


Hey Guys!
I'm the SRM 624's problem setter and I'm very glad to invite you all to participate. It's my first time as a topcoder problem setter, let's hope it's not the last :D
The contest is going to take part tomorrow (maybe today, it really depends on which part of the world you're right now): http://community.topcoder.com/tc?module=MatchDetails&rd=15857
Time and Date: http://www.timeanddate.com/worldclock/fixedtime.html?&day=12&month=06&year=2014&hour=11&min=00&sec=0&p1=179
Hope you guys have fun and enjoy it.
Wish you all good luck!
P.S: Let's discuss problems after the contest!
P.S2: Tomorrow is also the World Cup Opening, so we can discuss it here either! :D
**P.S3: Editorial (incomplete): http://apps.topcoder.com/forums/?module=Thread&threadID=821638&start=0&mc=1#1888704 **







First time to know the writer of problems before SRM , Usually s/he login as a writer and we ask who is the writer after the end of round :)
sometimes topcoder admins ask us Guess who is the writer
I notice you are brazilian :) so today your country host SRM and World Cup :)
GL & HF
Nice. I hope you had not discussed any problem with me? Because I want to participate
All problems are brand new, so you can participate.
I've heard that at topcoder it's strictly not recommended to announce your own authorship of the contest, that's why we usually don't know problemsetter until round ends. Won't they blame you in violating their rules?
Yes, I was told not to reveal the identity until the end of challenge phase in SRMs and TCO rounds. Does this changed now?
btw, It's interesting to see a writer from Brazil while the World Cup is there. I guess the tasks will contain something related to the World Cup. Let's see if I'm right after the contest.
No, this is not changed, but we haven't informed MDantas about that. This is noted, new problem writers will be better informed in future.
maybe like this problem? ;)
No problem about the world cup :(
Quiet, ongoing contest! :D
There's nothing on the TopCoder Writer Contract covering that possibility, at least I didn't see.
How to solve 1000(Div2)?
Contest has not ended yet! Wait a little bit.
Just calculate nim-value for all state's. Read about it here: http://en.wikipedia.org/wiki/Nim
I solved it the same way, but I think there's a simplier solution. If someone solved it simplier, please tell your solution.
ashka's solution:
How?! o.O
It was like CF div2 CDE.
Almost the same 1000: 342E - Xenia and Tree
Yes, and it seems that changing module by 2 also radically changes everything in 500:) http://community.topcoder.com/stat?c=problem_statement&pm=10805
Yet anyway, 1000 was hard enough only to be solved by the few, so I guess it is alright.
I'm sure most top contestants know exactly how to solve it (BIT over HLD), it just takes time.
Agreed. It was more of a coding then a thinking task — yet difficult enough.
My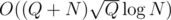 didn't fit in time just a little bit. It could be optimized to
didn't fit in time just a little bit. It could be optimized to 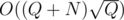 , but I didn't make it.
, but I didn't make it.
I guess your solution is something like: - when a new node is painted blue, add it to a list (if we now have sqrt(Q) nodes in the list then recompute values for the whole tree in O(N) time and clear the list) - for a query: take the answer from the last tree "rebuilding" and then traverse the list of nodes which were recently painted blue, compute the LCA to each of them and add the distance to the answer of the current query.
I implemented this approach but I was getting TLE on the example test cases 4 and 5 (and I only finalized it too close to the end of the coding phase to be able to optimize it in any way). After the coding phase and looking at tourist's solution (which is just what I described above), I realized that my TLE was coming from the recursive traversals of the tree : because of the way the parents were given, the nodes could be traversed simply in ascending/descending order (except for a initial DFS). After replacing the recursive traversals with simple "for" loops I got AC in the Practice room. Maybe the same thing happened to you? Or maybe you just used a value which was too large or too small for "sqrt(Q)"? I used 200 (and I saw in tourist's solution that he used 100).
I waited until now to write this because I was unable to submit my solution in the Practice room yesterday and also earlier today (whenever I tried to compile my solution, it said that the request timed out).
It can be solved in O(N * sqrt(N * log(N))) time, without any data structures.
How do you solve it without using LCA?
Even with LCA (sparse table) you can solve it with O(NsqrtN), just SQRT-decomposition.
Not sure I understand your comment. What does "Even with LCA" mean? My point was that LCA is a data structure.
Okay, I misunderstood you.
Every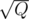 queries perform DFS on a full tree. Also we can build a tree "stretched" on the
queries perform DFS on a full tree. Also we can build a tree "stretched" on the 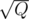 next vertices and find distances between every pair of them in O(Q).
next vertices and find distances between every pair of them in O(Q).
Nice usage of the fact that the problem is offline, thanks!
...which is just a disguised Aho-Hopcroft for processing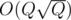 LCA queries. =)
LCA queries. =)
I know only Tarjan's algo for answering M offline LCA queries in O(N + M). Is there any other approach?
I believe that's the same approach. Quite a lot of different names are used for it.
Rubanenko, you forgot about the inverse Ackermann's function.
Do you remember that DSU has actually unproven complexity? There was an error in original proof.
See http://codeforces.me/blog/entry/2381
Who ever cares about Ackermann's inverse? :)
'Actually'? There is just a list of another articles that assumes original paper contained some mistakes. And some of these articles were wrong by themselves. So, I'd better not claim that the original complexity is 'unproven' or 'wrong'.
In any case, there is a rather simple iterative logarithm upper bound, which is missing too.
Oh, well, without advanced data structures :)
Here is my solution. Answer to each query of type 2 is: depth[v] * number_of_blue_vertexes + sum_of_depths_of_blue_vertexes — 2 * sum_of_all_lca_from_v.
Let's calc last sum. Denote v = p0, p1, p2 ... root = Pk the path from v to root. So for every pi we should add depth[pi] * (cnt[pi]-cnt[p_i+1]) to the sum. But depth[pi]=w_pi+w_p_i-1+...+w_p1. If we disclose brackets, regroup elements and simplify the expression, we get: sum = sum by all i from 1 to k of weight of edge from pi to its parent * cnt of blue elements in subtree of pi.
So solution is this:
1 type of query. inc all vertexes from v to root by 1.
2 type. Calc the sum from v to root weighted with weight,of edges to parent.
We can do that in n log^2n time with hld, or in n logn time with linkcut tree.
It can be solved in O(N * log(N)) without any data structures using divide-and-conquer on a tree, provided that you sort numbers between 1 and N in O(N)
The intended solution (in fact my solution) was O(N log N): - First pre-process the tree and divide it in its centers. - For each query of type update, traverse centers until you reach a center equals to query's node, just update its value and recursively update it's predecessors. - For each query of type get, traverse centers suming up for each subtree that doesn't contain the query's node its pre-calculated value, recursively go down until you reach the correct node and just return the result.
As ivan came up with a different and very nice solution O(N sqrt N) we decided to let both of them get accepted.
I send NlogN using Link-Cut tree. But I don't think problem, which alows to solve quite easy, it you have prewritten structure is good.
<troll mode>
If it allowed "quite easy" solution with pre-written structure, your score for this problem would be 700+ :)
</troll mode>
But with TC, 700+ means instant solution; it could've been easy as in the rest of the solution is easy to think up, but still takes a while to write.
Countertroll!
Look at PavelKunyavskiy solution, the amount of code not related to link-cut-tree implementation is very small. And one must spend more than 20 minutes on problem to get 700 points for 1000-ptr.
Actually, I also have a pre-written implementation of link-cut-tree, but I decided that I'll spend much more time on modifying it and debugging the solution than on coming up with some simpler idea.
20 minutes isn't much...
Sure, why not. As I said: countertroll — not a very serious response to another not very serious post :D
Today a new restrictions come:
n <= 4000, n <= 2000Max tests have given three successful challenges to me :)
Modulo on my template
Modulo on the main code (the correct one)
Modulo on calculation
gonna remove modulo from my template :( and perhaps my shift key from my keyboard...
Good luck with
:P
Me too. That was not fun!
precisely the reason why i removed
#define MOD 1000000007from my template! :D450pt of Petr also get successful challenge due to the same problem
The pretests was very very weak :(
P/s: Can anyone tell me how to enter a 2000-element vector to challenge?
Input "1,2,3,4,5,..." in the text field and press "++"
There's "++": "enter comma delimited array". You can make one with 2000 elements by making one with 2 elements, and (copy-pasting 9x) 3x. This is what I found out today :D
{1,2,3,4,.....,4000}
then press {}
LINK
{1,2,3,4,5,...,4000}and press{}What is stack size for GCC on TopCoder? I think that I've got stack overflow in my 1000 on the server, is that possible?
I think the stack size is standard (2-4 MB), unlike Codeforces.
Seems that the stack limit recently dropped. When memory limit was 64 mebibytes, stack limit for C++ was about the same. Now, it is more like 8 mebibytes, don't know exactly.
I also have this feeling about my 1000.
Just when my rating is 2182 and I expect to be red tonight, I got MOD problem :'(((((
Sorry for that, we didn't even noticed that sample cases were not covering MOD overflow.
Apology accepted. But still you owe me huge amount of rating.... :'(
looks like i will go down from yellow to blue today.
maybe this is a sign that i should stop supporting Brazil and support Italy or France for the World Cup! :P
You are Juan Mata, you should support Spain then :P
(for non-football fan : Juan Mata is a spanish football player)
unfortunately though, i don't think Mata will start tomorrow's match against Holland :(
I want to support Germany (white), so I should register a new account and make it unrated :(
P/s: All TC admins support Netherlands :))
System testing is so slow =(
N<=4000, n<=2000, n<=100000.
not even 50% finished :'(
Yeah, seems like we're up for a 2-hour systest...
I wonder why they don't show current standings? Some time ago we could see live systests, didn't we?
Nope, the results are always being opened room by room after system testing is over.
Thanks) Seems I thought this room by room showing is systest itself >.<
perhaps the server is too busy preparing for the World Cup :D
Wanted to ask — why problemsetters in Topcoder use "generating functions" for inputs? I can understand that happening in Codeforces (where reading from file can cost too much in some languages) or in GCJ, where time required to download inputs is deducted from total time given for one attempt.
I am not so sure about SRMs. Parameters are passed to the function. If you pass then by reference, there is no time overhead. I think all languages at Topcoder can do passing by reference (at least I am sure about C++ and Python, should be the same for Java). Also you had this statement saying that "the way it was generated doesn't have any relation to the way it should be solved", which presumes that it was just a technical step.
So what prevents from passing input as it is, without those generating functions?
TopCoder's system. If you have an input of length more than ~2000, it crashes for some reason.
Thanks!
Maybe some kind of limitation on how much database memory you can spend for holding testcases for specific problem. I forgot that they also have to keep all testcases indefinitely (potentially), so they probably don't want to have hundreds of 50Mb testcases for each problem.
UPDATE1: On another thought — Topcoder could keep this "generating function" in database and create input whenever it is needed for testing, so this is non-issue. The only issue is that it is not supported by current platform. But I think it is definitely good feature request.
UPDATE2: Generally I can see pattern
posts with bad ideas get lots of minuses and
posts about somebody's struggles with problems if they don't end up in good question or in good answer get lots of minuses. There is exemption for red rated though.
But I don't understand minuses for this question — whoever wants to put another minus please tell why do you think that this is bad idea.
One of the main reasons I learned when I was writing Div1-Hard is that if TopCoder allowed huge inputs, it would not be possible for someone to challenge as it's not that easy and fast to just copy and paste a huge data. If topcoder had some way to send a file or even a generator, then it would be fine to have problems with huge input.
Another reason is that topcoder problem setter plataform really crashes with huge inputs or outputs, that's the reason we just asked for you to return the bitwise XOR sum of all answers instead of just returning an array.
I don't know whether this is true or not, but someone said that TopCoder is building a new web plataform similar to Codeforces.