


Hello Codeforces,
CSES is a nice collection of classical CP problems which encourages you to learn a lot of basic and advanced concepts. Having editorials would help people to not get stuck on a problem for long. Here are my solutions to the tree section of the problem-set. Looking forward to read corrections/feedback/better solutions in the comment section. Happy coding!
Subordinates
This can be solved using basic DP approach in linear time.
$$$subordinates[u] = \sum\limits_{v:children[u]}^{} subordinates[v]$$$ where v is a child of u
Tree Matching
This problem can be reduced to maximum bipartite matching problem but first we need to split the tree into a bipartite graph. One way to do that is to put all nodes at even depth in the first group and odd ones in the other group. Such a splitting will make sure that we do not have any edges within the same group.
Next, we can use Hopkraft Karp algorithm to find the maximum matching in the bipartite graph created.
Tree Diameter
This is a classical problem having multiple solutions.
One easy to implement solution is using 2 Breadth First Searches (BFS). Start a BFS with a random node and store the last node encountered before search ends. This last node will definitely be one of the ends of the diameter (Why?). Now run a second BFS from this node and you will end on the other end of the diameter.
Tree Distances I
For each node, we want to calculate maximum distance to another node. Previously we saw that that if we start a BFS from any node, we end up on either of the diametric end. We can use this fact to efficiently compute the answer. Let's calculate distances of each node from both the ends of the diameter. Then maximum distance of each node can be calculated as:
max_distance[u] = max(distance_from_diametric_end1[u], distance_from_diametric_end2[u])
Tree Distances II
We can solve this problem using in-out DP on trees.
$$$in[u]:$$$ sum of distances from u to each node in subtree rooted at u
$$$out[u]:$$$ sum of distances from u to each node excluding the subtree rooted at u
Now, ans[u] = in[u] + out[u]
Calculating $$$in[u]$$$ is quite straightforward. Suppose we want to calculate the sum of distances starting at node u and ending at any node in subtree rooted at v. We can use the pre-calculated value for v and separately add the contribution created by edge $$$u\rightarrow v$$$. This extra quantity will be the subtree size of u. Then we can repeat the process for each child of u.
$$$in[u] = \sum\limits{}{}in[v] + sub[v]$$$ where v is a child of u
To calculate $$$out[u]$$$, first let's calculate the contribution of parent of u. We can use out[par] and add the difference created by the edge $$$u \rightarrow par_u$$$ which is n-sub[par]+1. Next, we add the contribution of all siblings of u combined, considering all paths starting from u and ending in a subtree of one the siblings: in[par]-in[u]-sub[u] + (sub[par]-sub[u]-1).
Finally we have the following formula:
$$$out[u] = out[par] + (n-sub[par] + 1) + in[par]-in[u]-sub[u] + (sub[par]-sub[u]-1)$$$ $$$out[u] = out[par] + n + in[par] - in[u] - 2*sub[u]$$$
Company Queries I
We can solve this problem using binary-lifting technique for finding ancestors in a tree.
For each node x given in a query, we just need to find the $$$k^{th}$$$ ancestor of a given node. We can initialise ans = x and keep lifting our ans for every $$$i^{th}$$$ bit set in k: ans = jump[i][ans] where $$$jump[i][j]$$$ holds $$$i^{th}$$$ ancestor of node $$$j$$$
Company Queries II
This is the classical problem of finding Lowest Common Ancestor which can be solved in multiple ways. One of the common ways is to use binary-lifting which requires $$$O(nlog(n))$$$ preprocessing and $$$O(logn)$$$ per query.
Distance Queries
Distance between node u and v can be calculated as $$$depth[u] + depth[v] - 2*depth[LCA(u,v)]$$$.
LCA of (u,v) can be calculated using binary-lifting approach in $$$O(logn)$$$ per query.
Counting Paths
This problem can be solved using prefix sum on trees.
For every given path $$$u \rightarrow v$$$, we do following changes to the prefix array.
prefix[u]++
prefix[v]++
prefix[lca]--
prefix[parent[lca]]--
Next, we run a subtree summation over entire tree which means every node now holds the number of paths that node is a part of. This method is analogous to range update and point query in arrays, when all updates are preceded by queries.
$$$prefix[u] = \sum\limits_{v:children[u]}^{} prefix[v]$$$
Subtree Queries
This problem can be solved by flattening the tree to an array and then building a fenwick tree over flattened array.
Once reduced to an array, the problem becomes same as point update and range query. We can flatten the tree by pushing nodes to the array in the order of visiting them during a DFS. This ensures the entire subtree of a particular node forms a contiguous subarray in the resultant flattened array. The range of indices corresponding to subtree of a node can also be pre-calculated using a timer in DFS.
Path Queries
This problem can be solved using Heavy-Light decomposition of trees.
First, we decompose the tree into chains using heavy-light scheme and then build a segment tree over each chain. A path from node u to v can seen as concatenation of these chains and each query can be answered by querying the segment trees corresponding to each of these chains on the path. At each node of segement tree, we store the sum of tree node values corresponding to that segment. Since heavy-light scheme ensures there can be at most $$$O(logn)$$$ chains, each query can be answered in $$$O(log^{2}n)$$$ time.
Similarly, each update can be performed in $$$O(logn)$$$ time as it requires update on a single chain (single segment tree) corresponding to the given node.
Path Queries 2
This problem has similar solution as Path Queries. Instead of storing the sum of nodes in segment tree, we store the maximum of node values corresponding to that segment.
Distinct Colors
This problem can be solved using Mo's algorithm on trees and can be reduced to this classical SPOJ Problem
Flatten the tree to an array using the same technique mentioned in solution of Subtree Queries. Then the subtree of each node will correspond to a contiguous subarray of flattened array. We can then use Mo's algorithm to answer each query in $$$O(\sqrt{n})$$$ time with $$$O(n\sqrt{n})$$$ preprocessing.
Finding a Centroid
We can precompute subtree sizes in a single DFS. We can recursively search for the centroid with one more DFS.
Fixed-Length Paths 1
Prerequisite: Centroid Decomposition of a tree
Hint: At every step of centroid decomposition, we try to calculate the number of desirable paths passing through the root(centroid). Since all nodes will eventually become centroid of a subtree, we claim all possible paths are considered. While processing a particular node, we can count the number of nodes at particular depth with cnt[d]++ and use this information to compute our result efficiently.
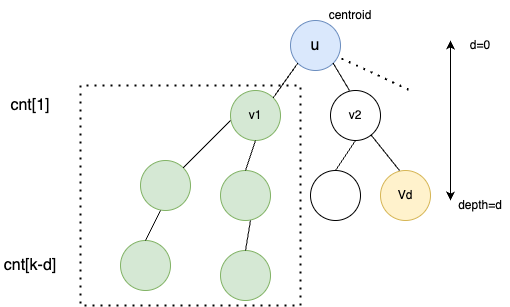
Explanation: Consider the diagram aboce where we are currently solving for tree rooted at $$$u$$$. Assuming we have already processed $$$v_{1}$$$ and its subtree. We have updated the cnt array accordingly. While processing node $$$V_{d}$$$, we know it can create $$$cnt[k-d]$$$ new paths of length $$$k$$$. Hence, we add $$$ans += cnt[k-d]$$$.
Once $$$ans$$$ is updated, we can process the subtree of $$$v_{2}$$$ and update $$$cnt$$$ which can be used while processing other children of $$$u$$$.
After processing the whole subtree of $$$u$$$, we decompose the tree by removing the centroid $$$u$$$ and repeat the same process for disjoint trees rooted at $$$v_{1},v_{2}, v_{3}$$$ and so on.
Complexity: Centroid tree has a height of $$$log(n)$$$. Each horizontal layer of tree takes an amortised time of $$$O(n)$$$ as explained above. Thus, total complexity becomes $$$O(n*logn)$$$.
Fixed-Length Paths 2
Approach 1: you can use centroid decomposition here as well but this time sum of all nodes in depth range $$$[k1-d,k2-d]$$$ must be added to $$$ans$$$. This is because all of these nodes will form a path length in range $$$[k1, k2]$$$. This can be done by using a Fenwick tree to calculate range sum efficiently. Although this works in $$$O(n*log^{2}n)$$$, this approach fails CSES time limits.
Approach 2: Prerequisite: Small-To-Large Merging
Instead of using centroid decomposition, we use small-to-large technique to reduce operations. And instead of fenwick tree we use suffix sum arrays to compute range sums efficiently.
For a particular node $$$u$$$ and a particular child $$$v$$$ of $$$u$$$, we maintain suffix sum of count of nodes present at a depth d from u.
$$$suf[i] =$$$ count of nodes having depth in range $$$[i, inf) $$$
Note that we can combine 2 suffix sum arrays efficiently in $$$O(min(|a|, |b|)$$$ using small-to-large merging technique.
For eg. $$$a=[a_{1},a_{2},a_{3}]
$$$
$$$b=[b_{1},b_{2}] $$$
can be combined as $$$[a_{1}+b_{1}, a_{2}+b_{2}, a_{3}]$$$
As stated in approach 1, for every node we want to know count of nodes in depth range $$$[k1-d, k2-d]$$$. We can calculate this contribution whenever we are merging smaller suffix sum array to larger one.
Source: https://usaco.guide/problems/cses-2081-fixed-length-paths-ii/solution
End Notes
- Thanks to pllk for such an amazing problem-set.
- Check out these awesome blogs for editorials to other sections
CSES DP section editorial
CSES Range Queries section editorial - Thanks to icecuber and kartik8800 for above editorials which eventually encouraged me to add this one.







It's been 4weeks and still, no one reacted?
This probably means he started working on the blog 4 weeks ago and not that he posted it 4 weeks ago.
How long have you been using CF, smh xD
Lol
Good job on the editorial!
you might like my DP solution(check code) for tree matching.
Thanks for mentioning! Seems like maximum matching was on overkill.
Thanks for this editorial, might motivate many people like me to practice tree problems!
Can someone please give the link for problemset.
https://cses.fi/problemset/list/
Jon.Snow Maybe add it to the blog post?
Thank you!
Yes, added to the post.
Post is itself a good one, just a add on, read this awesome blog by adamant on heavy- light decomposition, using this we can solve both path queries as well as subtree queries simultaneously.
There are some problems that can be done better :)
$$$dp(u, 0) =$$$ maximum number of offices in subtree of $$$u$$$, suppose $$$u$$$ is not included in matching
$$$dp(u, 1) =$$$ maximum number of offices in subtree of $$$u$$$, suppose $$$u$$$ is included in matching
Just take any leaf in the tree when possible
This one is special, since all path queries are from root to node.
Let's calculate the answer $$$ans[u]$$$ for every nodes $$$u$$$ at first.
When the value of a node $$$u$$$ changes, for which nodes do its answer changes?
The subtree of $$$u$$$ :)
So we can update answer of the entire subtree of $$$u$$$ by flattening the tree. Now the problem is literally "Subtree Queries".
This is an application of the small-to-large technique.
For each node of the tree, we maintain a set for all of its colors. When we need to merge a "parent" set with a "child" set, we simply merge the smaller child into bigger child, instead of otherwise.
And simply call dfs for any starting node you like.
Nice observations!
Will definitely try all these approaches.
Tree Matching :Greedy — sort all the edges according to the number of subordinates then check and count whether the nodes in the edge is taken or not :)
What is the full form of CSES?
code submission evolution system
You know many thing Jon.Snow.
Guarding the wall gets too boring
Thanks for the mention :)
Thanks for this! You can also add Graph editorials for CSES problem set to the list. They are not yet complete though
For Tree Distances I
max_distance[u] = max(distance_from_diametric_end1[u], distance_from_diametric_end2[u])Is there any proof for this?
First, suppose that $$$u$$$ is lying on diameter (path from $$$end1$$$ to $$$end2$$$). Now lets prove it by contradiction: suppose we can do (strictly) better. Without lose of generality, lets say that end1 is in the same "side" of the tree where is the node with whome we can do better (lets name that node $$$v$$$).
So since $$$v$$$ is on the same side as end1, and you need to pass throw $$$u$$$ to get to that side from $$$end2$$$, then distance from $$$end2$$$ to $$$v$$$ can be shown as sum of distance (from $$$end2$$$ to $$$u$$$) + (from $$$u$$$ to $$$v$$$). And we assumed that distance from $$$u$$$ to $$$end1$$$¸is shorter then from $$$u$$$ to $$$v$$$. Then distance from end2 to $$$v$$$ is (strictly) greater than distance from end2 to end1. (but end1 to end2 is diameter — longest distance possible!)
Simular can be shown if $$$u$$$ is not on diameter. Try working it out yourself! Good luck :)
Thanks for the editorial bro.
Nice editorial man! Please keep adding stuffs like this. They are really helpful atleast for newbies and beginnners!
Can Distinct Colors be solved using Segment Tree? I tried but it gives TLE as merging two sets is taking linear time How do i optimise it?
Transform the problem into a range query problem on an array using dfs order (Let this array of colors be
A)Let
Prev[i]be the maximum indexj<isuch thatA[j] = A[i](-1 if no such j exists)Let's say we're counting the number of distinct values in the range [L, R].
Fix a color and let's say its positions are
p1, p2, ..., pkin increasing order. Observe thatPrev[p1] < LandL <= Prev[pi] <= Rfor all2 <= i <= k. Therefore, for each colorCappearing at least once in the range [L, R], the number of indicesiwithC = A[i]andPrev[i] < Lis exactly one.Sum it over all colors, and we obtain that
(# of distinct colors in the [L, R]) = (# of indices with Prev[i] < L).Now our problem reduces to solving following range query problem:
Given an array, process query of form "given a range [L, R] and a value X, find the number of values in [L, R] less than X".You can use one of followings to solve the above problem (I could be wrong on some complexities)
(A) Wavelet Tree (O(N log MAXVAL) preprocessing, O(log N) per query, online)
(B) Mergesort Tree (O(N log N) preprocessing, O(log^2 N) per query, online)
(C) Any persistent data structure supporting point update and range query (O(N log N) preprocessing, O(log N) per query, online)
(D) Any data structure supporting point update and range query(O(N log N) preprocessing, O(log N) per query, offline)
I'll describe how to do (D). First three should easily be derivable once you know corresponding data structures. First, compress all the values if necessary.
We prepare a data structure DS supporting point update and range addition query. Initially, it should be filled with 0.
Solve the queries offline in increasing value of X.
When we process the query [L, R] with X, we'll require DS to satisfy the following invariant: for each position 1<=i<=n, i-th value of DS is equal to one if and only if Prev[i] < X.
Using this invariant, the answer to the current query is simply the range sum query [L, R] for DS.
To preserve this invariant, we keep a sorted list of pairs (Prev[i], i), and then when we process the query, we pop the front of the list, update i-th position of our DS to one, as long as Prev[i] < X is satisfied.
In ETT you can access subtrees as subarrays, so build an ETT, and just solve the number of distinct elements with segment tree
Path Queries 1 , could be solved using Tree flattening and Segment tree . The basic idea is that change in value of node 's' changes only the values of all nodes in its subtree , so we can use range update , point query segment tree to solve it in O(NlogN) AC solution
For Distance Queries how to construct a solution if the graph is weighted?
Replace depth by distance_from_root in the formula.
So you'll have to precompute distances to all nodes from root.
Nice Job. It would be great if you could add CSES Graph Algorithm section editorials.
Is there any other way to solve Tree Distance I, without bfs in particular?
yes, find the 2 ends of the diameter with 2 dfs, and ans[i] = max(dist[(i, diam1)], dist[i, diam2])
Could someone explain Tree Distances II in a little more detail
What part of the solution do you need details on? I can update the blog accordingly
the part of rerooting to calculate out[u] is where i couldn't get proper clarity
o u t [ u ] = o u t [ p a r ] + ( n − s u b [ p a r ] + 1 ) + ( ∑ s i b
i n [ s i b ] + s u b [ s i b ] ∗ 2 ) − ( i n [ u ] + s u b [ u ] ∗ 2 )
this part
To be clear, $$$out[u]$$$ signifies sum of distances starting from node u and going up. These paths end at nodes which are not in subtree of u.
Let's break down the formula to individual pars: out[u] =
$$$out[par]+(n-sub[par]+1)$$$ -> This is the sum of distances of all paths starting from u, going up to its parent and further up, ending at nodes that are not in subtree of u or any subtree of it's sibling. We are assuming $$$out[par]$$$ is already calculated. The extra contribution of $$$(n-sub[par]+1)$$$ comes from the edge {u, par}. This is count of nodes excluding subtree of u and all subtree of siblings of u.
$$$+\sum(in[sib]+sub[sib]*2)$$$ -> Next we need to calculate contribution of paths that go up from u but end in subtree of any of it's siblings. Each of the sibling gives an extra contribution of 2 because of edge length of u->par->sib. Hence the term $$$sub[sib]*2$$$. We add it to already calculated in[sib].
$$$-(in[u]+sub[u]*2) $$$-> We subtract $$$in[u]+sub[u]*2$$$ since we are not interested in paths going downwards while calculating $$$out[u]$$$. This is a correction term for the summation term above.
Note that for calculating $$$in[..]$$$, we use bottom-up DP while for $$$out[..]$$$, we use top-down approach.
Interestingly, you can get the O(n*(log(n))^2) to Fixed-Length Paths 2 to pass by simply changing
vector<int> adj[SZ];to:basic_string<int> adj[SZ];with max runtime 0.72s
from where to learn these data structures like basic_string
thanks bro :)