Trees? Someone has asked before, but no one answers. Here is my submission Yeah, its worse case will get O(nq), cannot pass the problem, and I also got TLE on test 12. Just because these times I was practicing the segment trees' pros, I hope someone can help me. I will appreciate it if someone has the answer.
No, couse there no function to update a segment with O(u) < O(n) or I can`t imagine this function=)
thx all the same. I also cannot think function to maintain that — -
For Div. 2, Problem B, why does it not work to:
abbbaaccca ab acaString A has 4a, 3b, 3c
I can fit 3 of string B in A
Now I have 1a, 0b, 3c
I can't fit string C
3 + 0 = 3
Now the opposite order:
String A has 4a, 3b, 3c
I can fit 2 of string C in A
Now I have 0a, 3b, 1c
I can't add string B
2 + 0 = 2
This first test had the higher result, so the answer is 3.
Try this test case, aaaaaabbbbbb aab abb
Your solution gives output as 3 (aab aab aab OR abb abb abb), while optimal solution is 4, aab abb aab abb.
Thank you so much! This really helps :)
nikola12345 my solution for problem E have the same complexity as yours but it give me TLE what's wrong this is my code 11586909
For Problem C:
Here is my submission.
Can anyone help me with a test case?
In your can funcn, since you re using forward approach, when you use a single student to finish more than one jobs, you need to subtract the time needed to traverse from one position to the other. You haven't considered that.
It is a strange problem. The program works correctly in my pc but gives me a wrong answer when submitted. To be precise it shows that my result is 0 while when the same code is run on my pc the answer that comes matches with that of jury's answer. Here is the submission link: 11593383
I think you're having the same issues I did. Switch 1l to 1ll. (if you use 1l, then if the parameter l >= 32 then (1l << l) would wrap around since 1l is interpreted to be a 32-bit integer. This makes your program pass the check (1l << l) <= k and return 0 prematurely). Not sure why; difference in compiler? Also, be careful with subtracting and mod in C++. For instance, -1 % 3 evaluates to -1, not 2. You can just do (-1 + 3) % 3 to be safe.
1
For problem E, it seems that a lot of the solutions that use a map based implementation (within each group, map from integer y to its earliest and last occurrence) goes over the time limit, while the sorting implementation (as described above in the editorial) does fine. This seems bizarre to me as the map based implementation shouldn't be any slower asymptotically (and perhaps as faster update if we use a hash map). Why might this be? This seems to be due to the higher efficiency of a C++ vector. But in that case, the input sizes seem to be a little harsh and unnecessarily eliminating the map-based solution.
In the editorial of problem D you wrote — \t{(number of ways bit is 0)}. Is it a typo? I'm asking because that '\t' doesn't make any sense. BTW, problem D was really great!!! :D
— \t{(number of ways bit is 0)}. Is it a typo? I'm asking because that '\t' doesn't make any sense. BTW, problem D was really great!!! :D
I think the \t is just a byproduct of latex/formatting. He just meant 2^n — (number of ways bit is 0).
Cannot get AC for problem D 551D - GukiZ and Binary Operations.
Here is my code: 11604669
I'm getting WA on 10th test case
1000000001 1000000002 37 1000000007
Output: 187032448
Answer: 472514342
Can someone give me an idea where I'm wrong? Thanks in advance
What is wrong with it? There is some overflow here?
It seems that it's not the only problem in my solution, because changing that check to
if ((new BigInteger(Long.toString(k))).testBit(bit))gives WA on 16th test case 11607178Yes.. An overflow. Don't need to use BigInteger. Long is enough.
Yes, I already wrote it using Long, but it didn't help to get AC.
So & can be used only for Integer, not Long?
You should modify the last cycle as above.
& can be used for both of them. The problem was in (1 << bit) which is an Integer, but bit was > 31, so you got a negative value.
Ahhh.. Ok, understood now! Thank you
It's interesting that I have a line above
if (l < 63 && k >= (1L << l)) {that uses 1L not 1 :-)
My solution in B div2 got WA on test 12 .. My code idea depends on get how many string b i can get from a then how many c ... then replace b , c and maximize the result .
is that a case that this idea didn't work ? or can anyone provide me a sample test to drop this ? http://codeforces.me/contest/551/submission/11568722
http://codeforces.me/blog/entry/18508?#comment-235560
dp(i) = dp(i - 1) + dp(i - 2)
What is the idea behind this equation in problem D ?
http://math.stackexchange.com/a/1280549
Thanks.
Hey I wrote this code for problem C the strategy that I implemented was
For every time unit if number of students is greater then the number of boxes then the difference of student and boxes will forward to the next box and the remaining will take care of the boxes.
So on each step student will start from the beginning on each block a[i]/m student will stay whichever is minimum and rest will go to the next stop. until all the boxes are picked.
Got wrong answer on test case 4 can anyone please tell me what is wrong with this strategy.
submission
can anyone tell me where did i do it wrong?11836732
Thanks
I was trapped into some terrible small mistakes solving Problem D! First I got WA10, because the number (1<<64) can't be expressed so you can't check by if(k>(1ULL<<l))! And then I got WA18, I surprisely found out that m=1... So we should initialize ans: ans=1%m but not: ans=1!!!
Getting wrong answer in Problem E on 53 no test case... Can't see the test case... Can anyone help me? Here is my submission: 11946047
how to prove complexity of C ? Why the complexity is (n+m) ?
Problem C: why doesn't this approach work? The time taken overall to reach the boxes will always the the index of the farthest non-zero pile of boxes. What we really have to do is only distribute the boxes among the students in optimal time. How does it matter if we send the first guy to the last non zero pile and then send other people? Every non zero box has to be covered atleast once. Also it seems counter-intuitive to me that me send the first guy to the last pile and then send other people. He will have to cover the distance all the way and plus the time taken to come backwards. Instead, why can't we assign the a sequence of boxes from the start to end?
I know this is late, but it's possible to accept this problem by subtracting from the front. ( it actually makes much more sense to me..).
I'm also doubtful about subtracting from the end...
Here is the submission, remove first greedy approach.
http://codeforces.me/contest/551/submission/15264958
Yes, it is the same thing. For us, substracting from the behind was more natural, but both approaches are correct.
I am unsure if this is a correct way to prove both ways are similar so please correct me if it is not the case. First the array can be flattened so that for each a[i] we include a[i] indexes. Therefore the array will contain the sum over a[i] indexes. Next we note that all optimal answers are to be partitions on this new array. Lets denote f(i) to be the maximum index we can get to if we start choosing all elements from i. Let's also create f^-1(i) to be all the elements we can get to if we do the operation starting in reverse from i. It can be seen that f^-1(f(i)) = i. Now in the worst case we have f^m(0) = N. Through algebra we can see this implies f^-m(f^m(0)) = f^-m(N). Or 0 = f^-m(N). This means that in worst case if we apply the operation m times from front it also means we can apply operation m times from back. In cases other than worst case we have similar but always better results.
the first guy doesn't need to come back
Could anyone please help me? Problem E. I don't understand what's wrong with my solution... 14473801
I've done it.
damn, solution to problem E is awsome
In Problem D, can someone explain how dp[i]=dp[i-1]+dp[i-2] ?
Using Hash tables for problem E could offer a better time complexity $$$O(n + q \sqrt n)$$$.