


From https://openai.com/index/learning-to-reason-with-llms/:
We trained a model that scored 213 points and ranked in the 49th percentile in the 2024 International Olympiad in Informatics (IOI), by initializing from o1 and training to further improve programming skills. This model competed in the 2024 IOI under the same conditions as the human contestants. It had ten hours to solve six challenging algorithmic problems and was allowed 50 submissions per problem.
For each problem, our system sampled many candidate submissions and submitted 50 of them based on a test-time selection strategy. Submissions were selected based on performance on the IOI public test cases, model-generated test cases, and a learned scoring function. If we had instead submitted at random, we would have only scored 156 points on average, suggesting that this strategy was worth nearly 60 points under competition constraints.
With a relaxed submission constraint, we found that model performance improved significantly. When allowed 10,000 submissions per problem, the model achieved a score of 362.14 – above the gold medal threshold – even without any test-time selection strategy.
Finally, we simulated competitive programming contests hosted by Codeforces to demonstrate this model’s coding skill. Our evaluations closely matched competition rules and allowed for 10 submissions. GPT-4o achieved an Elo rating3 of 808, which is in the 11th percentile of human competitors. This model far exceeded both GPT-4o and o1—it achieved an Elo rating of 1807, performing better than 93% of competitors.
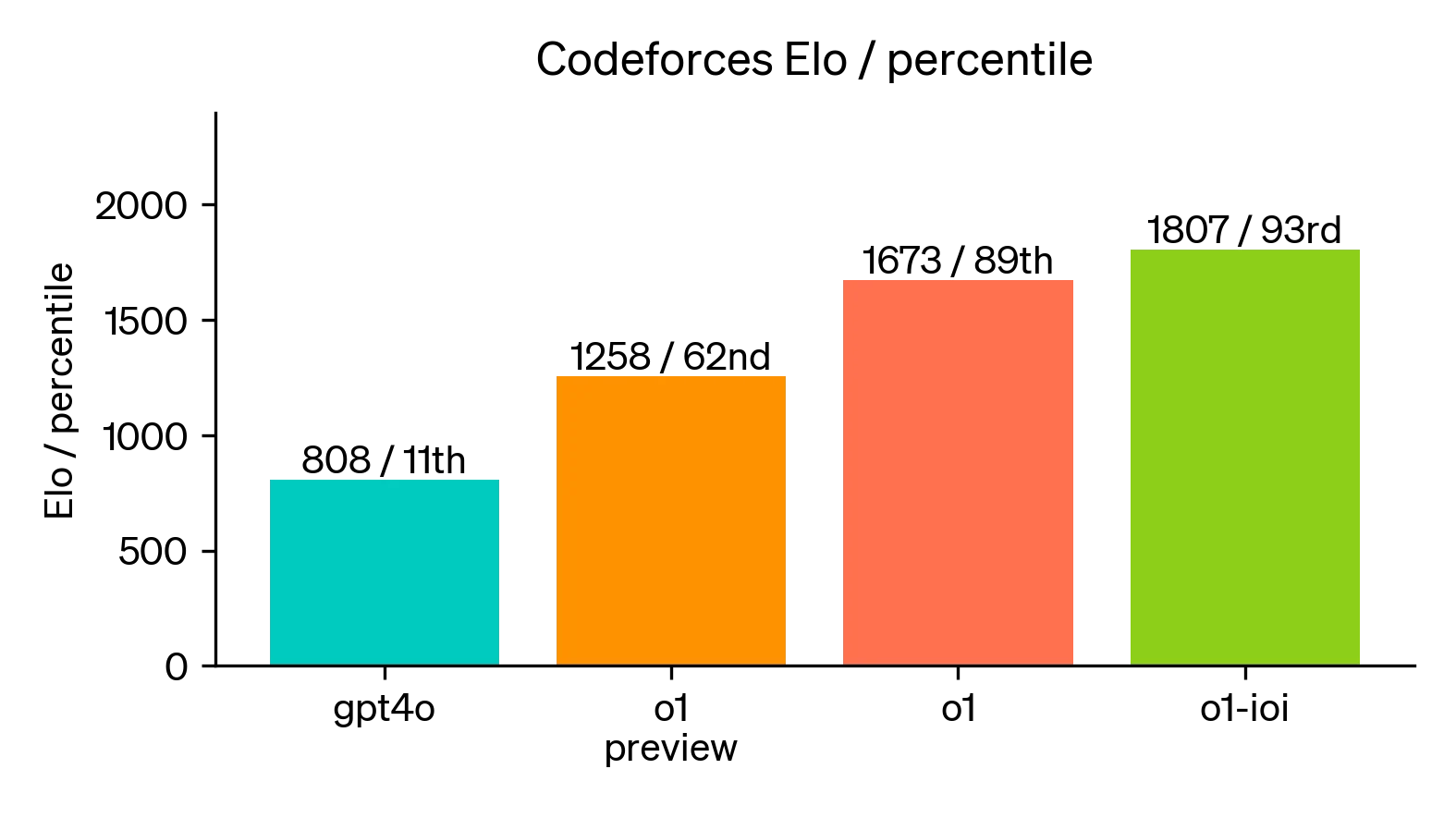






This is so much more impressive than I thought would be achieved even in the next 4 years.
So to make it clear what models have what:
https://openai.com/index/learning-to-reason-with-llms/
https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/
The strongest model, o1-ioi, was fine tuned on competitive programming problems. 1807 rating. Not available to the public at the moment.
The next strongest model is o1, 1673 rating. Not available to public.
o1-mini is publicly available and 1650 rating.
o1-preview is publicly available and 1258 rating.
The naming is kind of confusing, because o1-preview would be expected to be stronger than o1-mini, but o1-mini is actually the strongest.
Time to massively overhaul the cheating detector... or prepare for some insane rating inflation.
I don't think using AI is even considered cheating currently...
Edit: Why is this being downvoted lol
Yeah I'm thinking it's not just about having the AI literally spit out the full solution.
"Hey ChatGPT, here's a problem statement, what algorithm should I use to solve it?" would allow a (current rating system) 1000-level to solve 1800-level problems. It might even allow a 2000-level to solve 2800-level problems by reducing the search space — even if an AI's rating is 1800, it can still help a human do better on harder problems. Of course, it's 1800 now, maybe it will be 4800 soon?
And there's really nothing we can do about it, it will just force programming contests to evolve in some way. With some possibility that online contests will become completely useless. (But we are not there yet)
The truth seems to be that AI will eventually become much better than humans, and humans will continue to compete at much lower level nevertheless. It is crazy to imagine that we will spend our entire life on proving ourselves better than other human beings while any cheap computer will continue to outperform us. This is exactly what happened to the industry of chess. Nobody seems to care though.
Edit : Why so many downvotes? It does sound depressing, but is it not the truth?
i guess my 1600 is not so special anymore
It was never very frankly...neither is mine :/
at least it felt good achieving a blue rank back then :(
anything less than gm is non-impressive?
obviously? (especially in interviews in real companies)
Bro my USACO Gold is no longer so special if this AI get's released to public... Who's gonna be able to tell what is AI and what's not AI???
My 1500 is special
The article says we are releasing an early version of this model, OpenAI o1-preview, for immediate use in ChatGPT and to trusted API users, so the 1258 rating ver. is coming soon.
UPD: It IS now introduced to ChatGPT.
I can imagine a day when I wake up, only to read the news that I basically have lower rating than a bot.
i already woke up to this
This happened to me before bots existed.
That already happened in Chess long back. Before that no one thought a bot can hit GM level. It will eventually come up to cp too it's just a matter of time.
this happened to me today :(
This is concerning
We are all doomed :/
It will not take away your ability to enjoy solving problems.
But no one enjoys solving problems when they starving..hehe, just kidding....or..?
i have neetbux
well, fuck
brevity.
Maybe o1-ioi handle is Scripted1234?
no this seems to be genuine profile unless they used his name
They got 1807 in June before o1 even existed so no.
Development, testing and release takes more than day.
I know but thats like a month ago.
i can confirm i am indeed a real person lol
So my dreams of becoming an expert is gone?
It would've been great to get more information about the IOI performance — especially how the 362.14 score was distributed, how the code looked, and what kind of training was put on top of o1 to produce o1-ioi (and whether that was unbiased)
Maybe I am wrong, but even with unlimited number of submissions I find gold at the IOI extremely impressive compared to 1800 on Codeforces.
We will find out soon. Hackercup starts in 7 days and allows LLM submissions, so we no longer need a custom environment that may or may not be biased.
Agreed.
It would be amazing if they participate in HackerCup's AI track, but I very highly doubt they would do that. By their own metrics the public o1 models aren't particularly impressive at competitive programming.
I agree, also I wish OpenAI was more transparent (it has 'open' in the name...). How are we living in a world where Mark Zuckerberg is releasing the best open source AI models?:))
I think the people behind it are more active on twitter / X. For this particular question: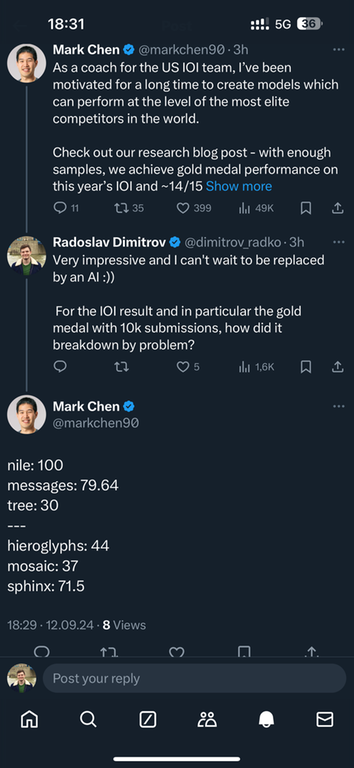
We'll post our solutions soon! Interesting how poorly we do on mosaic versus humans!
Just to follow up, here is a post sharing our submissions! https://codeforces.me/blog/entry/134091
This model is constrained because of the inference cost, so this rating should be viewed as lower bound of what's possible. Highly likely that iterating for longer time during reasoning is going to produce even better results. Would be fun to see an actual paper showing if it's true and if it is what are the diminishing returns related to the time spent during reasoning.
Sadly, the days are not far when a bot will overtake the Masters. More thing to worry is that these models (o1-mini) are available to public.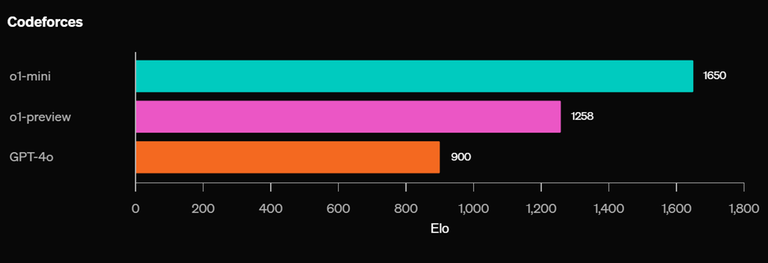
img source
training on test is all you need!
Are the CF contest submissions public?
I would say that the google model that got a silver model at IMO was much more impressive than this
Well, it abused the modern ways of solving geometry(Wu method). As far as I remember the model is still not capable of solving any IMO-level combinatorics task
Just you wait until they become LGMs (maybe even Tourists, who knows).
Couldn't disagree more.
There's a long history in automated theorem proving and automatic ways to solve geometry. 2D geometry in particular is very uninteresting and I don't think that it's particularly surprising that computers can solve it. I'm sure if you went through the IMOs of the past, there were tools that could solve some problems long before the OpenAI models. It is impressive that they scored 4/6, but the two they didn't solve were specifically the combinatorics ones which I would argue require more interesting argumentation rather than algebraic bashing.
For competitive programming tasks, I haven't seen anything that comes close to being coherent prior to this past year. I remember efforts to try and design such AI advertised here on CF as far as 10 years ago, but solving any IOI problem was a ridiculous idea.
Well, go try and solve them yourself. You have unlimited time to do your "algebraic bashing" in P6. If you fail, you can also try to solve number theory P2. These problems aren't as easy as you think they are
You're misinterpreting what I mean — I personally would probably struggle to get a bronze at IMO. I do not claim they are easy for a human in any way. Classical Stockfish without any neural nets could beat the world chess champion very easily. I could train for a lifetime and not be in any way close, and yet with modern computing capabilities I do not find this accomplishment of classical Stockfish to be shocking.
Similarly, while solving P2 and P6 is an amazing accomplishment for the AI, comparatively I consider the accomplishments of the o1 model in competitive programming to be more impressive as an indicator of the AIs abilities. If you had told me that some automated theorem prover had solved P6 without having anything to do with neural nets or machine learning, I'd think it's cool but I wouldn't be shocked. For competitive programming, as I said, even the simplest code generation has been atrocious prior to these latest developments.
Additionally, I also mention the combinatorics problem being failed by the AI because I find P5 to be particularly approachable. I personally believe if you gave P5 to IOI competitors, almost everyone with an IOI gold would solve it. However, being a constructive problem it seems less likely to be solved by some kind of automatic axiomatic tree derivations or repeated theorem applications.
I have to admit that the IOI allowing partial scores gives a huge advantage to the programming AI, because there really aren't "partially correct proofs" in maths, so you could use that point. However, it's pretty hard to argue about that since we don't know how "close" the math AI was to solving the remaining two problems.
In any case, comparing the relative impressiveness of accomplishments on this scale doesn't imply that any of them is easy for a human.
I'm not neglecting the difficulty of generating code or solving Informatics problems, but it's just isn't as impressive as math is. Because writing code for a given algorithm isn't an insanely hard task and modern AI can comfortably do that, and the solutions to most Informatics questions(and IOI in particular) come down to known algorithms with no new smart ideas or any creativity. I myself has witnessed students with almost no talent come through all national challenges and get a medal at IOI by just their hard work for a couple of last years, while in Maths olympiads this is almost impossible. Most difficult combinatorics tasks in most cases can only be solved by a pure talent. You are right that nowadays 2D geometry is of no interest because 1. most strong students can bash it unless it was really chosen to be unbashable, 2. geometry has became a skill that everybody just trains through the years regardless of their aptitude. New discoveries in maths often happen not when somebody finds a topic no one has discussed for several centuries, but when an inside genius of somebody starts glowing and their is an eureka. And in hard olympiad problems(like P6) you also need to think of a smart cunning way to use what you have. The only difference is that you are not the first one to discover this way. Finally, currently it is nearly impossible to make AI's to invent something they have never heard of(such as ideas of the solution of P6). Of course, if you have a functional equation, you can try to "algebraicly bash" it by making a billion of substitutions and praying it will help. But if it is P6, it won't.
This is an insane statement.
You clearly have some bias towards math, which in my opinion is very unfounded. The overlap in the way of thinking for IOI and IMO is quite large, and problems like P5 in IMO 2024 could easily appear in IOI under some modified form.
Perhaps you're not familiar enough with the level of IOI problems, but to say they "come down to known algorithms" is just comical. Sure, it is not uncommon for the final solution to a problem to involve some well-known data structures or some well-known algorithm, but that's not what solving a problem is. The observations required to design a correct algorithm is what the solving consists of, and those observations require very much the same ingenuity that a math competitor uses when making observations about the structure of a math problem. Saying that an IOI problem uses known algorithms is like saying that an IMO problem relies on known theorems and definitions. It is true, but that's not relevant to the actual interesting part of the problem-solving process.
Did someone make a test to confirm that the public o1-mini can actually solve problems up to 1650 rating as claimed?
Yes, it's impressive (although I'm not sure whether it has access to the editorials).
I gave it five 1600-rated problems (2004D, 1996E, 1994C, 1985G, 1980E), and it solved three out of the five (submission links: 2004D, 1996E, 1985G) in one try (after using C++).
Here's the conversation link
Can you try other websites?
I tried AtCoder, here's the conversation (this link doesn't seem to work now somehow, I might change it in the future if this becomes an issue).
I gave it 3 1200-rated problems (ABC361D, ABC361E, ABC362E), 2 1300-rated (ABC363E, ABC367E), and 1 1500-rated (ABC367F). It solved all but ABC361D.
Interestingly enough, it solved both E and F in ABC367. If it also successfully solved A-D, with a fast enough speed, it could've reached a 2400-performance (equivalent to approximately 2526 on Codeforces). AtCoder has policies against the use of AI, but it might not be that easy to detect.
AtCoder problems have a significantly different style from Codeforces (and I feel that GPT o1-mini is better in AtCoder). Let me know if you want me to test a specific website.
Please try ARC instead, ABC is a meme and well known to have only standard problems
Some of my friends did try, it can solve some problems in range 500 — 1000 and fail some problems in that range too (infact it failed a 500 too). The rating refers to the kenkoo rating
My main takeaways :
1) it can solve standard problems. Not surprised, and somewhat even a good thing. Now contest authors can no longer put them on contests which is a plus
2) it can solve most d2AB level non standard problems. Slightly sad but maybe the meta can evolve.
3) ABC, Div3 and Div4 cant continue in the way they currently are without significantly disadvantaging the people who dont have access to o1 mini. Further, maybe some extra care is needed in selecting d2Bs
Multistep problems will always be an issue for it, and we should aim to have more such problems.
As for future improvements, it will definitely get somewhat better. But i dont think this particular type of AI can become a grandmaster lets say (not that no AI can reach, but this type of bruteforcing solutions cant). This is because of how the AI works.
I dont believe this type of "generating 1000 solutions and then trying to narrow down to 10 possibilities" will work for harder problems because they need multiple reasoning steps i.e. your probability of correctness exponentially decreases
Basically, we need to fully embrace antontrygubO_o meta :)
cant complain at all
"Multistep problems" "anton meta"
:thinking:
Been complaining for a while now, but can't wait for 1/2-shot math transform enthusiast to realize how boring their problems are when ai can branch the ~50 transforms two layers deep.
i made a blog, it fails my d2C, and my co-authors d2B :)
It also did terribly on ARCs and AGCs.
Just saw it, good blog showing real results (not surprised by openai overembellishing), but I think o1-ioi or maybe wait in the next year d2c will also be cooked. I'm confident these problems have low branching factors that a properly setup reinforcement model can learn. Only time will tell tho.
Agree problems are worst if essentially a lookup table, disagree on what constitutes a novel/high depth in steps thinking problem.
i think openai was true to their words actually
They claimed a 1600 model in their mini version, and it seems to be just shy in div2 contests (and we only attempted once due to limited queries, 50 per user monthly)
maybe, but the other type of problems get cooked faster....
Thanks for the test C0DET1GER! I suppose it would also be interesting to test it on live contests, to make sure that it is not a overfitting of existing data the model was trained on (but I find this unlikely).
Also, my hypothesis is that the model probably performs better in atcoder because the statements are more direct.
I’m curious to explore how much it can benefit even more advanced contestants. It could potentially help as a good way to search for classic subproblems or maybe help as an implementation assisntant.
One another thing, 2400 perf on ABC is never equivalent to CF 2526 perf even on modern div.2, since cf problem are far more ad-hoc than ABC, I think it's equivalent only if you test it on ARC/AGC.
I think model is trained over these problem as it's dataset, for problems that model hasn't seen yet the model may not perform well at least problem E and F level. But as a pupil I already lost a battle with a bot :(
For lots of problems for ABC, you can find almost the same one on the internet ,so it's not very meaningful to test it by ABC problems. You can try ARC or AGC
Anyone aware where to buy cows ? I am thinking to start a farm before the prices for cow skyrocket due to gpt making us redundant
This is crazy. Maybe the end of online competitive programming era.
Some users may argue this is not a big deal, using GO as example. In the Go game, the AI beat world rank 1 player Jie Ke very hard in 2017, does Go die? No, because in the real competition, players cannot use AI.
However, in codeforces, all players are competing online without monitoring, which means you don't know if he or she is cheating or use AI. Imagine you are an expert, in a div2 round, you solve 2A and 2B in 15 minutes. Then you discover that you have already rank 10000+, because many many newbies just copy the problem statement, paste to chatGPT and solved up to 2D, both 2C and 2D has 10000+ accepted users. How do you feel?
It just like you are top runners in Marathon race, many cheaters just ride the motorcycle to finish the race in 30 minutes, break the world record, and the committee just say their result is effective, you rank behind them.
I can solve the problems just for fun, but cheaters will not. And it is not fun if cheaters beat me every time I participate, and make my rating drop from master to newbie.
It's time for codeforces official to do something do handle this situation. I am serious.
While I agree with the general sentiment, isn't this similar to the situation with online strategy games like chess? Any player can quite easily cheat. All it takes is using a few engine moves when needed, looking at opening prep, or even just having access to the computer evaluation. You could even argue that as chess computers have gotten better, online cheating hasn't increased by all that much (I'm not sure if there are statistics that disprove this).
The main reason is that everyone knows you can cheat on chess.com or lichess. Your chess.com rating and your lichess rating hold very little value. There is not that much of an incentive to cheat because there isn't that much value to the rating itself.
With that being said, I just realized that there is a concrete difference between chess and CP. With chess, there are a lot of official FIDE tournaments where your rating actually matters. There isn't really an equivalent for CP. The only equivalents are in-person contests like ICPC and IOI which are pretty hard to go to or compete and are restricted to specific age brackets.
I totally agree with you with the last paragraph.
You know in leetcode contest, the cheating is much more severe. Because some of the recruiters in some country, they know leetcode, and if you get a high rank in leetcode, for example, guardian badge, you will be more likely to pass the resume screening. For chess, even if you get very high ranking, you will not get a job for it.
And the in-person contests for programming is very sparse, and there is no contest for people that are already at work. Nearly all contests are for high school (IOI) or undergraduate (ICPC), if you pass the era, you can only participate Meta Hacker Cup for fun. Really hope if there is in person contest available in the future, especially for all ages.
But is there are really some way to handle this situation? Any suggestions?
was going to say this — sadly there's no good solution IMO
Maybe if OpenAI will take the situation in their hands and, for example, will forbid to generate solutions for tasks from ongoing contests.
Ridiculous, lol
We are all humans after all, maybe they'll show a kind gesture
Okay, another suggestion: Ddosing OpenAI servers during contests.
Why are you targeting specifically OpenAI? Everyone will be able to have some open-source model on their laptops and run it locally.
Is this actually true? I thought OpenAI had the most advanced ones and as far as I can tell they are not open-source.
Will be in a couple of years.
This is a slippery slope. OpenAI doesn't care about the competitive programming community, but let's suppose they did.
If they gave Codeforces an exception then AtCoder, CodeChef, and LeetCode will also get ones otherwise it's just blatant favoritism.
What you end up with then is a chatbot that is almost never usable. OpenAI would never stand for that. The downtime ruining their hype train!
How is that never usable, imao? I'm talking only about problems from ongoing contests, they'll become available after the contest ends.
That's 2 hours gone for like 4 different platforms. That adds up and for ordinary users who don't care for competitive programming, it's unacceptable.
7 problems being unavailable for 2 hours? Yeah, that's truly unacceptable
Okay, I see your argument and it still doesn't work. It's so easy to circumvent that. You can query another AI to edit the problem statement then paste it in. How would you detect that?
If AI can understand statement, that won't work
But he's not talking about shutting the server down. It's just that, if the AI detects that the problem is from an ongoing contest, it won't answer by giving an excuse.
We need to storm OpenAI headquarters.
AI gaslighting has been a thing for years now and its basically impossible to entirely avoid.
Problem with current cheating is that it's done in closed channels, shared information is not public and it puts other participants at a disadvantage. LLMs are public and can be used by everyone as another tool just like IDE, plugins or prewritten algorithms, so it's fair.
If the model is public, what if authors run their problem ideas through GPT until they find ones it can’t solve? This may reduce the quantity of rounds, and slightly increase the average difficulty, but the integrity of contests would be preserved.
This will help in the current phase if the chatGPT still have limitations. That is , make sure chatGPT at least cannot solve this problem in the first few attempts and with guidance.
However, if the AI is as strong as tourist, this kind of problem will not exist, and if exists, this is a 3000+ problem.
I think a lot of problems in the world could be solved if we had an infinite amount of tourists. The death of CP would be a small price to pay.
Yes, just move on to another hobby if that day come. The life have more wonderful things to do.
To solve the problems of the world, what is required is not just the tremendous technical capacity, but much more of the integrity, compassion, and highly ethical behavior. Otherwise, infinite tourists can also work together to create atomic bombs, each country will have their own.
Why is this so hilarious hahahah
"don't be sad that it's over, be happy that it happened"
i'm also not sure what they mean by "simulation" of contest, did o1 participate in latest contests with unique problems?
did they make sure that codeforces problemset and solutions are not in the training data?
That's the real question did they have editorials as training set?
A point I noticed while reading the blog was that the claim that it is in the 93rd percentile is based on a cf blog(linked in the references) that is 5 years old now. I wonder would there be any changes considering the current rating distribution.
Yall gotta test it in next contest to see if 1600 is inflated/leaked test set or not since the 1600 elo version is available and we’re sure those problems won’t have been leaked to the training data.
Oh mother fu--
Well, it's personal now
rating of 800 for gpt4o (current version) seems quite accurate. if o1 will be accessible to public then I think it will fundamentally change competition under Div.1; if everyone use o1 then blue will be new gray.
I’m still skeptical. I will be a full believer if they can demonstrate it consistently performing at 1800 level in live contests.
Old problems existed in the internet for a long time as well as their solutions.
There is a very high chance GPT saw both the problem statements and their solutions during the training stage.
I doubt it would have the same kind of performance on a live contest with novel problems that are out of distribution.
Frick, I'm 2 points ahead of o1-ioi. Better step my game up.
Now I have to email organizers, correct?
The death knell for Codeforces has already sounded.
Are you competing in Meta Hacker Cup — AI Track $$$??$$$
bruh my rating barely higher than an AI skull
should test unseen problems and check the rating. Models train with whole internet data highly likely already seen those input problems.
low iq bros.. what is point of continuing cp? when ai achieve gold medal on IOI and literally anyone could reach 1800 with GPT?
hey, at least it is coming for the high IQers soon
The claims that they got way better results than alpha-code (54% vs 89%), a much more complex system, applying just a prompt technique requires further proof to be taken seriously.
It's pretty interesting that this report became public just a few days after it was proven false that some individuals made significant progress using a similar technique.
A video explaining the "advanced COT" controversy for all of you interested in this topic.
https://www.youtube.com/watch?v=Xtr_Ll_A9ms
With the increasing number of AI models, cheaters can easily achieve a 2000 rating or even more, making these models very useful for them, while those who work honestly won't be able to improve their ratings. Therefore, along with new AI models, we will need to update plagiarism detectors; otherwise, the future of competitive programming is not safe.
This is scary. Rating inflation will be insane
I call bs on this overhyped shit. Show me a real demo on live contests. Its just OpenAI Marketing (ironically not so open). Just a web scrapper basically, parsing the editorials like an idiot.
It is definitely overhyped, but I wouldn't be calling it a web scrapper either.
There is some merit to it.
Imagine if you compress and organise the problems in a nice coherent structure.
What that will allow you to do is to effectively query that database and find the answers faster than you would otherwise.
Basically, I would say that it is like a binary search in a sorted array, compared to a linear search in a randomised array.
Google already does it with their search engine, but I would argue GPT search is a one step further in terms of finding of what you need.
Roughly the difference is the same as between syntactic and semantic search.
In syntactic search you try to find a substring "search term" in the text of a webpage, but with a semantic search you would also consider the meaning of a "search term", not just a substring entry.
Google already does semantic search, but it is just an example to make a point.
If China hadn't gotten 1984'd at IOI, then Open AI would not get a gold medal. LOL
If I'm the interviewer, I will ask people in the most possibly serious way if they showed me their CF profile in the resume.
Its over for me
CF authority should just ban the cheaters accounts immediately after being detected.. at least this is the least they can do..
Is my English bad, or does this mean their model is just resubmitting code from other participants?
No, it means it generated a bajillion different codes by itself and then took the best 50, similar to what alphacode did.
Ah, candidate here refers to code it generated. Got it. Somehow my head interpreted that as IOI medal candidates for some reason. Thanks for the help.
By candidate submissions, it doesnt mean other participant's submissions, rather potential solutions generated by itself
the worst is that o10mini is gonna be public
As far as I know atcoder does not allow LLM solution and consider it cheating. I have never use gpt or anything in a contest . Can anyone tell me if it is ok to try those LLM for codeforces and meta hacker cup for solutin ideas ???
The golden age of competitive programming is coming to an end.
This is all leading up to a deep blue style challenge. Tourist vs AI one day in the future.
I played with ChatGPT o1-preview model for about a day and I was almost immediately disillusioned.
It is good with easy problems and struggles a lot starting with Div1A.
The model doesn't demonstrate a capability of "understanding", at least I didn't get that sense from it.
It still does rookie mistakes, creates unused variables, writes comments that don't match the code, etc.
Still far far away from "AI will take your job" =)
dont do that. dont give me hope.
Have you tried the o1-mini model? It seems to be much stronger at thinking than o1-preview.
Not yet.
I was assuming o1-preview is stronger.
Probably I am wrong.
Will try it out.
Thanks for suggestion!
lol dude u can't even solve div1 A in 2 hours, but somehow the fact that a preview model struggles with it given just a few minutes makes you think it's far from taking away your job. idk man even 3.5 demonstrates better "capability of understanding" than your cope
So, no more rated competition?
You are welcome
We had a good thing, you stupid piece of code! We had Codeforces, we had Atcoder, we had everything we needed, and it all ran like clockwork! You could have shut your mouth, helped up code, and made as much money as you ever needed! It was perfect! But no! You just had to blow it up! You, and your pride and your ego! You just had to be the man! If you'd done your job, known your place, we'd all be fine right now!
Did you make this using AI?
No lol, it's an original quote from breaking bad. I just replaced a few words.
nor please say this is untrue ;(
I was going to push for expert. So sad now it may not be as impressive
Everyone's saying that it's gonna be the end, but we have to ask ourselves: how many people are actually dishonest? In terms of cheating in online games, I'd say not many. For example, AI can crush the best people in chess, yet most players on chess.com and lichess are honest. Furthermore, if we somehow took competitive programming out of the job application process (aka made it completely pointless to show off "Master on codeforces" on your resume), there would be much less dishonesty.
Could hiding the verdict of the solution decrease the performance of the AI?
It uses the public and self generated testcases to train so that wouldn't matter in a contest.
From reading the short blog post, I assumed it is factoring in the verdict of the solution as part of the decision making process (as that would be the smart thing to do).
But I could be wrong and it could simply be results agnostic.
Even if that is the case its always possible to just generate your own test cases.
could have used millions of dollars to cure diseases, but no lets make it solve maths problems, super impactful
It is used to cure diseases...
You're ignoring the fact that whenever these satanists try to "cure" diseases, they end up killing millions of Africans and Indians.
Yeah, last time they tried to do something like that they stole 3 million Chinese kids and turned them into a ChatGPT.
lol
lol
Now I'm very curious about how AI is good at making a correct naive solution in just one try (naive solutions mean, for example, inefficient solutions like $$$O(N^2)$$$ time complexity in $$$N \leq 10^6$$$ constraints but it outputs correct answer in all testcases).
In fact, OpenAI made the following statement, and it means that AI improved its performance from the 49th-percentile to the 92nd-percentile in IOI just by increasing the number of allowed submissions from $$$50$$$ to $$$10 \ 000$$$.
However, if we already have a confident naive solution, we can use the random generating strategy for avoiding WAs — just compare the answer in small testcases and check whether it outputs correct answers like the following code.
In my experience, this strategy can find at least $$$1$$$ counter-example in $$$>95\%$$$ of WA solutions even with testing only $$$1 \ 000$$$ random testcases below $$$N \leq 10$$$, and testing should finish in $$$0.01\mathrm{sec}$$$ on average even if the naive solution is like $$$O(2^N)$$$. It is very realistic to test all $$$10 \ 000$$$ submissions x $$$6$$$ problems in $$$10$$$ hours of contest duration. (Note that since the compilation time is long in C++, which is the only allowed programming language in IOI, we should consider another strategy just for compilation though)
In addition, to avoid TLE, just testing the execution time in one random big testcase is enough for most of the problem, and we don't always need to test in max testcases. For example, even if the constraint is $$$N \leq 10^6$$$, testing in a $$$N = 10^4$$$ testcase should be enough for most cases, because generally, time complexity matters. For example, I think that distinguishing $$$O(N^2)$$$ solutions and $$$O(N \log N)$$$ solutions is possible in $$$N=10^4$$$ cases for $$$>80\%$$$ of the CP problems. Note that something like "it works well in $$$(N, M) = (10^4, 5 \times 10^3)$$$ testcases but works very bad in $$$(N, M) = (10^4, 1)$$$ testcases" can happen in some problems, but I think that this kind of case occurs in less than $$$20\%$$$ of the CP problems.
Therefore, now I am even starting to think about IOI-Gold AI is just around the corner, and the only remaining piece is making a confident naive solution (+ to solve some issues for a long compilation time). I really want to know how AI is good at such skills currently.
I agree with what you said. In fact, this description is very obvious. I think one could implement it in a script using the OpenAI API.
On the good side ai will be very effective in teaching us hard problems now
Everyone ready this comment you will definitely upvote it ! Codeforces should do partnership or deal with openAI.Before any contest begins , Codeforces will give all there questions in TEXT to those AI platform and ask them not to show or answer anything about that question while the CONTEST is running (Say 2-2.3 hours) After that you can do whatever you want chat gpt , io ,etc etc
It would be very helpful because then no one will be able to cheat during that CONTEST TIME...!
I think the way is useful. But Codeforces should partner or make deals with all companies like OpenAI, which is difficult.
How about the following benchmark to test "reasoning" ability: test these NNs only on problems that have a tricky case. Look for recent-ish (for as long as pretests have been strong) problems which have only a few FSTs, usually due to WA. This can miss some suitable problems but it's something. If it's not enough to use what usually works on such problems or filter out nonsense using correct outputs, failure specifically on such special hard tests would suggest a lack of reasoning ability.
Isnt simply testing the model against new problems (in a live contest) a better way to test for reasoning?
Consider that programming competition problems are quite repetitive. Not in the notorious coincidence sense, but how many times have you written DP on a tree using DFS? It's also why there's more of a push for adhoc in recent years, but making something actually creative (and solvable and not straightforward) is tough. It's not all that surprising that autocomplete is improving at "solving" them.
I'm basically describing a type of hard data mining. Finding the problems that quack like ducks and look like ducks but aren't ducks when you look really closely.
It'd also need to be done among problems with low enough difficulty level. If we give it problems that we a priori know are too hard to solve, we won't gain useful info. They shouldn't be hard in that sense, but in the sense of having a logically apparent catch.
Wow.
End of life....
Wtf AI has surpassed my intelligence along with 7 billion other humans on the face of the planet
I asked gpt 4o mini for counting the number of times the alphabet r appears in the phrase "strawberrystrawberry".
It answered 4.
You can use gpt-o1 to test it again.
We are cooked.
Human Fall Flat... I'm really close to be beated by a bot.
I can't believe waking up to discover that the time I spent for CP is meaningless now.
TBH if INF submissions is the only problem with these models achieving these crazy ratings in contest then we could just Have the Evaluation Simulated Locally. One solution would be to have another model finetuned on generating absolute brute and then Stress Testing the optimal against brute and giving it the TC it fails on. Can't wait for the AI to reach CM before I even cross 1500 ;(
So should we stop doing competitive programming now? As it feels very demotivating now
No more software employments?No coders needed anymore? Practicing CP is waste now? NO Jobs to coders? Is this the End? Confused whether to do CP or stop