Background
When Catalog was first introduced, I asked for a way to sort by blog creation time to be able to check for new blogs. Sadly, this has not been implemented, at least the way I imagined it (there is a time filter though). So, I decided to implement it myself. The result is an userscript.
Features
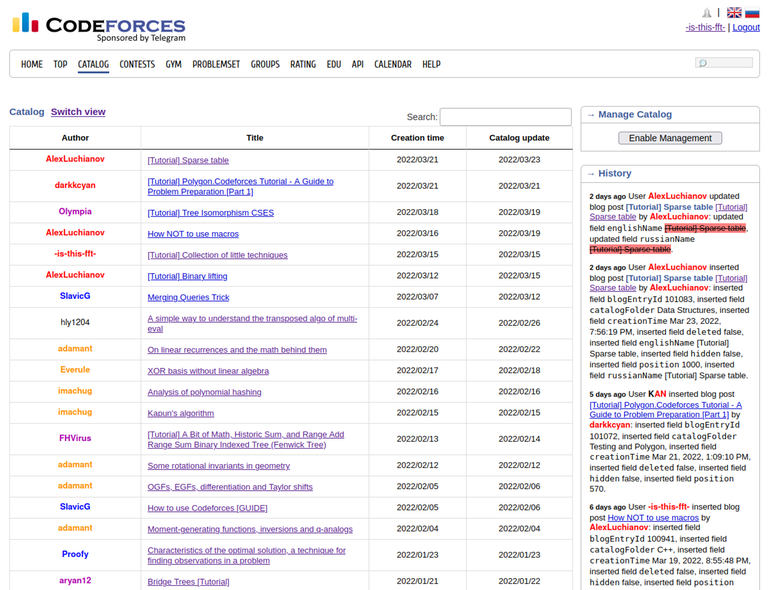
I think the concept is pretty self-explanatory. Some notes:
- You can click on the table headers to sort by a field. By default, we sort descending based on creation time.
- Whether or not you are using the table view is saved in a cookie. If you have turned on table view, it will still be on the next time you visit the page, so you can use it as a "default" if you want to.
- The script is disabled when in management mode because you can't really do management in this view.
- Open source, so you can customize it if you want.
Installation
- Install an userscript manager to your browser. I used TamperMonkey, I can't guarantee anything for other userscript managers.
- Find the "create new script" option and paste in the code. The code is available here.
PS: the code is very quick-and-dirty, don't judge!