


Hello all!
I have some news to share about CF-Predictor (a service that allows you to view rating changes before official results). This extension was launched almost 6 years ago. Number of users has grwon from a couple hundreds to nearly 50k! I'm very proud that this service is used by so many people!
One of the cool features of mine extension is that it is friendly to codeforces API :) All the request to codeforces are sent from just one backend server. Therefore, users don't overload codeforces with extra API calls.
I was using Heroku as a cloud provider to run my servers. Unfortunately, they are closing their free accounts on Nov 28th. So, I decided to take down my servers on heroku. Thus, starting from 2022-11-27 cf-predictor-frontend.herokuapp.com and cf-predictor.herokuapp.com will not work.
On a bright side, I though that upsetting 50k people isn't a good thing. Therefore, I'm renting a VPS and you can continue to use CF-Predictor via cf-predictor.wasylf.xyz! I already updated extentions for Chrome, Mozilla and Opera to use the new backends. However only Mozilla has accepted the new version so far. I hope the changes will be reviewed quickly and you all will be able to use new version soon!
Good luck to all of you and have a high rating!










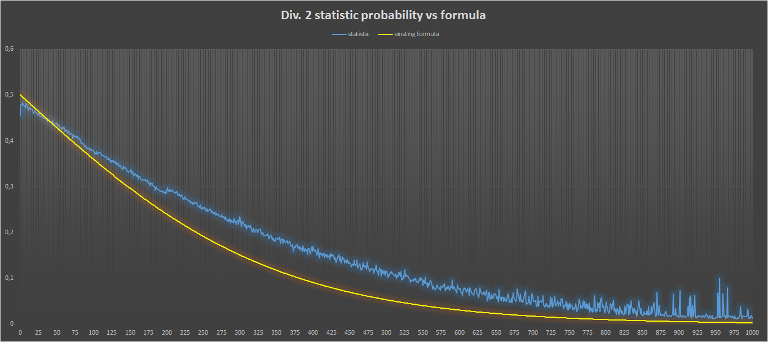
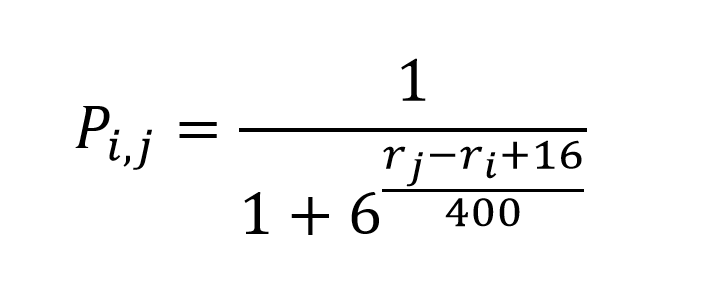
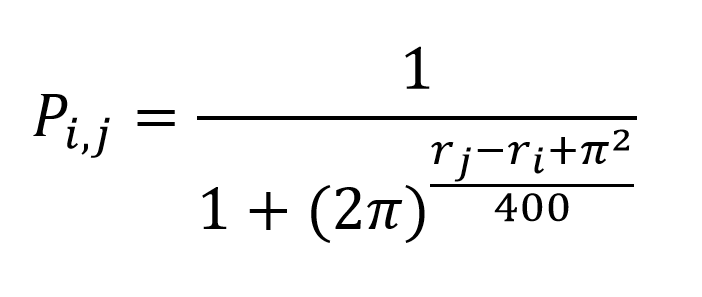
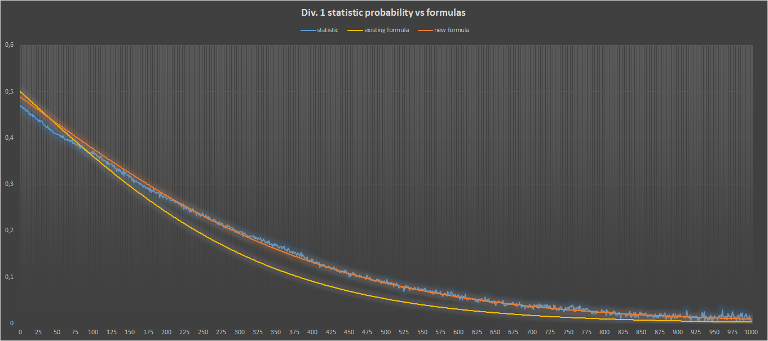







{kind=link}