


Div.2 A — Cursed Query
You should make a sequence s1, s2, ..., sn such that si = a1 + a2 + ... + ai and use a binary search to find the first element that is greater than t % sn (or upper_bound function in C++ ).
Source code : Here
Div.2 B — Troynacci Query
First of all, compute sequence f (0-based), then consider we have a sequence p (also 0-based) (partial sum), initially all members are 0.
For each query, if l < r, then do :
p[l] = (p[l] + f[0]) % mod;
p[l+1] = (p[l+1] + f[1]) % mod;
p[l+1] = (1LL * p[l+1] + mod - 1LL * ((1LL * b * f[0]) % mod)) % mod;
p[r + 1] = (1LL * p[r+1] + mod - f[r - l + 1]) % mod;
p[r + 2] = (1LL * p[r+2] + mod - 1LL * ((1LL * a * f[r-l]) % mod)) % mod;
otherwise, do this :
p[l] = (p[l] + f[0])%mod;
p[r+1] = (1LL * p[r+1] + mod - ((1LL * b * f[0])%mod))%mod;
p[r+2] = (1LL * p[r+2] + mod - 1LL * ((1LL * a * f[0])%mod))%mod;
An the just run this : for every i, staring from 0, pi + = a × pi - 2 + b × pi - 1 and ai + = pi .
Source code : Here
A — LCM Query
If we have an array x1, x2, ..., xm and for each i, 1 ≤ xi ≤ 60, the number of different element in the array y1, y2, ..., ym such that yj = lcm(x1, x2, ..., xj), is at most log(60!) .Because y1 ≤ y2 ≤ y3 ≤ ... ≤ ym and if yi < yi + 1, then yi ≤ 2 × yi + 1, and ym ≤ 60! .
Actually, it is even less, like 25.
So for each i, you can find all these members for array ai, ai + 1, ..., an using at most 25 binary searches and save them in an array.
And if x = p1b1 × ... × pkbk such that all pis are prime an k = the number of primes less than 60, then we assign sequence b to x. Using this, you can easily see that if x = p1b1 × ... × pkbk and y = p1c1 × ... × pkck, lcm(x, y) = p1max(b1, c1) × ... × pkmax(bk, ck). And for check if a number is less than another one using this sequence b, you can use log function and the fact that log(x) = log(p1b1) + ... + log(pkbk), so if log(x) < log(y) then, x < y, and this is how to calculate the minimum value.
By the way, you can calculate lcm(al, al + 1, ..., ar) in O(25) using Sparce Table.
Source code : Here
B — ShortestPath Query
Consider, for each vertex v an each color c that there is at least one edge entering v with color c, we have the length of the shortest path from s to v such that it's last edge has color c (we call this dv, c). So, with this, you can make a graph with states (v, c) and run a Dijkstra on it and it's easy update.
But this will get TLE.
If you think about that, you don't need all states (v, c), among all these states, we just need the first two states with minimum value of d (for each vertex v).
Source code : Here
C — Subrect Query
First of all, let's solve the 1-D version :
we have two sequences a1, a2, ..., an and b1, b2, ..., bn and for each i, we know that bi ≤ ai. Our goal is to calculate the number of pairs (l, r) in O(n) such that 1 ≤ l ≤ r ≤ n and max(al, al + 1, ..., ar) - min(bl, bl + 1, ..., br) ≤ k .
We use two double ended queues (deques) for this propose :
let mx, mn be two empty deques
l = 1
ans = 0
for r = 1 to n
while !mx.empty() and a[mx.back()] <= a[r]
mx.pop_back()
while !mn.empty() and b[mn.back()] >= b[r]
mn.pop_back()
mx.push_back(r)
mn.push_back(r)
while a[mx.front()] - b[mn.front()] > k
l ++
if mx.front() < l
mx.pop_front()
if mn.front() < l
mn.pop_front()
ans += r - l + 1
In this code, for each r we are finding the largest valid l, and by the way a[mx.front()] = max(al, al + 1, ..., ar) and b[mn.front()] = min(bl, bl + 1, ..., br) .
Now let's get back to the original problem.
For each pair (i, j) such that 1 ≤ i ≤ j ≤ m, build arrays a1, a2, ..., an and b1, b2, ..., bn such that ak = max(ak, i, ..., ak, j) and bk = min(ak, i, ..., ak, j) and then run the code above.
Except that C++ deque is too slow,so you should write one.
Source code : Here
D — TROY Query
For each row or column, it's not important how many times we run the operation on it, the only thing matters, is that it's odd or even.
So, assign a boolian to each row and each column, such that row number i's boolian is ri and column j's boolian is cj.
The other things are like 2-sat, except that the graph in this problem will be undirected.
For each query, if ax, y = bx, y so we know that 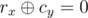 so add an edge between rx and cy and one between ¬rx and ¬cy.
so add an edge between rx and cy and one between ¬rx and ¬cy.
Otherwise, add an edge between ¬rx and cy and one between ¬cy and rx .
You can use a disjoint set with array or vector and in each step, check if a boolian like x and ¬x are in the same component, print "No" for the rest of the queries (Because when the answer to a query is No, the answer to the next queries will be also No).
Source code : Here
The other approach is to use binary search on the last step with answer "Yes" and check using a normal 2-sat (directed graph.)
Source code for this approach : Here
E — Palindrome Query
Use Robin-Carp. Let's consider that hi ≡ s1 × p0 + s2 × p1 + ... + si × pi - 1(mod m) .
For a query of type 2 or 3, just use a simple binary search.
For a modify query, if y = x - sp, you should add y × p0 to hp, y × p1 to hp + 1 and so on. You can do all these using a segment tree or fenwick (BIT).
Source code : Here
F — Tree Query
Use divide and conquer on the tree (centroid decomposition) and answer queries offline.
For conquer, imagine root is r. Run dfs on r and for each vertex, push it's distance to r in the vector e. Then sort e and for each vertex v in subtree of r and query o such that it's asking about v and number l, do this : ans[o] += the number of members of e like p such that p + d(r,v) <= l (using binary search).
But here, we counted some vertices for some queries more than once.
Then for each neighbor of r do this separately:
Run dfs on it's subtree and for each vertex, push it's distance to r in the vector z. Then sort z and for each vertex v in this subtree and query o such that it's asking about v and number l, do this : ans[o] -= the number of members of z like p such that p + d(r,v) <= l (using binary search).
Source code : Here







thank for nice problem :)
Really nice editorial and thanks for adding source codes :D
nice solution for problem B Div 2 :)
Well...In problem C,I have't realized the Array can be so long...T_T
const int N = 404;int mn[N][N]N
I finished it by rmq.May be use rmq query the biggest and smallest is better .
Thanks for solutions,and thanks for problem's tags before the solutions.(I solve all problems by tags and tags Allows me to be more independent thinking!) Nice problems and nice solutions! :D
Why can't i see the solutions of other contestants? I'm new.
Because this is a GYM contest. GYM submissions are not visible until you solve the problem.
Can you please explain problem B Troynacci Query more?
I can not understand.
Read this (partial sum) before that.
I have read this and understood but cannot find the logic of the solution of problem B. Can you explain more? :|
In div2 A testcase 13 when I define
maxn 100000+10it gets WA butmaxn 100000+100gets AC How come??Just a fun question, does the "Khikulish" sentence in Div2 problem A mean anything?
Khikuland is a very useful name for countries in problems of INOI (Iran Olympiad in Informatics).
Plz Anyone explain me solution for problem B.I also tried to understand partial sums from given link,but i could not.Plz help.
Problem F :
It can also be solved by answering the queries online (using centroid decomposition). We decompose the given tree and for each node in the centroid tree , we maintain the following two vectors :
ans[u] = sorted vector of d(x,u) for all x in the subtree of u in centroid tree, where d(x,u) represents the distance between node x and u in the original tree.
cntbn[u] = sorted vector of d(x,par[u]) for all x in the subtree of u in centroid tree, where d(x,par[u]) represents the distance between node x and par[u] in the original tree. (par[u] is the parent of node u in centroid tree).
Since, there are at-most logN levels in centroid tree, and at each level we are storing O(N) values of ans/cntbn, total memory required would be O(NlogN). Also, these vectors can easily be build in O(NlogN) or O(Nlog^2N) time by moving up node u (for all u) in centroid tree and adding the corresponding values in all the ancestors of u.
Given this information, each query would now reduce to
http://codeforces.me/gym/100570/submission/12316350
First of Thank you for the blog, Baba!
this problem is so elegant to be solved using Centroid decomposition, that I cannot keep myself from appretiating.
All the submissions for this prob are hidden. So I am posting my solution here for convenience.
If anyone is not using windows and want to see what is going on use -DWIN32 as a flag and if someone on windows wants to remove all the excess messages -DWIN32 flag while compiling.
Found It :| , I used cnt[u] instead of cnt[cur]
Getting WA on test case 3...
Can you check this solution, https://ideone.com/yIUf9t
In the code of the Problem F, can you please tell me why you have written
w-h[u]in line 70 and 71?reason : we only calculate the node which one not connected further when we remove centroid.
Can you please prove problem B solution.
An explanation for the first approach: when you get a query {l, r}, you need the following change:
Suppose you keep an array
p[], initially all zero, and do this:And now if you apply the recursion
p[i] += a*p[i-2] + b*p[i-1]for all i, you get the corresponding update. I'll try to show this too:See that once you start applying the recursion on array p[], this is the result:
now that you have successfully got
p[l] and p[l+1]asf[1] and f[2]respectively, you'll get f[i] correctly up to p[r] because of the formula you are applying constantly.Beware, you don't want these values to affect further. Hence we need to keep some values at p[r+1] and p[r+2] already so that their net values after this recursion turns out to be zero, if we do this correctly, no further effects will be observed starting from p[r+3], since previous 2 values will be 0 then.
This is why we've got (3) and (4):
Hence, once you make the changes (1), (2), (3), and (4) to array p[], you have assured that the corresponding query will be handled as soon as we do the recursive additions in p[].
And hence you may as well do this recursive addition at the very end, to result in
O(n+q)solution.Check it yourself that the author has provided exactly these 4 updates for each query {l, r}.
Thank you very much. Finally I can understand the solution.
He was waiting for 9 months to get this reply from you. Thanks for making his long desired wish true :P
xD. I read the problem long time ago. But I din't read the editorial before. It help me a lot. (Sorry for my poor English)
Can someone explain problem LCM QUERY of div 1 A I am facing difficulty in understanding these lines of editorial
If we have an array x1, x2, ..., xm and for each i, 1 ≤ xi ≤ 60, the number of different element in the array y1, y2, ..., ym such that yj = lcm(x1, x2, ..., xj), is at most log(60!) .Because y1 ≤ y2 ≤ y3 ≤ ... ≤ ym and if yi < yi + 1, then yi ≤ 2 × yi + 1, and ym ≤ 60! . Actually, it is even less, like 25
Thanks!
Can someone explain why we add MOD value in the middle of expression when the answer is asked to be mod? Isn't it enough to just calculate all values and take their mod?
In cpp % (**modular division**) operator may return negative values, whereas we don't want any negative values here. So, to ensure the remainder we get after using % operator is non-negative, we add mod to the expression.
output: -1
In python there is no such issue, and we also get a non-negative result on using the % operator.
(Removed)
I know this comment a bit stupid.
but i can't reason why this code is failing for F? i was practicing centroid decomposition this is the first problem i got stuck at.
Info about code :
The code is based on very same logic as written in tutorial.
Data:
tree(vector<vector<array<int,2>>) it store node and weight.d[17][N]it stores weight of path from a centroid from a certain level to node. e.g.dp[level[par]][node].sz[N]it store subtree size of node.dead[N]it store nodes as 1 if they are dead else 0.level[N]it stores level of a node in centroid tree.par[N]it stores parent of a node in centroid tree.list(N)it store the node that is a child of its parent in centroid tree.dist (vector<map<int,vector<long long int>>>)it stores required weights of path vectors for each node.functions :
subtree()it calculates subtree sizes and return the size of mega node.OneCentroid()it returns centroid of tree.Decompose()it decomposes and main function for centroid decomposition. it also calculates the the required weight of paths vectors.caldist()it calculated weight of paths vectors.solution()just a fancy funtion to call decomposeans()it process query.Thankyou if you can help.