hi
Today's post continues my theme of niche but sometimes useful topics in CP. This idea was brought to my attention by magnus.hegdahl, so thanks to him!
General Description
The motivation behind the technique is to solve the following problem: Given a static array $$$a$$$ of $$$n$$$ elements (for convenience, I'll assume $$$n$$$ is a power of $$$2$$$, if not, the array can be padded with null elements), answer $$$q$$$ queries of the form $$$($$$$$$l$$$, $$$r$$$, $$$x$$$$$$)$$$ where you have to print $$$\sum\limits_{k = l}^r a_{k \oplus x}$$$. In particular, a query where $$$x = 0$$$ is just a normal segtree query. If $$$x$$$ is non-zero, the array indices that are being queried are no longer contiguous, making this impossible to solve with a normal segtree. Note: the only requirement is that the "addition" operation is associative (commutativity is not required). The solution provided in this blog solves the problem in $$$\mathcal{O}(n \log{} n + q \log{} n)$$$ with $$$\mathcal{O}(n \log{} n)$$$ memory. The memory can be reduced to $$$\mathcal{O}(n)$$$ if the "addition" operation is commutative.
About the name: I've seen it called XOR segment tree in 2 different places, so I assume that's what people know it as. Let me know if you've seen it being called something else.
For the rest of this tutorial, I will assume that you use a recursive implemenetation of segment trees.
Commutative case
To start off, let's solve the commutative case. Later, we'll extend these ideas to solve the non-commutative case. First, you build a normal segtree, where each segtree node's length is a power of $$$2$$$ (remember, we're assuming that the length of the full array is a power of $$$2$$$), where the value of a segtree node is the sum of the array elements in it's subtree. The first observation to make is that, for a fixed segtree node, the binary representation of the original array indices in its subtree consists of a fixed prefix of bits, followed by an arbitrary suffix.
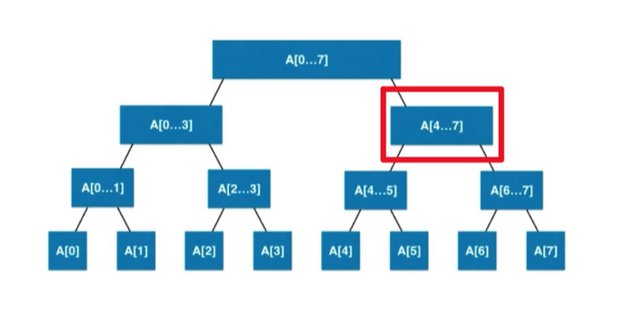
To clarify, if a segtree node contains the array indices $$$[4, 5, \ldots 7]$$$, (i.e. the highlighted node in the image above) the binary representations of the elements are be $$$1**$$$ where $$$*$$$ represents any binary digit. This is true for any segtree node, some prefix will be $$$1$$$'s and $$$0$$$'s, while the rest will be $$$*$$$'s. The second observation to make is that, for all $$$i$$$, if the $$$i$$$-th bit in $$$x$$$ is on, that is equivalent to swapping the children of all segtree nodes on the $$$i$$$-th level, and running a normal query on the transformed segtree. This directly follows from the first observation.
With this in mind, let’s formulate a segtree query. We will maintain the following invariant throughout the recursion: if you’re at a segtree node at level $$$l$$$, all bits higher than $$$l$$$ are turned off in $$$x$$$. We will deal with them while processing the segtree nodes at that level (so we can essentially forget about the $$$l$$$-th bit after we process the $$$l$$$-th level). To start off, let’s consider the standard base cases in a segment tree. If the current segtree node you’re recursing through is completely disjoint from the query range, we can exit immediately, and return $$$0$$$. If the current segtree node is completely contained within the query range, we can exit immediately as well, as we already know the sum of the array elements in the subtree of the segtree node. The tricky case is when the query range is a sub-range of the segtree node. If the node we’re processing is at level $$$l$$$, and the $$$l$$$-th bit of $$$x$$$ is $$$0$$$, we can recurse to the children as if we’re processing a regular segtree query. However, if the $$$l$$$-th bit is $$$1$$$, we need to effectively swap the children of the segtree. This is easy enough to do, instead of directly swapping the children, you can figure out what range of each child you would visit if you swapped the children, and use those modified ranges when recursing. Read the code example at the bottom for more details.
Non-commutative case
For the non-commutative case (the more interesting one), the query remains mostly the same. The issue is when the segtree node is completely contained within the query range. In the commutative case, we just instantly returned the value stored in the segtree node. However, in the non-commutative case, the value of $$$x$$$ still matters, so the same strategy doesn’t work. The solution to this is to precompute the value of the segtree node for every value of $$$x$$$. Note that, for a segtree node at level $$$l$$$, the only relevant values of $$$x$$$ are those whose highest set bit is at most $$$l$$$, so the total number of relevant $$$x$$$ values over all segtree nodes is $$$\mathcal{O}(n \log{} n)$$$.
We will precompute these values starting from the leaf. The only relevant $$$x$$$ value for a leaf is $$$0$$$, so that can be calculated easily. For all other nodes, we will use the values computed by the children. If the $$$l$$$-th bit in $$$x$$$ is $$$0$$$, we can just combine the values computed for $$$x$$$ for the left child and the right child. If the $$$l$$$-th bit in $$$x$$$ is $$$1$$$, you combine the values computed for $$$x$$$ for the right child and the left child (turning off the bit when you combine them). This works because of observation 2 (you’re essentially swapping the order of the children).
Problems
Code example:
Thanks! Let me know if you have any problem suggestions or if there's anything that should be fixed.