


Всем привет!
Итак, четыре квалификации позади и приближается основное событие отборочного цикла Russian Code Cup 2014 — отборочный раунд. 802 участника сразятся за право войти в 50 лучших, которые будут приглашены в Москву в начале октября для участия в финальном раунде RCC-2014.
Отборочный раунд начнется в 14-00 по московскому времени в воскресенье, 8 июня, и продлится 3 часа.
Раунд завершен, поздравляем финалистов!






Не торопите события, перед ним ещё Yandex.Algorithm round 2 и TCO Algorithm Round 2B...
Да, выходные обещают быть насыщенными. Удачи на всех раундах!
Elimination Round ведь просто так написано? Почему-то под этим названием я представляю себе исключение (elimination) последних в табличке участников каждые x минут, на харьковских сборах такое было)
Раз в 3 часа вылетает 752 человека
В блоке справа две ссылки с названием "Разбор задач Квалификации 3", причем должна вести на 4-й, но ссылка битая(пропущено
/blog)Мхк поймёт)
И сразу вопрос: верно ли, что в случае отказов на финал будут приглашены следующие участники?
В прошлые года так было, по табличкам получается так (год: последнее прошедшее место в итоге):
2013: 51
2012: 57
2011: 50
В 2011 году на самом деле последнее прошедшее место было 53, там какой-то баг в таблице.
Как решать Е?
Построим неориентированный граф с рёбрами двух типов: для ребра первого типа нужно не менять ни одного его конца или поменять оба конца, для ребра второго типа нужно поменять ровно один из его концов. Покрасим граф в 2 цвета так, чтобы количество вершин одного из цветов было минимальным.
Я преобразовал граф, добавив фиктивные вершины, а дальше взял чёрно-белую раскраску.
Преобразовывал по следующему принципу:
Если ребро (X,Y) в любом случае удовлетворяет условию, в граф его не добавлял.
Если для ребра (X,Y) нужен "разворот" какой-то одной из вершин, добавляю его в граф. Соответственно потом будет покрашена ровно одна из этих двух вершин.
Если для ребра (X,У) необходимо вершины не трогать, либо повернуть обе, то брал новые две вершины A и B, добавлял рёбра (X,B), (Y,B), (A,B) и отнимал от ответа 1. Соответственно потом надо будет покрасить либо одну вершину (B), либо три(A,X,Y), что даёт +0 и +2 к ответу соответственно.
Можно ли решать C лучше, чем за квадрат с битмасками? И в чем прикол теста 9?
Там решение за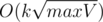 вроде как. У меня по крайней мере зашло оно. maxV — максимальный объем холодных или горячих сосудов.
вроде как. У меня по крайней мере зашло оно. maxV — максимальный объем холодных или горячих сосудов.
long longУ меня был квадрат с запоминанием ответов.
Без битмасок квадрат с предподсчетом для маленьких чиселок таки затолкался. А как там с помощью битмасок оптимизить?
Можете посмотреть на мой индусский быдлокод, получающий АС в дорешке.
C можно решать с битмасками, но за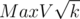 , если запоминать ответы и делать битмаски нужной длины.
, если запоминать ответы и делать битмаски нужной длины.
Кто-нибудь может чуть детальнее разъяснить эту идею?
Если отношение размеров сосудов равно несократимой дроби , то можно найти ответ за
, то можно найти ответ за 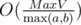 . Всего таких различных пар a и b, что max(a, b) = x, существует 2x - 1, и не все они соответствуют несократимым дробям. Худший тест — когда все пары a и b различны, причём с минимальными возможными max(a, b), тогда ответ будет
. Всего таких различных пар a и b, что max(a, b) = x, существует 2x - 1, и не все они соответствуют несократимым дробям. Худший тест — когда все пары a и b различны, причём с минимальными возможными max(a, b), тогда ответ будет 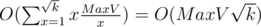 .
.
Можно за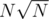 , где под N я подразумеваю максимум из всех чисел, которые даны в инпуте.
, где под N я подразумеваю максимум из всех чисел, которые даны в инпуте.
Пусть нам поступил запрос X / Y, тогда, пусть для него подходят колбы с объемами ci и hj. Если переписать немного условие равенства получившейся температуры, то получится такое: ci / hj = (X - HY) / (YC - X). Возьмем дробь из правой части, сократим на НОД и проверим, что числитель и знаменатель не превосходят 10^5. Теперь нам нужно проверить, существует ли пара (ci, hj), у которой такое отношение. Для этого переберем число, на которое мы домножим и числитель, и знаменатель сокращенной дроби из правой части, и для каждой из получившихся дробей проверим, существуют ли соответствующие ci и hj (на этот раз ci равно числителю, а hj знаменателю). Еще, если сокращенная дробь из правой части уже встречалась, то нужно сразу вывести ответ, не перебирая ничего.
Почему это работает быстро? Если числитель или знаменатель сокращенной дроби превосходит , то мы переберем не более
, то мы переберем не более  чисел для домножения. Если же они оба меньше
чисел для домножения. Если же они оба меньше  , то здесь вступает в силу запоминание. Если расписать суммарное кол-во операций, то оно тоже будет
, то здесь вступает в силу запоминание. Если расписать суммарное кол-во операций, то оно тоже будет 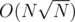 .
.
А это как проверить? За O(N)?
В одном булевском массиве отметим отдельно все ci, в другом — hj. И потом проверяем за O(1).
да, спасибо
Но разве таких запросов в худшем случае может быть не N ?
От каждого можно либо за O(1) до другого запомненного состояния, либо за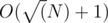 подсчитать ответ.
подсчитать ответ.
Ок, посчитаем отдельно кол-во операций для запросов где X ≤ Y (здесь X и Y это уже преобразованные и сокращенные числитель и знаменатель из правой части). Итак, у нас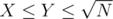 , тогда для каждого запроса (X, Y) мы сделаем N / Y домножений, причем всего запросов с таким Y может быть не более Y (X = 1, 2, ..., Y). Просуммируем по всем Y от 1 до
, тогда для каждого запроса (X, Y) мы сделаем N / Y домножений, причем всего запросов с таким Y может быть не более Y (X = 1, 2, ..., Y). Просуммируем по всем Y от 1 до  и получим
и получим 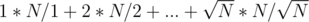 =
= 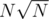 .
.
Даблпост
В С похоже слабые тесты, зашло следующее:
Найдем первые 2000 решений (x, y) диофантового уравнения, которое напрямую вытекает из условия:
x*(P — q*C) = y*(q*H — p)
и проверим, что есть холодный сосуд размера x, и горячий размера y.
Спасибо за интересные задачи.
Похвастаюсь, как я забыл сделать перевод строки в пятой задаче и этих двадцати минут штрафа мне не хватило на 50-е место :)
Задача D является частным случаем вот этой задачи. Забавно, что я ее предлагал на HackerRank всего три месяца назад :)
А еще она есть тут: http://oeis.org/A000111
D можно было посчитать в лоб для N <= 10, загуглить полученную последовательность и вот вам формула
я во время контеста эту формулу нашел, но сдать не смог. там проблемы из-за модудя вроде как.
я смог, проблем нет, могу помочь.
спасибо, но досдал сам. Надо было додуматься нормально делить на 2 (с обратным по модулю)
в Б может ли ответ образовывать лес? содержать изолированные вершины?
На оба вопроса ответ "да".
Может и то и то. Насчет второго — мне из условия было не очень очевидно. Казалось, что каждый из людей должен принадлежать хотя бы одному из множеств: матерям или дочерям. У меня стояло в решении условие
if (n - a > b) impossible();. В конце убрал — и зашло.Та же фигня.
значит можно было просто сделать одно дерево с a родителями и b дочерьми, а остальные вершины сделать изолированными?
Да. Я так собственно и делал: первых A назначил родителями, а затем последовательно раздавал дочерей начиная с A + 1 и далее B штук (по модулю N).
честно говоря когда я больше часа не понимал почему у меня WA, а потом оказалось что некоторые женщины могут быть и не дочерьми и не матерями (а кем интересно), я громко ругался, плевался и пинался и было желание тому кто условие составлял руки оторвать.
Бездетными сиротами?
мне кажется что раз это не было прописано в условии, то хотя бы сампл на это надо было дать. Мне кажется это проблема понимания условия, а не придумывания задачи
В условии всё было:
Гоша хочет научиться быстро строить пример племени, в котором всего n женщин, причем среди них a женщин являются матерью кого-то в этом племени, и b женщин являются дочерью кого-то в этом племени.
Я вспомнил одну задачу с по-настоящему мерзким упущением в условии, после получения WA из-за оного у меня тоже возникло желание оторвать руки автору. Вот, кстати, дискуссия по поводу той задачи.
И тут я обратил внимание на то, что автор-то у обеих задач один и тот же — Aksenov239 (только я не уверен, что именно он писал условие для B со вчерашнего раунда).
Теперь по теме. Я полностью согласен с Вами, что было бы неплохо, если бы случай с "бездетными сиротами" добавили в сэмпл.
Но все-таки ИМХО Вам стоит поучиться на своей ошибке и не выдумывать в следующий раз факты, которых в условии нет.
Зачем oeis давать на такой важный раунд?
Скажите, F нужно было решать быстрее N^2? а зачем TL 15 секунд?
Кстати, после раунда есть возможность читать код других участников?
Я придумал решение за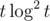 с FFT.
с FFT.
Я додумался до метода отражений и свёл к случаю x1=x2, y1=y2, а как дальше?
Я придумал как за O(logT) FFT свести задачу к такой: дано число M, посчитать количество последовательностей из 1 и -1 таких, что сумма всех чисел в последовательности равна 0, а наименьший баланс не меньше M. А как дальше решать не придумал. Там на OEIS есть производящие функции при M ≤ 3, а дальше нужно, видимо, как-то их обобщить. Или у тебя такой подзадачи нет в решении?
Это тут самоё лёгкое — метод отражений, он используется для подсчёта скобочных последовательностей с ограничением на баланс. Каждая последовательность идущая из x1 в x2 и пересекающая 0 соответствует какой--то последовательности идущей из x1 в -x2 (просто отразить часть пути после нуля)
Просто там ещё проблема что робот не должен проходить по (x2, y2) до времени t, как ты с этим справился?
Например, можно так. Найдем отдельно по X и по Y ответ для всех длин путей без учета того, что мы не можем заходить в (x2, y2) до момента времени t. Дальше, найдем для всех N количество путей длины N из (x1, y1) в (x2, y2) без учета этого ограничения по формуле: f(N) = X(0) * Y(N) * C(N, 0) + X(1) * Y(N - 1) * C(N, 1)} + .... Такую свертку можно посчитать при помощи FFT. Ну а дальше, количество интересующих нас путей g(N) равно f(N) - g(1) - g(2) - ...g(N - 1).
f(N) - g(1) * u(N - 1) - g(2) * u(N - 2) - ... где u(N) это сколько путей саму в себя.
Вот эта формула у меня считается за квадрат :(
Идея моего решения:
Заметим, что если убрать условие, что робот не заходит на конечную клетку раньше времени, то задача решается за O(1) (после предподсчёта факториалов). Чтобы учесть это условие, будем исключать нарушающие пути. Для этого решим задачу для всех меньших t. Теперь ответ в t2 получается как ответ без учёта условия минус линейная комбинация предыдущих ответов, причём коэффициент для ответа в t1 будет равен количеству путей из (x2, y2) в (x2, y2) за время t2 - t1 (причём путь может заходить в (x2, y2) в середине). Заметим, что коэффициент зависит только от разности t2 и t1, что позволяет считать эти комбинации пачками с помощью FFT.
double post
Как расчитать все коэфициенты для различных dt за O(t * log2(t)) ?
И это будет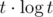 , а не
, а не 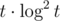 .
.
Потому что fft размеров 1, 2, 4, 8, ..., t.
Фактически тебе надо поделить ряд на ряд.
Проблема в том, что ряд решений не известен заранее, поэтому приходится разбивать его на куски размером в степень двойки и считать FFT от них. По мере появления новых решений нужно пересчитывать FFT от больших кусков. Тогда каждой решение побывает в FFT размера 1, 2, 4 и т. д. и в сумме даст вклад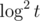 .
.
Видимо у нас разное решение.
Пусть F(x1,y1, x2,y2, t) — количество путей из (x1, y1) в (x2, y2) в первом квадранте за t ходов. Это считается за 1 (где-то выше обсуждали вроде).
Тогда чтобы получить производящую функцию ответа надо поделить производящую функцию F(x1, y1, x2, y2, t) на производящую функцию F(x2, y2, x2, y2, t).
Делить = обратить + умножить.
Осталось научиться обращать за nlogn.
Как это делать. Берем B0 = 1 Итерируем формулу Bk = 2 * Bk - 1 - Bk - 12 * A. logn раз. При этом от Bk нужно 2k членов, поэтому A можно обрезать по такой длине. И нужные FFT будут работать за длину Bk на лог. Сумма длин B_k это O(n).
Почему бы просто поточечно не поделить одну функцию на другую после FFT?
Он будет обратным по модулю x^(2^n)-1, а не обратным в смысле рядов.
Возьмем два ряда a, b. c = FFT^-1(FFT(a)/FFT(b)) (/ — поточечное деление) Тогда c*b=FFT^-1(FFT(c)*FFT(b))=a. Значит c = a/b в смысле рядов, разве нет?
С чего бы? FFT в данном случае является изоморфизмом (с точностью до мелких оговорок) между пространством многочленов по модулю x^(2^n)-1 с коэффициентами из Z[p] и пространством последовательностей остатков Z[p] длины 2^n. Стало быть и равенство с=a/b выполняется лишь над указанным пространством многочленов. Ну и как минимум заставляет задуматься то, что в общем случае c — ряд бесконечный, и нет никаких очевидных причин почему его такое хитрое обрезание при помощи FFT должно давать именно префикс c, а не что-то более запутанное.
Да, действительно.
Потому что может случайно не поделиться на ноль?
Вероятно можно и за O(n log n). Обратную последовательность можно считать за одно fft поэлементным обращением.
Удачи обращать 1 + x. У него fft содержит (2, 0).
Проблема. С другой стороны, шансы для случайного ряда быть "плохим" не очень велики, < 1/1000 в нашем случае.
UPD. А еще можно в конец ряда приписать несколько рандомных чисел, если не повезло.
Просто нужно держать обещания :)
(10^5)^2 / 32, java, опасность.
В прошлом году такая же ситуация была: http://codeforces.me/blog/entry/7964#comment-137253
Возможное решение для авторов тестирующих систем.
Кстати, гениальная мысль. Сделаю так в ближайшее время, спасибо за идею, Егор!
В Тренировках: 2014 Russian Code Cup, отборочный раунд.
По названию задачи D <<Конструктор пил>> сначала подумал, что будет психоделичное условие про конструктора-алкоголика.
А RainbowDash (127-ое) опять не прошёл :(
Я один не понимаю, почему это должно быть кому-то интересно?
А где-нибудь на сайте соревнования указана конфигурация тестирующих машин? Во время раунда я столкнулся со странным поведением системы: локально (на слабеньком нетбуке) решение по D работало 0.2 секунды, а в системе — ТЛ. В итоге зашло после переписывания Cnk на предпросчёт в гигантском массиве int'ов вместо умножений факториалов-лонгов (при этом локальное время выполнения от этого выросло в 2 раза). Неужели там 32-битные машины? Или может 32-битная java?
Вообще я может страшный секрет открою, но вроде везде кроме Я.Алгоритма и ejudge только 32битные версии
Это печально
Вообще, если отвлечься от качества задач, качество проблемсета, на мой взгляд, оставляет желать много лучшего для такого раунда. Когда надо выделить 50 лучших, по-моему, надо стремиться к тому, чтобы основная масса прошедших опережала основную массу непрошедших на задачу. А то вот я решил 5 задач примерно за два часа, сделав несколько штрафных попыток. То же сделали многие люди вокруг меня в таблице. И то же сделали многие люди на местах в районе 40. Я, конечно, понимаю, что штрафное время так или иначе всегда будет играть свою роль. Но здесь 100 человек сдали один и тот же набор задач, и вероятность не пройти из-за того, что сделал пару дурацких багов и по 10 минут их искал, была высока, как никогда.
Впрочем, если организаторы хотели пригласить на финал 50 рандомных участников из 100 сильнейших русскоговорящих спортивных программистов, то да, всё сделано правильно.
Ну рандом-то взвешенный, для сильнейших участников вроде Гены и Пети это не проблема (они не делают багов в тупых задачах). Для более слабых участников вроде вас со мной, которые могут набагать в тривиальной задаче, но могут и решить что-то сложное, — да, рандом. Но согласитесь, на онсайте всех порвать у вас со мной шансов не очень много ;)
Так-то оно так, но для меня ценно само по себе попадание на онсайт =(
Надо было тогда Kotlin Challenge писать)
Было уже.