


Can anyone recommend resources for preparing for the Distributed Code Jam on June 14th? Some past problems of a similar nature would be really helpful.
→ Pay attention
→ Top rated
| # | User | Rating |
|---|---|---|
| 1 | jiangly | 3898 |
| 2 | tourist | 3840 |
| 3 | orzdevinwang | 3706 |
| 4 | ksun48 | 3691 |
| 5 | jqdai0815 | 3682 |
| 6 | ecnerwala | 3525 |
| 7 | gamegame | 3477 |
| 8 | Benq | 3468 |
| 9 | Ormlis | 3381 |
| 10 | maroonrk | 3379 |
→ Top contributors
| # | User | Contrib. |
|---|---|---|
| 1 | cry | 168 |
| 2 | -is-this-fft- | 165 |
| 3 | Dominater069 | 161 |
| 4 | Um_nik | 159 |
| 4 | atcoder_official | 159 |
| 6 | djm03178 | 157 |
| 7 | adamant | 153 |
| 8 | luogu_official | 150 |
| 9 | awoo | 149 |
| 10 | TheScrasse | 146 |
→ Find user
→ Recent actions





Codeforces (c) Copyright 2010-2025 Mike Mirzayanov
The only programming contests Web 2.0 platform
Server time: Jan/31/2025 10:46:12 (j2).
Desktop version, switch to mobile version.
Supported by

One problem which appeared in AE last year was to compute LCS of two strings up to 105 characters.
Some Simple Problems :
Problem 1
Given a Sequence A of integers , find i and j such that A(i) + A(i+1) ...+ A(j) is Maximum/Minimum , where length of A can be upto 10^10 . TL : 1 sec
Idea
Basically , we divide A into say 10^8 lengthed 100 segments , and then process each of them on different machines and later combine the information to find the answer .
Problem 2
Given a number N as large as say 10^20 , find it`s number of divisors .
Idea
Divide the set of possible divisors <= 10^10 , into 100 groups and then add the result from each of them.
But problem 2 can be solved on a single computer, there is probabilistic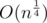 algo
algo
By the way, I always wonder why people don't multiply the complexity by log(n) which goes from finding gcd on every step? Let alone multiplying it once again when we work with big numbers and every operation consumes not constant, but logarithmic amount of time.
Because on average gcd will not really be log, and with sensible limits big numbers is just a constant
Because on average gcd will not really be log
How to prove it? If I got you right, you say that there is an upper bound for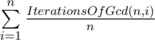 that is better than log(n).
that is better than log(n).
It's indeed O(log(n)) number of steps on average. About Pollard's rho algorithm, probably textbooks usually mention only expected number of iterations to avoid analyzing complexity for different arithmetic operations implementations.
Thank you for the link!
Yeah, your claim is correct for elimination of the second log(n), but after reading the wiki article I still have no idea why they don't mention the first one in the expected complexity.
Problem
Given a sequence of N(<=10^10) integers , find if there exists a Majority element.
Idea
Divide sequence into say K segments , then we process each of them individually to find candidates of Majority element and then the Majority element itself , if any .
So Complexity reduces to O( N / k )