


Both segment trees and dynamic programming are common topics in competitive programming. Sometimes, they even appear together. In this blog, we will mostly use segment trees as a black-box. As such, it is not necessary (though it is highly recommended) to know segment trees to understand this blog. Let's begin.
Longest Increasing Subsequence(LIS)
"You are given an array $$$v$$$ containing $$$N$$$ integers. Your task is to determine the longest increasing subsequence in the array, i.e., the longest subsequence where every element is larger than the previous one.
A subsequence is a sequence that can be derived from the array by deleting some elements without changing the order of the remaining elements."
This problem is most often solved using binary search. There are countless tutorials about this method, so I will not discuss it in detail. However, there exists a more general way to solve it using segment trees.
Since we only care about the order of the elements and not about the actual values we can normalize our array. By normalizing, I mean to transform an array while maintaining the comparison order of the elements. For example, $$$ [10, 23, 6, 23] $$$ can be normalized to $$$ [2, 3, 1, 3] $$$ . After normalization, all the elements will be in the range $$$[1, N]$$$. For more details about normalization check the sample code available at the end of this section.
Let $$$v_i$$$ be the $$$i$$$-th element of the array. We can start with a $$$O(N^2)$$$ simple solution using dynamic programming. Let $$$dp(i, j)$$$ be the length of the longest increasing subsequence consisting only of the first $$$i$$$ elements of the array and ending with the value $$$j$$$. The recurrence relation of $$$dp(i, j)$$$ has the following $$$2$$$ cases:
- If $$$v_i = j$$$, then that means that we can try to add $$$v_i$$$ to our LIS. Thus, $$$dp(i, v_i) = max_{h < v_i}dp(i - 1, h) + 1$$$ .
- Otherwise, our solution doesn't change by adding $$$v_i$$$ to the set of available elements, so $$$dp(i, j) = dp(i - 1, j)$$$ .
One way to implement this solution is to maintain a matrix $$$dp(i, j)$$$ and process it line by line, column by column. It would be highly inefficient to keep the whole matrix in memory at all times. Since the $$$i$$$-th line of the matrix depends only on the $$$i - 1$$$-th line of the matrix, let's try keeping in memory only the previous line and the current line. Note that this is a common trick to reduce memory usage in dynamic programming problems.
The final observation is that the line $$$i$$$ is extremely similar to line $$$i - 1$$$. In fact, they differ in at most one position. That position is $$$dp(i, v_i)$$$. It would be a shame to copy the whole line just to change one number in it, so let's keep in memory only one line and modify it accordingly. According to our recurrence, the value of $$$dp(i, v_i)$$$ is equal to one plus the maximum on the prefix $$$[1, v_i - 1]$$$. For an example of how those values change consider the array $$$v = [5, 2, 3, 2, 4, 1, 7, 6]$$$ and check out the following animation (Yellow means query on prefix, red means update on position):

So, let's review, we need a data structure that allows us to both query the maximum on a prefix and update a value at a certain position. A simple segment tree is perfect for this job.
Here is the problem link and here is a sample submission.
LIS generalizations
The main advantage of using the segment tree solution over the binary search one is that it can easily be generalized to deal with more complex LIS generalizations. For example, we can also easily count the number of LIS-es. Note that sometimes more than one segment tree may be necessary:
"For a given sequence with $$$N$$$ different elements find the number of increasing subsequences with $$$K$$$ elements."
A straight-forward solution using dynamic programming would be to define $$$dp(i, j, h)$$$ as the number of increasing subsequences consisting only of the first $$$i$$$ elements of the sequence, having $$$j$$$ elements and ending with $$$h$$$. The recurrence can be split into the following $$$2$$$ cases:
- We can try adding $$$v_i$$$ to the sequence, $$$dp(i, j, v_i) = dp(i - 1, j, v_i) + \sum^{v_i - 1}_{h = 1}{ dp(i - 1, j - 1, h)} $$$
- Otherwise we can't really do anything with the current element, so $$$dp(i, j, h) = dp(i - 1, j, h)$$$ for all $$$h$$$ different from $$$v_i$$$
Once again, we could maintain a tridimensional-array, however that would be highly inefficient. We can observe that the elements with the first dimension $$$i$$$ depend only on elements with the first dimension $$$i - 1$$$. As before, we can reduce memory usage by maintaining only one matrix. We can also observe that since most of the time $$$dp(i, j, h)$$$ is equal to $$$dp(i -1, j, h)$$$, the elements in the matrix rarely change. Since the necessary operations are finding the sum on the prefix of a line and updating an arbitrary value in the matrix, we can maintain it using an array of segment trees. This allows us to solve the above problem in $$$O(NKlogN)$$$ time complexity and with $$$O(NK)$$$ memory.
This problem actually appeared in the past here on codeforces. Also, here is a sample submission.
More complex problems
Let's apply our new technique on some more complex problems. For example check out the following problem:
"You are given an array with $$$N$$$ white cells. You can pay $$$K$$$ coins to change the color of one cell. You can do this operation multiple times, however you must pay $$$K$$$ coins for each operation. At the end, you receive money based on $$$Q$$$ intervals. For each interval, you receive one coin for each distinct color present in it. (White counts as a color too).
You have to maximize the number of coins gained. "
A simple observation is that it does not make sense to paint over the same cell multiple times. Also, we will never reuse a color. After making these observations we can try to compute for each position its profit if we paint over it. We define the profit of a position as the number of intervals in which it is included minus $$$K$$$. A simple greedy would be to paint over all positions with positive profit.
However this strategy has a simple flaw. Since white is also considered a color, we can get an additional coin for each interval with at least one unpainted cell. Thus, sometimes it may not be optimal to paint a cell with a positive profit since it may already generate profit even as a white cell.
Let's adapt our problem statement to match our observations made so far:
"You are given an array with $$$N$$$ cells. Each cell has an associated profit $$$p_i$$$ if selected. There are also $$$Q$$$ intervals that reward us with $$$1$$$ coin if they have at least one unselected cell. Compute the maximal profit."
Now, the problem seems much easier to approach using dynamic programming. Let $$$dp(i, j)$$$ be the maximum profit if we consider only the prefix $$$[1, i]$$$ of the array and $$$j$$$ is the last not selected cell. Note that only intervals that are completely inside this prefix contribute to the profit. Instead of generating profit when selecting a cell, let's select all positions by default and pay $$$p_i$$$ when we decide to not select the $$$i$$$-th cell.
Let $$$f(i, j)$$$ be the number of intervals which end in $$$i$$$ and contain $$$j$$$. As earlier, the recurrence of $$$dp(i, j)$$$ can be split into the following $$$2$$$ cases:
We decide to not select the $$$i$$$-th position: $$$dp(i, i) = \max_{j < i} dp(i - 1, j) + f(i, i) - p_i $$$.
We decide to select the $$$i$$$-th position: $$$dp(i, j) = dp(i - 1, j) + f(i, j)$$$.
One can , once again, observe that the elements on the line $$$i$$$ depend only on line $$$i - 1$$$, so we could only use one line and modify it accordingly. However, one thing is different from the last time we did this. The lines can differ in multiple positions, they can even differ completely. Does this mean that it is impossible to further optimize this solution? The answer is no.
For now, let's ignore the existence of $$$f(i, j)$$$ when doing transitions:
We decide to not select the $$$i$$$-th position: $$$dp(i, i) = \max_{j < i} dp(i - 1, j) - p_i $$$.
We decide to select the $$$i$$$-th position: $$$dp(i, j) = dp(i - 1, j) $$$.
Now, this looks certainly more approachable. We can do this transition using segment tree. As for $$$f(i, j)$$$, it is actually the contribution of the intervals ending in $$$i$$$. Let's try not to add this contribution all at once using $$$f(i, j)$$$ and add them separately for each interval. What positions does an interval $$$(j, i)$$$ affect?. It actually only increases all positions $$$dp(i, j)$$$, $$$dp(i, j + 1)$$$ $$$\dots$$$ $$$dp(i, i)$$$ by $$$1$$$. Hmmm, so we only have to handle ranged updates that increase all elements in an interval with a fixed value and queries regarding the maximum value on some interval. This does sound a lot like segment tree with lazy propagation...
The most important aspect of this problem is the fact that sometimes, it is necessary to use more advanced variations of segment trees to solve them.
This problem can be found here. Unfortunately, it is on a Romanian website and its statement is not available in English. However, you can still use the website to submit your own solution to this problem. A sample submission implementing this approach that runs in $$$O((N + Q)logN)$$$ can be found here.
Obfuscation
Sometimes, the solution can be obfuscated under multiple layers of seemingly unrelated things. One extraordinary (quite underrated) example is the problem Colouring a rectangle from EJOI 2019 :
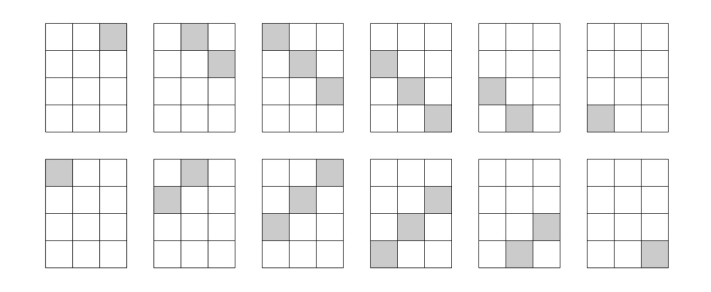
This problem seems unapproachable at first sight and completely unrelated to dynamic programming or segment trees. However, we only need to make some observations first.
Let's define LR-diagonals as diagonals that go from an upper-left position towards a lower-right position. In an analogue way, let's also define RL-diagonals as diagonals that go from an upper-right position towards a lower-left position. Also, note that we will index the rows and columns starting from $$$0$$$ and we will identify the element on row $$$i$$$ and column $$$j$$$ as $$$(i, j)$$$.
One known property of LR-diagonals is that $$$(i, j)$$$ and $$$(x, y)$$$ are on the same LR-diagonal if and only if $$$i - j = x - y$$$. RL-diagonals also have a similar property, namely $$$(i, j)$$$ and $$$(x, y)$$$ are on the same RL-diagonal if and only if $$$i + j = x + y$$$.
Since all elements in a LR-diagonal have a common invariant, let's use that invariant to identify diagonals. For example we will say that all elements $$$(i, j)$$$ make part of the LR-diagonal with id $$$i - j$$$. Similarly all elements $$$(i, j)$$$ also make part of the RL-diagonal with id $$$i + j$$$.
Thus, all LR-diagonals can be assigned an id ranging from $$$-(m - 1)$$$ to $$$(n - 1)$$$ and all RL-diagonals can be assigned an id ranging from $$$0$$$ to $$$(n - 1) + (m - 1)$$$.
Another interesting property of those diagonals is that LR-diagonals with even id's only intersect with RL-diagonals with even id's. The same is true for odd id's. An even more interesting property about the intersection of these diagonals is that all odd LR-diagonals intersect with a consecutive interval of odd RL-diagonals. The reverse is also true, all even LR-diagonals intersect with a consecutive interval of even RL-diagonals.
After all of these observations, we can finally start solving the problem. Since even diagonals don't intersect with odd diagonals, we can simply consider $$$2$$$ separate problems. Each element is at the intersection of a LR-diagonal and a RL-diagonal. This means that we have to color either the respective LR-diagonal or the respective RL-diagonal.
Let's choose a set of LR-diagonals to color, then color the necessary RL-diagonals. Since a RL-diagonal only intersects with a interval of LR-diagonals, the problem can be reformulated as follows:
"You are given an array with $$$N$$$ white cells. We can paint element $$$i$$$ for the price of $$$p_i$$$ coins. You are also given $$$Q$$$ restrictions. A restriction $$$(x_i, y_i, c_i)$$$ means that if the interval $$$[x_i, y_i]$$$ has at least one unpainted cell we have to pay an additional $$$c_i$$$ coins. Paint the array and fulfill all restrictions using a minimal number of coins"
One can easily see the connection between this problem and the original one. The array elements are the LR-diagonals and the restrictions are the RL-diagonals in disguise. This new problem seems much more approachable than the original.
From here on, we will simply do the same thing as in the previous problem. The only difference is that now we are actually punished for leaving an interval uncompleted, whereas previously we were rewarded for this.
Practice Problems
Conclusion
I hope you all liked this post. Also, if you know any additional problems or tricks related to this subject, please suggest them.







Is this a speedrun to top contributors?
Somebody once told me... about this technique.
Now that's how I just spent 2 hours...
This problem is a nice application of this technique.
Normalization is also known under the name of coordinate compression.
Another interesting problem
Hello! Sir! Nice tutorial! I saw another list of problems! Here it is!
Hi. When we decide to pick i position shouldnt dp[i][j] be dp[i-1][j] + f(i, j) + f(i, j) — k? because we put some color in i position so it is f(i,j)-k and also adding white color
This is another problem.