


Recently Polygon got enhanced with AI-based features and this is great. Those features can be very helpful at certain situations, but if you don't need them you can just ignore them.
But few days ago I've first encountered a new block on the right panel:

and this one gave me more anxiety than usual. Why this one invites me to review something that I've never requested from AI? Why this one has a separate block and a bold label that suggests some tips as if it is some kind of advertisement?
The review link contains useSuggestGrammaticalStatementFixesCache=true, so correction tips are actually grammatical fixes. This block seems to immediately appear on problems that have newly created statements and on problems that were not visited for years alike. Also grammatical fixes that are provided by this block and by Suggest grammatical fixes seem to be identical.
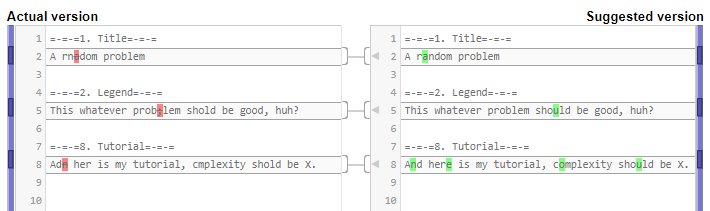
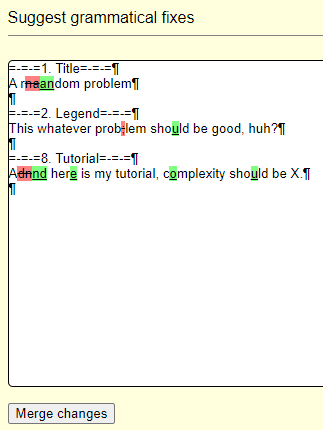
This grammatical fixes cache seems to be updated with every statement/tutorial update. I was not able to find a way to disable this behaviour.
How do I disable this behavoir? Why this feature is enabled by default? Why this feature has to have a cache in the first place?
I expect that CodeForces does not run own AI service and uses an external one.
Then there are multiple reasons why I would prefer to disable it:
- Querying AI service is usually more expensive than running some server-side script. So why should I waste someone's API quota on some intermediate or insignificant versions of my texts that will not be used and I do not care about fixes for it?
- Recently I've noticed occasions of significant delays in saving problem statement/tutorial. When it happens statement form is locked with
Saving...label for more than $$$30$$$ seconds. But if you decide to interrupt this process and reload the page it will still save the statement. I have no idea whether this issue is connected to querying AI services, but if it will be possible to fix it by opting out of AI assistance I would be glad to do it. - Most importantly: data security. Some authors (including me) can have prepared and partially prepared problems in Polygon waiting to be revealed in the first time untouched for a few years. How can I be sure that prompts that contain unrevealed problem statement and tutorial are not saved on the other side of the AI service and will not be used as a part of a future learning dataset? I do not want to eventially find out that some AI knows about my problem in exact original wording that is directly tied to problem tutorial in it's learning dataset.
Please, correct me if I'm wrong and give some comments, Polygon developers and MikeMirzayanov







Hi! Wow, you're fast :) Yes, there was a feature in development for disabling, and it's now available. But I don't think your doubts are justified:
UPD: Read my post, pls: https://codeforces.me/blog/entry/124528
This post answered all my questions.
Yes, technically any information exposed to any other service that you do not have full control of cannot be considered 100% secret and I provided exaggerated worst-case example. Mainly I wanted to conservatively trust less services and minimize chances this information can get publicly indexed in any way (by human mistake, by hack, by scam or purposefully misleading design etc.). However I still think that search engines are a bit more straightforward as they have to provide a source of information (in that case they will have to publicly point to someone's search history or similar) while LLMs are more shady as they do not explain how and based on what the answer was generated.
Anyway, ability for users to opt-out and take their own decision on this is more than enough, thank you.