


Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
Tutorial is loading...
| № | Пользователь | Рейтинг |
|---|---|---|
| 1 | tourist | 3993 |
| 2 | jiangly | 3743 |
| 3 | orzdevinwang | 3707 |
| 4 | Radewoosh | 3627 |
| 5 | jqdai0815 | 3620 |
| 6 | Benq | 3564 |
| 7 | Kevin114514 | 3443 |
| 8 | ksun48 | 3434 |
| 9 | Rewinding | 3397 |
| 10 | Um_nik | 3396 |
| Страны | Города | Организации | Всё → |
| № | Пользователь | Вклад |
|---|---|---|
| 1 | cry | 167 |
| 2 | Um_nik | 163 |
| 3 | maomao90 | 162 |
| 3 | atcoder_official | 162 |
| 5 | adamant | 159 |
| 6 | -is-this-fft- | 158 |
| 7 | awoo | 155 |
| 8 | TheScrasse | 154 |
| 9 | Dominater069 | 153 |
| 10 | djm03178 | 152 |
UPD: обратите внимание, распределение баллов изменилось
UPD2: LHiC нашел ошибку в авторском решении на div1-F. Мы исследуем вопрос.
UPD3: мы нашли правильное решение для div1-F и оба решения отправленных на контесте проходят все тесты против правильного решения => раунд по прежнему рейтинговый.
Всем привет,
Время старта Codeforces Round 488: 16.06.2018 19:35 (Московское время). Это будет раунд для обоих дивизионов. Раунд будет длиться 2.5 часа (это на пол часа больше чем обычно).
Контест подготовлен компанией NEAR и ее друзьями. В NEAR мы учим машины участвовать в соревнованиях по программированию. В этом блог-посте можно прочитать (на английском) о том, где сегодня находятся исследования в этой области, чем занимается непосредственно NEAR, и как вы можете помочь нам в этом нелегком деле.
На контесте будет предложено по шесть задач в каждом дивизионе, 4 задачи из которых общие.
Почти все задачи взяты с тестовых раундов, которые проводились на JavaBlitz в прошлом году. Если вы участвовали в одном из JavaBlitz раундов, то этот CBR, к сожалению, придется пропустить.
Распределение баллов в первом дивизионе -- 500-1000-1000-1500-2250-3000
Во втором -- 500-1000-1500-2000-2000-2500
Раунд в обоих дивизионах рейтинговый.
Все задачи написаны мной, Александром "AlexSkidanov" Скидановым, и Никитой "FalseMirror" Босовым. David "pieguy" Stolp, Александр "AlexFetisov" Фетиско, Marcelo "mnaeraxr" Fornet, Николай "KAN" Калинин и Михаил "cerealguy" Кевер оказали неоценимую помощь в подгтовке раунда и тестировании задач.
В завершении хочется в очередной раз напомнить, что мы постоянно ищем людей, которые помогут нам с разметкой данных с архивов по спортивному программированию. Больше информации здесь.
Поздравляем победителей!
Div. 1:
Div. 2:
Разбор опубликован тут. Спасибо за участие!
Всем привет,
Три дня назад я написал большой пост (на английском) о том, как мы учим машины писать код (и тем самым приближаем технологическую сингулярность).
В этом посте я хотел напомнить, что мы платим около $12/час людям, которые помогают там с аннотацией данных с архивов соревнований по программированию.
Платформа находится по адресу:
Чтобы участвовать, нужен разумно хороший уровень английского языка.
Для тех, кто готовится к ICPC и из-за этого не работает, это должно быть очень удобно.
Хотите помочь как-то иначе? Может быть вы знаете архивы задач, в которых все решения публичны, как на CodeForces? Напишите ссылку. Язык, на котором условия, не важен, мы можем их переводить с разумной скоростью (спасибо платформе выше).
Или может вы прорешивали какой-то архив где решения не публичны, и готовы поделиться с нами аккаунтом? Это тоже помогает очень сильно.
Давайте строить сингулярность вместе!
Hi, all,
I with few other folks at NEAR work on teaching machines to program. A particularly exciting sub-project of that is teaching machines to solve competitive programming problems.
In this post I would like to give a quick overview of where the state of the art is today, what the major challenges are, why this is not a popular area of research, and how the CodeForces community can help to address some of the issues the program synthesis community is facing today.
We also have a certain budged allocated for this project, and we are paying to the CodeForces members who help us with some data annotation challenges. We have paid more than $10k in our first two annotation projects, and are launching three more projects today. Scroll to the end if you are interested.
With the emergence of deep learning, neural networks started performing almost at a human level in many tasks: visual object recognition, translation between languages, speech recognition, and many other. One area where they haven't shown anything exciting yet is programming. I will talk about state of the art below, but overall neural networks are nowhere close today to doing actual coding.
But what would it even mean to solve programming? What would be a good benchmark and milestones to recognize? One such milestone is solving competitive programming. We are not talking here about building a bot that would perform at a tourist level, but at least solving A and B Division two would be super impressive. Even this is actually very hard for computers, and I will talk about why below in the Open Challenges section.
The area of research that is tasked with automated program generation is called Program Synthesis. The two most common sub-areas of it are programming from examples (synthesizing a program from few input/output examples of what it should do) and programming from description (synthesizing a program from an English description).
Programming from examples has a long history. One known example that you can run in your browser is Magic Haskeller, which is a very sophisticated system that synthesizes rather nontrivial Haskell programs from just one example.
There were some applications of program synthesis from example in commercial products. Modern distributions of Excel come with a feature called FlashFill. If you have a column of names, and a column of last names, and enter an email in the third column in a form of "[email protected]", FlashFill will immediately synthesize a program that concatenates the first letter of the first name with a dot, the last name and the "@gmail.com" and suggest to auto-fill the rest of the column. This looks like magic, and took more than a year of work for a very strong team of program synthesis experts at Microsoft Research to deliver it.
Ultimately the lab that created FlashFill created a general purpose framework PROSE in which one can create services like FlashFill by describing a domain-specific language and writing few C# functions.
A separate epic paper from a different lab at MSR called TerpreT serves as a great review and comparison of different approaches to programming from examples. It compares using SMT solvers, linear programming and neural networks, and shows that as of today using more traditional approaches such as SMT solvers still noticeably outperforms deep learning approaches.
An early attempt to apply programming by example to solving competitive programming is a paper from the same lab called Deep Coder. It can synthesize short programs for very simple problems by seeing just a few examples, and uses a combination of both deep learning and several traditional approaches.

Another great inspiring example of applying program synthesis from examples is a paper called Chlorophyll, in which the technique is applied to optimizing assembly programs. It does it in the following way:
Mindblowingly, not only this works, it generally converges for short programs in under 10 iterations!
Programming from description is a more recent area of research. Until the emergence of Deep Learning few years ago there was no sufficiently general way of extracting information from natural language. Arguably, even with the modern Deep Learning approaches natural language understanding is still at a pretty early stages, which is one of the major limitations.
There were papers that attempt to solve synthesis of SQL, BASH and Java from description, but they all face the challenges described below. To my best knowledge no application of synthesis from description appears in any commercial product today.
Number of labs that work on program synthesis is actually rather small. Besides NEAR, here are several well-known ones:
MIT lab lad by Armando Solar-Lezama
ETH Zurich lab (notably Veselin Raychev and Martin Vechev), which ultimately incorporated into DeepCode.ai
Microsoft Research has a long history of working on program synthesis. Here are two good publication aggregates: one and two.
When we talk about programming from description, there are several large challenges, all remaining mostly unsolved as of today.
This might sound crazy -- GitHub has so much code that even just crawling all of it is a non-trivial task, how could the data be lacking? But as a matter of fact, the data that is readily available, such as GitHub or StackOverflow, is not immediately usable because it is very noisy. Here are some datasets that we considered, and what challenges they come with:
Small commits that fix a simple bug, and the text of the associated issue. The person who fixes a bug has a lot of context about how the code operates. This context varies drastically between projects, and without it even an experienced human expert would not be able to predict the change in the code given the issue text.
Commit messages and the code. Besides commits also depending significantly on the context (i.e. a human expert often won't be able to predict the code in the commit given a well-formed commit message), this dataset also has a lot of noise. People often provide incorrect commit messages, squash multiple features and fixes into one commit describing only one feature, or generally writing something like "Fixing a bug we found yesterday".
Docstrings and function bodies. This one was very promising, but has two issues: a) docstring describes how a function shall be used, not how it is implemented, and predicting code from the usage pattern is a harder task than predicting code from a task description; and b) even in very good codebases quality docstrings are usually only provided for the public APIs, and the internal code is generally way less documented.
On the other hand, there's also competitive programming archives. Competitive programming as a dataset has several advantages:
The code is short and self-contained.
No context besides the problem statement is needed to write it.
The dataset of statements and accepted solutions is very clean -- accepted solutions almost certainly solve the problem from the statement.
There are however some challenges:
While the number of solutions is very high (CodeForces alone has dozens of millions), the number of different problems is somewhat low. Our estimate suggests that the total number of different competitive programming problems in existence is somewhere between 200k and 500k, with ~50k being attainable with solutions when a reasonable effort is made. Only 1/3 of those problems are easy problems, so we are looking at having ~17k problems available for training.
The statements contain a lot of fluff. Alice and Bob walking on a street and finding a palindrome laying around is something I had in my nightmares on multiple occasions. This unnecessary fluff paired with relatively low number of problem statements further complicates training the models.
The lack of data is also the primary reason why program synthesis is not a popular area of research, since researchers prefer to work on existing datasets rather than figuring out where to get data from. One anecdotal evidence is the fact that after MetaMind published the WikiSQL dataset, multiple papers were immediately submitted to the coming conferences, creating a minor spike in program synthesis popularity, despite the fact that the quality of the dataset is very low.
Having said that, annotating the competitive programming dataset to a usable state would increase the popularity of the field, bringing closer the moment when we are competing against bots, and not just humans.
Consider the following problem that was recently given on CodeForces: given an array of numbers of size 5000, how many triplets of numbers are there in the array such that the XOR of the three numbers is zero, and the three numbers can be the sides of a non-degenerate triangle.
This is Div1 A/B level, with most people with experience solving it easily. However from a machine perspective it is extremely hard. Consider the following challenges:
The model would need to realize that it doesn't need to fix all three numbers, it is sufficient to fix two numbers, and check if their XOR exists in the array. (this is besides the fact that the model would need to understand that fixing three numbers would not fit into timelimit)
The model would need to somehow know what does it mean for three numbers to be sides of a non-degenerate triangle.
Out of 50k problems that we have collected, only few had used that particular property of XOR in a similar way, and only a few dozen were in some way referring to the property of the sides of the triangle. To make a machine learning model be able to solve such a problem, one of the three things will need to happen:
We will find a way to learn from few examples. One-shot learning is a hot topic of research, with some recent breakthroughs, but no existing approach would be immediately applicable here.
We will find a way to provide the model with some external knowledge. This is an area that hasn't been researched much, and even figuring out how that knowledge shall be represented is a challenging research task.
We will find a way to augment the dataset in such a way that a single concept that occurs only a few times in the dataset instead appears in a variety of contexts.
All three of those are open challenges. Until they are solved, we can consider an easier task: solving a competitive programming problem that is (either initially, or by the means of rewriting) very close to the solution, e.g:
"Given an array of numbers, are there two numbers a and b in that array such that c = a XOR b also appears in the array, and the largest number among a, b and c is smaller than the sum of the remaining two?"
Can we solve it? With the modern technology not yet, and it makes sense to learn how to solve such problems before we even get to the more complex one-shot learning part.
Deep Learning models by design are probabilistic. Each prediction they make has some certainty associated with it, and therefore they generally keep having some chance of making a mistake even when trained well. If a model predicts code one token at a time, and a code snipped comprises 200 tokens, the model with 99% per-token accuracy would mess up at least one token with probability 87%. In natural language translation this is acceptable, but in Program Synthesis messing up one token most likely leads to a completely wrong program.
Notably, more traditional approaches from code synthesis (used primarily for programming by examples) don't suffer from the same problem. Marrying classic programming languages approaches with deep learning approaches is very desirable, but at this time very little success was achieved.
At NEAR, we are attempting to address many of the above problems. Here I will shortly cover our efforts that are relevant to solving competitive programming.
As I mentioned above, even though competitive programming data is rather clean, it has some unnecessary fluff in the statements that we'd love to get rid of. For that we asked the community to rewrite problem statements in such a way that only a very formal and dry description of what exactly needs to be done is left.
We also used help of the community to collect a dataset of statement-solution pairs in which no external knowledge (such as properties of XOR or triangles) is needed to write the solution given the statement. We plan to release a large part of this dataset during NAMPI 2018, so stay tuned.
This dataset is a set of problems with statement super close to the solution. Such problems are easier for a machine than even the simplest real problems on a real contest, but this dataset not only serves as the first milestone (being able to solve it is a prerequisite to solving more complex problems), it is also a good curriculum learning step -- a model that was taught to solve such problems is expected to pick up solving more complex problems more easily than a model that was not.
To augment the dataset above, we created an algorithm that gets a solution as an input, and produces a very low level statement (very close to the solution) as an output. The generator is built in such a way that the statements generated are close in terms of certain metrics to what people have written. Training on such generated dataset achieves a non-zero accuracy on the human generated dataset, and the closer we get the generated statements to what people write in terms of the measurable metrics (such as BLEU score), the better the accuracy of the trained model on the human-generated set is.
"Non-zero accuracy" might not sound very impressive, but if you consider the fact that it effectively means that the model manages to learn how to solve some (albeit very simple) human-generated problems by only being trained on a synthetic data, it is actually very promising, and is a huge step towards solving more complex problems, and ultimately solving actual contest problems on a live competition.
At the core of our approaches are deep learning models that read in text and produce code as either a sequence of tokens, or an AST tree. Either way, as mentioned above, even a very well trained model has a very high chance of messing up at least one token.
Trying to address this problem is on its own very close to what competitive programmers do. We explore quite a few approaches. We presented one such approach in our ICLR workshop paper -- the idea is to perform a beam search on AST trees until we find an AST of a program that passes sample tests. By the time we were publishing that paper we didn't have a good human-annotated dataset yet, so all the results were presented on a semi-synthetic dataset, but the model itself was not changed much since then, and we still use it on the human-annotated data today.
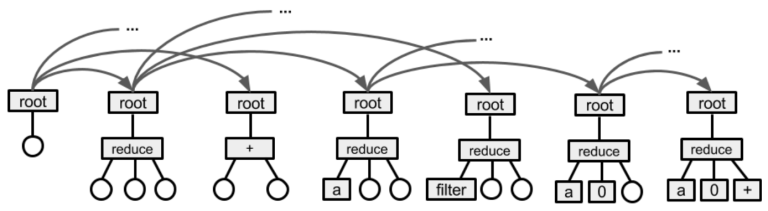
Running beam-search in the tree space is pretty slow and memory-consuming, and requires some tricky optimizations, such as using persistent trees, precomputing results on the go and others. Anyone knows a good place where I can find people who are good at writing complex algorithms on trees and who'd like to join a Silicon Valley-based VC-funded company that teaches machines to write code?
Another approach we researched is letting another (or the same) deep learning model to fix the program if the first program that was generated doesn't pass the samples. The high level idea is to train a model that takes as an input a problem statement and a program from the previous iteration alongside with some feedback on why the program is wrong, and generates a new program (either from scratch, or by producing a diff). We have a publication that reports some early results that was also accepted as a workshop paper at ICLR 2018.
To get to some more interesting ideas, let's consider us asking the model to implement a binary search. Imagine that it mistakenly swaps lines left = middle and right = middle. If you then feed the code back to the model, spotting this bug would be extremely hard. Even for humans it is a non-trivial task. So is the original source code the best medium to feed back to the model? One option we have been exploring is feeding an execution trace instead. If the model made the mistake above, the execution trace would always converge to one of the ends of the range instead of some value in the middle, which would provide way more information to the model than just the code itself. The challenge, however, is that execution traces of real programs are rather long, and condensing them to only show information that is likely to be relevant is an open and interesting challenge.
If you find the concept interesting, and would like to help, there are (at least) two ways you can do it:
We run a labeling platform at
Where we ask people to help us rewrite statements or annotate solutions. We have paid out more than $10k in the last few months, and are launching three new tasks there today. The invitation code to register is NEAR.
You need to have sufficient written English skill to write statements that are understandable by English speakers to participate.
If you were solving problems on informatics.mccme.ru, and would be willing to share your account with me to crawl it, that would provide a lot of value. The website has great intro level problems, and presently we have no solutions for them.
We also look for accounts on Timus, SPOJ, acmp.ru and main.edu.pl / szkopul.edu.pl.
Всем привет,
Хотел в очередной раз порекламировать наш проект
Где мы платим за переписывание условий с тестирующих систем в короткий формальный вид (надо достатчно хорошо писать на техническом английском). Большинство людей кто участвует сегодня получают где-то между 10 и 12 долларами в час, что сегодня превращается где-то в 550-650 рублей.
Мы потом используем эти переписанные условия чтобы учить компьютеры решать задачки автоматически.
Ну и помимо этого есть еще один способ как вы можете помочь очень сильно с нашими исследованиями. Нам надо очень много решений на задачки с сайтов где решения не публичные. Если вы можете поделиться доступом к вашему акаунту на Timus, SPOJ, e-olymp, acmp.ru, COJ, или любом другом сайте где решения видны после авторизации, это поможет нам очень сильно с сбором данных.
К текущему моменту около 20 человек дали нам доступ к их акаунтам, за что им больше спасибо!
Всем привет,
Мы с друзьями пытаемся научить машины решать задачки самостоятельно.
Для этого нам нужен очень большой набор пар (условие задачи => решение).
Мы уже скраулили почти все сайты на которых решения публичны. Теперь мы пытаемся собрать решения с сайтов, где решения закрыты.
Если вы прорешивали Timus, UVa или любую другую платформу, где решения закрыты, и не против дать мне доступ скраулить ваши решения, пожалуйста пришлите в личку логины/пароли акаунтов в этих системах.
Мы нигде не будем публиковать код, и не будем использовать акаунты как-либо кроме как для того чтобы скачать решения.
И напоминаю, что мы поддерживаем платформу, на которой просим людей переписывать условия задач в коротком виде. Мы платим за это, многие участники получают около $12/час. Платформа находится по ссылке:
Для тех, кто готовится к ICPC и как следствие не может работать полный рабочий день это может быть очень удобно.
Does anyone know someone from TOJ?
Trying to get in touch with them, but the email on the website is no longer valid.
UPDATE: контест закончился, задачи доступны для дорешивания. Если вы участвовали, расскажите насколько юзабельный и отзывчивый интерфейс, и как все работало.
Всем привет!
Мы работаем над новой системой для соревнований по программированию JavaBlitz, и сегодня проводим beta round сразу после раунда на CS Academy.
Раунды на JavaBlitz занимают до двух с половиной часов и проходят по правилам ACM ICPC за тем исключением, что штраф за неверную попытку 4 минуты а не 20.
Решать задачт можно только на Java, а формат похож на TopCoder -- надо реализовать метод в классе, который принимает некоторые параметры и возвращает некоторое значение. Нет необходимости что-то читать или писать в файлы.
Раунд состоится сегодня, в 20:30 по Москве.
Длительность раунда 1 час 40 минут, будет предложено три задачи, ничего сложности D/E первого дивизиона на раунде не будет.
Ссылка на сайт: http://javablitz.com, помимо beta round там есть две простых задачки уже доступных чтобы поиграться с Ареной и посмотреть как она работает.
Вероятность что все сляжет сразу как начнется контест очень высокая, имейте ввиду если будете участвовать :)
Hi everyone,
Today we are going to show few demos of Sequence to Sequence models for code completion.
But before diving into details, we, as usual, want to ask you to participate in collecting data for the future models in our labeling platform here:
There are real money rewards associated with all the tasks in the platform.
In the first demo we trained a seq2seq model, more on which below, on all the Accepted java solutions on CodeForces. The goal of the model is to predict the next token based on all the tokens seen so far. We then plug the output of the model into a code editor (the arena on the video is an unfinished project I will write about separately) to see how it behaves when one actually solves a competitive programming problem. Here we are solving problem A from Codeforces Round 407:
Notice how early on the model nearly perfectly predicts all the tokens, which is not surprising, since most of the Java solutions begin with rather standard imports, and the solution class definition. Later it perfectly predicts the entire line that reads n, but doesn’t do that well predicting reading k, which is not surprising, since it is a rather rare name for the second variable to be read.
There are several interesting moments in the video. First, note how after int n = it predicts sc, understanding that n will probably be read from the scanner (and while not shown in the video, if the scanner name was in, the model would have properly predicted in after int n =), however when the line starts with int ans =, it then properly predicts 0, since ans is rarely read from the input.
The second interesting moment is what happens when we are printing the answer. At first when the line contains System.out.println(ans it predicts a semicolon (mistakenly) and the closing parenthesis as possible next tokens, but not - 1, however when we introduce the second parenthesis System.out.println((ans, it then properly predicts -1, closing parenthesis, and the division by two.
You can also notice a noticeable pause before the for loop is written. This is due to the fact that using such artificial intelligence suggestions completely turns off the natural intelligence the operator of the machine possesses :)
One concern with such autocomplete is that in the majority of cases most of the tokens are faster to type than to select from the list. To address it, in the second demo we introduce beam search that searches for the most likely sequences of tokens. Here’s what it looks like:
Here there are more rough edges, but notice how early on the model can correctly predict entire lines of code.
Currently we do not condition the predictions on the task. Partially because number of tasks available on the Internet is too small for a machine learning model to predict anything reasonable (so, please help us fix it by participating here: https://r-nn.com). Once we have a working model that is conditioned on the statement, we expect it to be able to predict variable names, snippets to read and write data and computing some basic logic.
Let’s review Seq2Seq models in the next section.
Sequence to Sequence (Seq2Seq for short) has been a ground-breaking architecture in Deep Learning. Originally published by Sutskever, Vinyals and Le, this family of models achieved state-of-the-art results in Machine Translation, Parsing, Summarization, Text to Speech and other applications.
Generally Seq2Seq is an extension of regular Recurrent Neural Networks (we have mentioned them before in http://codeforces.me/blog/entry/52305), where model first encodes input tokens and then tries to produce set of output tokens by decoding on token at a time.

For example on this picture the model is first fed three inputs A, B and C and then it is given <EOS> token to indicate that it should start predicting output sequence [W, X, Y, Z]. Here each token is represented as a continuous vector [embedding] that is learned jointly with parameters of the RNN model.
At training time, model is fed with correct output tokens shifted by one, so it can learn dependencies in the data. The signal comes from maximizing the log probability of a correct output given the source sequence.
Once training is complete this model can be used to produce most probable output sequences. Usually to search for most likely decodings a simple left-to-right beam search is applied. Beam search is a greedy algorithm of keeping a small number B of partial hypotheses to find the most likely decoding. At each step we extend these hypotheses by every possible token in the vocabulary and then discard all but B most likely hypotheses according to model’s probability. As soon as “” (End of Sequence) symbol is appended to hypothesis, it is removed from the beam and is added to a set of complete hypotheses.
The model that we use right now is not a seq2seq per se, since there’s no input sequence given to it, so it only consists of the decoder part of the seq2seq. After being trained on the entire set of CodeForces java solutions, it achieved 68% accuracy of predicting the next token correctly, and 86% of predicting it among top 5 predictions. If the first character of the token is already known, the prediction reaches 94%. It is unlikely that a vanilla seq2seq will achieve a performance sufficient to be usable in practice, but it establishes a good baseline to compare the future models against.
Hi, everyone,
As I mentioned in the last post, myself and a friend of mine got very interested in how close we can get machines to writing software, and whether modern advances in Deep Learning can help us build tools that considerably improve the way people write, review and debug code.
I want to start a series of posts discussing some interesting advances in using machine learning for both writing and executing code.
This particular post is about a machine learning model proposed early last year by Scott Reed from University of Michigan, then an intern at Google DeepMind, called Neural Programmer-Interpreters.
But before I go into the details, I would like to start with an ask. CodeForces and similar websites today host a vast amount of data that we would love to use to train our machine learning models. A particular challenge is that problem statements historically contain a lot of unnecessary information in an attempt to entertain competitors. Machine Learning models do not get entertained, but rather get very confused. We want to rewrite all the statements of all the problems available on the Internet in a very concise manner, so that a machine learning model has a chance of making sense of them. Thanks to people who volunteered after the last post, we now have more or less tested our labeling platform, and would like to invite everybody to help us create that dataset.
The platform is located here:
There's a monetary reward associated with labeling the solutions. Based on my own performance, and performance of those people who helped us with testing, after some practice it takes on average 2 to 4 minutes to write one short statement, which ends up paying around $6/hour. Something reasonable to consider for those who practice for upcoming competitions and don't have time for a full time job. On top of that, participating in the project is a great way to contribute to pushing science forward.
Now, back to the actual topic of the article.
Neural programmer-interpreter, or NPI for short, is a machine learning model that learns to execute programs given their execution traces. This is different from some other models, such as Neural Turing Machines, that learn to execute programs only given example input-output pairs.
Internally NPI is a recurrent neural network. If you are unfamiliar with recurrent neural networks, I highly recommend reading this article by Andrej Karpathy, that shows some very impressive results of very simple recurrent neural networks: The Unreasonable Effectiveness of Recurrent Neural Networks.
The setting in which NPI operates consists of an environment in which a certain task needs to be executed, and some low level operations that can be performed in such environment. For example, a setting might comprise:

Given an environment and low-level operations, one can define high level operations, similar to how we define methods in our programs. A high level operation is a sequence of both low-level and high level operations, where the choice of each operation depends on the state of the environment. While internally such high level operations might have branches and loops, those are not known to the NPI. NPI is only given the execution traces of the program. For example, consider a maze environment, in which a robot is trying to find an exit, and uses low-level operations LOOK_FORWARD, TURN_LEFT, TURN_RIGHT and GO_STRAIGHT. A high level operation make_step can be of a form:
has_wall = LOOK_FORWARD
if (has_wall)
with 50% chance: TURN_RIGHT
else: TURN_LEFT
else: GO_STRAIGHTIf NPI was then to learn another high level operation that just continuously calls to make_step, the data that is fed to it would be some arbitrary rollout of the execution, such as
make_step
LOOK_FORWARD
TURN_RIGHT
make_step
LOOK_FORWARD
GO_STRAIGHT
make_step
LOOK_FORWARD
GO_STRAIGHT
make_step
LOOK_FORWARD
TURN_LEFT
make_step
LOOK_FORWARD
GO_STRAIGHTIn other words, NPI knows what high level operations call to what low/high level operations, but doesn't know how those high level operations choose what to call in which setting. We want NPI by observing those execution traces to learn to execute programs in new unseen settings of the environment.
Importantly, we do not expect NPI to produce the original program that was used to generate execution traces with all the branches and loops. Rather, we want NPI to execute programs directly, but producing traces that have the same structure as the traces that were shown to NPI during training. For example, look at the far right block on the image above, where NPI emits high level operations for addition. It emits the same high level operations that the original program would have emitted, and then the same low level operations for each of them, but it is unknown how exactly it decides what operation to emit when, the actual program is not produced.
An NPI is a recurrent neural network. A recurrent neural network is a model that learns an approximation of a function that gets a sequence of varying length as an input, and produces a sequence of the same length as an output. In its simplest form a single step of a recurrent neural network is defined as a function:
def step(X, H):
Y_out = tanh(A1 * (X + H) + b1)
H_out = tanh(A2 * (X + H) + b2)
return Y_out, H_outHere X is the input at the corresponding timestep, and H is the value of H_out from the previous step. Before the first timestamp H is initialized to some default value, such as all zeros. Y_out is the value computed for the current time step. It is important to notice that Y at a particular step only depends on Xs up to that timestep, and that the function that computes Y is differentiable with respect to all As and bs, so those parameters can be learned with back propagation.
Such a simple recurrent neural network has many shortcomings, one most important one is that the gradient of Y with respect to parameters goes to zero very quickly as we go back across timestamps, and as such long term dependencies cannot be learned in any reasonable time. This problem is solved by more sophisticated step functions, two most widely used are LSTM (long-short term memory) and GRU (gated recurrent units). Importantly, while the actual way Y_out and H_out are computed in LSTMs and GRUs differ from the above step function, conceptually they are the same in the sense that they take the current X and the previous hidden state H as input, and produce Y and the new value of H as an output.
NPI, in particular, uses LSTM cells to avoid the vanishing gradient problem. The input to the NPI's LSTM at each timestamp is the observation of the environment (such as the full state of the grid with all the cursor positions for the addition problem), as well as some representation of the high level operation that is being executed. The output is either a low-level operation to be executed, a high-level operation to be executed, or an indication to stop. If it's a low-level operation, it is immediately executed in the environment, and the NPI moves to the next timestamp, feeding the new state of the environment as the input. If it's an indication to stop, the execution of the current high level operation is terminated.
If LSTM, however, has emitted a high level operation, the execution is more complex. First, NPI remembers the value of the hidden state H after the current timestamp was evaluated, let's call it h_last. Then a brand new LSTM is initialized, and is fed h_last as its initial value of H. This LSTM is then used to recursively execute the emitted high level operation. When the newly created LSTM finally terminates, its final hidden state value is discarded, the original LSTM is resumed again, and executes it's next timestamp, receiving h_last as the hidden state.
The overall architecture is shown in this picture:

When the NPI is trained, the emitted low-level or high-level operation is compared to that produced by the actual program to be learned, and if they do not match, the NPI is penalized. Whenever NPI fails to properly predict the operation to be executed during training, there's a question whether we should execute in the environment the correct operation from the actual execution trace we are feeding, or the operation that the NPI predicted. The motivation behind executing the correct operation is that if we feed predicted operations (which early on during training are mostly meaningless), the error in the environment accumulates, and the NPI has no chance of predicting consecutive operations correctly. The motivation behind feeding the predicted operations is that after the NPI is trained, during evaluation it will always be fed the predicted operations (since the correct ones are not known), and so feeding the correct ones during training makes the model to be trained in a setting that is different from the setting in which it will be evaluated. While there's a good technique that addresses this issue called Scheduled Sampling, NPI doesn't use it, and always executes the correct operation in the environment during training, disregarding the predicted one.
In the original paper the NPIs are tested on several toy tasks, including the addition described above, as well as a car rotation problem where the input to the neural network is an image of a car, and the network needs to bring it into a specific state via a sequence of rotate and shift operations:

With both toy tasks NPI achieves nearly perfect success rate. However, NPIs are rather impractical, since one needs the execution traces to train them, meaning that one needs to write the program himself before being able to learn it. Other models such as Neural Turing Machines are more interesting from this perspective, since they can be trained from input-output pairs, so one doesn't need to have an already working program. I will talk about Neural Turing Machines, and their more advanced version Neural Differentiable Computer, in one of the next posts in this series.
One of the problems with NPIs is that we can only measure the generalization by running the trained NPI on various environments and observing the results. We can't, however, prove that the trained NPI perfectly generalizes even if we observe 100% generalization on some sample environments.
For example, in the case of multidigit addition the NPI might internally learn to execute a loop and add corresponding digits, however over time a small error in its hidden state can accumulate and result in errors after many thousands of digits.
A new paper that was presented on ICLR 2017 called Making Neural Programming Architecture Generalize Via Recursion addresses this issue by replacing loops in the programs used to generate execution traces with recursion. Fundamentally nothing in the NPI architecture prevents one from using recursion -- during the execution of a high level operation A the LSTM can theoretically emit the same high level operation, or some other high level operation B that in turn emits A. In other words, the model used in the 2017 paper is identical to the model used in the original Scott Reed's paper, the difference is only in the programs used to generate the execution traces. Since in the new paper the execution traces are generated by programs that contain no loops, execution of any high level operation under perfect generalization should yield a bounded number of steps, which means that we can prove that the trained NPI has generalized perfectly by induction if we can show that it emits correct low level commands for all the base cases, and emits correct bounded sequences of high and low level commands for all possible states of relevant part of the environment.
For example, in the example of multidigit addition, it is sufficient to show that the NPI properly terminates when no more digits are available (the environment has no digits under cursors and CARRY is zero), and that the NPI correctly adds up two numbers and recurses to itself for any pair of digits under cursor and state of the CARRY. Authors of the paper show that for recursive addition algorithm an NPI trained only on examples up to five digits long provably generalizes for arbitrarily long numbers.
Hope it was interesting. In the next post I will switch from learning how to execute programs to learning how to write them, and will show a nice demo of a recurrent neural network that tries to predict next few tokens as the programmer writes a program.
Hi, everybody,
A friend of mine and myself are working on a pet project that is attempting to train neural networks that can make sense of code and assist people with writing, reviewing and debugging it.
While there's a lot of data available on the Internet, such as huge open source projects, or all the solutions on Codeforces, there's also a lot of data missing, such as good alignment of code and what it does. We would like to get help from the community in labeling some of the missing data.
We allocated a certain budget to make some annotations to all CodeForces problems, as well as problems from other platforms, and are seeking people who are interested in spending some time on completing competitive-programming-related tasks for small compensation.
At this stage we are testing the labeling platform, so we would like to find 5-10 people with decent English writing skills who can allocate 30-60 minutes on 3-4 evenings this week to label some data (it will already be paid). If you are interested to participate, DM me or send me an email at [email protected].
Hi, everybody,
Drew Paroski, one of the creators of HHVM (JIT for PHP), who's currently working on MemSQL query compiler, will be giving a talk on August 19th in San Francisco on how to write compilers in modern C++.
Since many people are currently on internships in the Silicon Valley, I figured the event might be interesting to many people here, especially those who do systems programming.
The link to the event:
The critical observation in this problem is that the points will be at the corners or very close to the corners. After that one simple solution would be to generate a set of all the points that are within 4 cells from some corner, and consider all quadruplets of points from that set.
When the magician reveals the card, he has 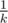 chance to reveal the same exact card that you have chosen. With the remaining
chance to reveal the same exact card that you have chosen. With the remaining 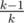 chance he will reveal some other card. Since all the cards in all m decks are equally likely to be in the n cards that he uses to perform the trick, he is equally likely to reveal any card among the n × m - 1 cards (-1 for the card that you have chosen, which we assume he has not revealed). There are only m - 1 cards that can be revealed that have the same value as the card you chose but are not the card you chose. Thus, the resulting probability is
chance he will reveal some other card. Since all the cards in all m decks are equally likely to be in the n cards that he uses to perform the trick, he is equally likely to reveal any card among the n × m - 1 cards (-1 for the card that you have chosen, which we assume he has not revealed). There are only m - 1 cards that can be revealed that have the same value as the card you chose but are not the card you chose. Thus, the resulting probability is 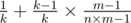
One way to solve this problem is to maintain three deques, one per machine type, each one containing moments of time when the machines of this type will be available in increasing order. Originally each deck has as many zeroes, as many machines of that type are available. For each piece of laundry, see the earliest moment of time when each of the three machines will be available, and chose the time to put it in a washer in such a way, that there will be no delay when you move it to the dryer and to the folder. Remove the first elements from each of the deques, and push back moments of time when the piece of laundry you are processing is washed, dried and folded correspondingly. It can be shown that by doing that you will maintain all the deques sorted.
This problem requires one to use one of the datastructures, such as suffix array, suffix tree or suffix automata. The easiest solution uses a compressed suffix tree. Build one suffix tree on all three strings. For simplicity add some non-alphabetic character at the end of each string. For every node in the tree store how many times the corresponding suffix occurs in each string. Then traverse the tree once. If the tree had no shortcuts, for every node that is a characters away from the root you would have increased the answer for a by the product of numbers of occurrences of the suffix in each of the strings. Since you do have shortcuts, you need to update the answer for all the lengths from a to b, where a and b are the distances of two ends of the shortcut from the root. One way to do it with constant time updates and linear time to print all the answers is the following. If the array of answers is v, then instead of computing v we can compute the array of differences p, such that pi = vi - vi - 1. This way when you traverse the shortcut, rather than adding some value at all the positions from a to b, you only need to add that value at position a, and subtract it at position b. When p is computed, it is easy to restore v in one pass.
There are at least two different ways to solve this problem
First way is to notice that almost all the permutations have such numbers a and b. Consider solving the opposite problem: given n, build a permutation such that no subsequence of length 3 forms an arithmetic progression. One way to do that is to solve similar problem recursively for odd and even elements and concatenate the answer, i.e. solve it for  , and then form the answer for n as all the elements of the solution for multiplied by two, followed by those elements multiplied by two minus one. This way we first place all the even numbers of the sequence, and then all the odd or vice versa.
, and then form the answer for n as all the elements of the solution for multiplied by two, followed by those elements multiplied by two minus one. This way we first place all the even numbers of the sequence, and then all the odd or vice versa.
Now one observation that can be made is that all the permutations that don’t have a subsequence of length 3 that is an arithmetic progression are similar, with may be several elements in the middle being mixed up. As a matter of fact, it can be proven that the farthest distance an odd number can have from the odd half (or even number can have from the even part) is 6. With this knowledge we can build simple divide and conquer solution. If n < = 20, use brute force solution, otherwise, if the first and the last elements have the same remainder after division by two, then the answer is YES, otherwise, assuming without loss of generality that the first element is odd, if the distance from the first even element to the last odd element is more than 12, then the answer is YES, otherwise one can just recursively check all the odd elements separately, all the even elements separately, and then consider triplets of numbers, where one number is either in the odd or even part, and two numbers are among the at most 12 elements in the middle. This solution works in nlog(n) time. Another approach, that does not rely on the observation above, is to consider elements one by one, from left to right, maintaining a bitmask of all the numbers we’ve seen so far. If the current element we are considering is a, then for every element a - k that we saw, if we didn’t see a + k (assuming both a - k and a + k are between 0 and n - 1), then the answer is YES. Note that a - k was seen and a + k was not seen for some k if and only if the bitmask is not a palindrome with a center at a. To verify if it is a palindrome or not one can use polynomial hashes, making the complexity to be n × log(n).
The important observation one needs to make is that qn = qn - 1 + qn - 2, which means that we can replace two consecutive ‘1’ digits with one higher significance digit without changing the value. Note that sometimes the next digit may become more than ‘1’, but that doesn’t affect the solution.
There are two different kinds of solutions for this problem
The first kind of solution involves normalizing both numbers first. The normalization itself can be done in two ways — from the least significant digit or from the highest significant one using the replacement operation mentioned above. In either we will need O(n) operations for each number and we then just need to compare them lexicographically.
Other kind of solutions compare numbers digit by digit. We can start from the highest digit of the numbers, and propagate them to the lower digits. On each step we can do the following:
If both numbers have ones in the highest bit, then we can replace both ones with zeroes, and move on to the next highest bit.
Now only one number has one in the highest bit. Without loss of generality let’s say it’s the first number. We subtract one from the highest bit, and add it to the next two highest bits. Now the next two bits of the first number are at least as big as the first two bits of the second number. Let’s subtract the values of these two bits of the second number from both first and second number. By doing so we will make the next two bits of the second numbers become 0. If first number has at least one two, then it is most certainly bigger (because the sum of all the qi for i from 0 to n is smaller than twice qn + 1). Otherwise we still have only $0$s and $1$s, and can move on to the next highest bit, back to step (1). Since the ordinal of the highest bit is now smaller, and we only spent constant amount of time, the complexity of the algorithm is linear.
One of the optimal strategies in this problem is to locate a node a with the most rows, then move all the data from the cluster a does not belong to onto a, and then for every other node b in the cluster that a belongs to either move all the data from b onto a, or move all the rows from the other cluster into b, whichever is cheaper.
First let’s consider a subproblem in which we know how many votes we will have at the end, and we want to figure out how much money we will spend. To solve this problem, one first needs to buy the cheapest votes from all the candidates who have as many or more votes. If after that we still don’t have enough votes, we buy the cheapest votes overall from the remaining pool of votes until we have enough votes. Both can be done in linear time, if we maintain proper sorted lists of votes. This approach itself leads to an O(n2) solution. There are two ways of improving it. One is to come up with a way of computing the answer for k + 1 votes based on the answer for k votes. If for each number of votes we have a list of candidates, who have at least that many votes, and we also maintain a set of all the votes that are available for sale, then to move from k to k + 1 we first need to return the k-th most expensive vote for each candidate that has at least k votes (we had to buy them before, but now we do not have to anymore) back into the pool, and then get that many plus one votes from the pool (that many to cover votes we just returned, plus one because now we need k + 1 votes, not k). This solution has nlogn complexity, if we use a priority queue to maintain the pool of the cheapest votes. In fact, with certain tweaks one can reduce the complexity of moving from k to k + 1 to amortized constant, but the overall complexity will not improve, since one still needs to sort all the candidates at the beginning.
Another approach is to notice that the answer for the problem first strictly decreases with the number of votes we want to buy, and then strictly increases, so one can use ternary search to find the number of votes that minimizes the cost.
The score function of a board in the problem is 2x, where x is number of rows and columns fully covered. Since 2x is the number of all the subsets of a set of size x (including both a full set and an empty set), the score function is essentially the number of ways to select a set of fully covered rows and columns on the board. The problem reduces to computing the expected number of such sets. For a given set of rows R and a given set of columns C we define pR, C as a probability that those rows and columns are fully covered. Then the answer is 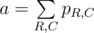 . For two sets of rows of the same size r and two sets of columns of the same size c the value of pR, C will be the same, let’s call it qr, c. With that observation the answer can be computed as
. For two sets of rows of the same size r and two sets of columns of the same size c the value of pR, C will be the same, let’s call it qr, c. With that observation the answer can be computed as 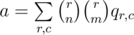 . qr, c in turn is just the probability that n(r + c) - rc numbers on the board are chosen from the k numbers that were called, and the remaining (n - c)(n - r) numbers on the board are chosen from the remaining m - (n(r + c) - rc) numbers available.
. qr, c in turn is just the probability that n(r + c) - rc numbers on the board are chosen from the k numbers that were called, and the remaining (n - c)(n - r) numbers on the board are chosen from the remaining m - (n(r + c) - rc) numbers available.
Let’s begin by considering an arbitrary cycle in the given graph (if one exists). We could add some amount of flow to each edge in the cycle, and doing so must result in an equivalent or worse cost (otherwise the intern’s solution would clearly be non-optimal). Thus if we consider the function c(x) = sum(w_i * (f_i + x)^2), it should be minimized at x=0. Since this function is continuous, a necessary condition is c’(0) = 0. This implies sum(w_i * f_i) = 0 for any cycle.
Let us denote w_i * f_i as the “potential” of an edge. We can define the potential between two vertices in the same connected component as the sum of the potentials of the edges along any path between them. If the potential is not well defined, then the intern’s solution is not optimal. Additionally, the potential from node 1 to any other node must be positive (It cannot be zero because the original graph is biconnected), and similarly the potential from any node to node N must be positive. Furthermore no potential can exceed or equal the potential between node 1 and node N (if they are connected). These conditions can be verified in linear time using a dfs, allowing us to binary search the answer in O(N log N). Alternatively, the union-find algorithm can be modified to track potentials as well as components.
The true nature of the problem is revealed by making the following replacements:
weight -> resistance
bandwidth -> current
cost -> power
potential -> voltage
The problem asks you to determine if the given currents in a resistor network are optimal.
The solution for this problem is a dynamic programming on a tree with O(n) complexity.
In this editorial “even tree” means a tree in which players will make an even number of turns, while “odd tree” is the tree in which players will make an odd number of turns.
We will be solving a slightly modified problem: one in which all the numbers on the leaves are $0$s and $1$s. Once this problem is solved, the general problem can be solved by doing a binary search on the answer, and then marking all the leaves with higher or equal value as $1$s, and all other values as $0$s.
If the tree is an odd tree, then the first player makes the last turn, and it is enough that at that moment only one of the two children of the root is 1. If the tree is an even tree, then the second player makes the last turn, so for the first player it is critical that by that time both children of the tree are 1 if he wants to win.
One simple case is the case when the tree is an odd tree, and both its immediate subtrees are even trees (by an immediate subtree, or just “subtree‘ of a node, here we will mean a subtree rooted at one of the nodes' immediate children).
In this case we can recursively solve each of the immediate subtrees, and if the first player wins any of them, he wins the entire tree. He does that by making his first turn into the tree that he can win, and then every time the second player makes a turn in that tree, responding with a corresponding optimal move, and every time the second player makes a turn in the other tree, making a random move there.
If both immediate subtrees are odd trees, however, a similar logic will not work. If the second player sees that the first player can win one of the trees, and the first player already made a turn in that tree, the second player can force the first player to play in the other tree, in which the second player will make the last turn, after which the first player will be forced to make a turn in the first tree, effectively making himself do two consecutive turns there. So to win the game the first player needs to be able to win a tree even if the second player has an option to skip one turn.
So we will need a second dimension to the dynamic programming solution that will indicate whether one of the players can skip one turn or not (we call the two states “canskip” if one can skip a turn and “noskip‘ if such an option does not exist). It can be easily shown, that we don’t need to store how many turns can be skipped, since if two turns can be skipped, and it benefits one player to skip a turn, another player will immediately use another skip, effectively making skips useless.
To make the terminology easier, we will use a term “we” to describe the first player, and “he” to describe the second player. “we can win a subtree” means that we can win it, if we go first there, “he can win a subtree” means that he can win it if he goes first (so “if one goes first” is always assumed and omitted). If we want to say that “we can win going second”, we will instead say “he cannot win [going first]” or “he loses [going first]”, which has the same meaning
Now we need to consider six cases (three possible parities of children multiplied by whether one can skip a turn or not). In all cases we assume that both children have at least two turns in them left. Cases when a child has no turns left (it is a leaf node), or when it has only one turn left (it is a node whose both children are leaves) are both corner cases and need to be handled separately. It is also important to note, that when one starts handling those corner cases, he will encounter an extra state, when the players have to skip a turn, even if it is not beneficial for whomever will be forced to do that. We call such state “forceskip”. In the case when both subtrees have more than one turn left, forceskip and canskip are the same, since players can always agree to play in such a way, that the skip, if available, is used, without changing the outcome. Below we only describe canskip and noskip cases, in terms of transitions from canskip and noskip states. One will need, however, to introduce forceskip state when he handles corner cases, which we do not describe in this editorial. The answer for forceskip will be the same as the answer for skip in general case, but different for corner cases.
even-even-noskip: the easiest case, described above, it is enough if we win any of the subtrees with no skip.
even-even-canskip: this case is similar to a case when there’s one odd subtree and one even subtree, and there’s no skip (the skip can be just considered as an extra turn attached to one of the trees), so the transition is similar to the one for odd-even-noskip case described below. We win iff we can win one tree with canskip, and he cannot win the other with noskip.
odd-even-noskip: if we can win the odd tree without a skip, and he cannot win the even tree without a skip, then we make a turn into the odd tree, and bring it into the even-even-noskip case, where he loses both trees, so we win. The other, less trivial, condition under which we win is If we can win the even tree with canskip, and he can’t win the odd tree with canskip. A motivation for this case is that odd subtree with a skip is similar to an even subtree, so by making a turn into the even case, we bring our opponent to an odd-odd case, where he loses both threes with a skip, which means that no matter which tree he makes a turn into, we will be responding to that tree, and even if he uses another tree to make a skip, he will still lose the tree into which he made his first turn. Since we make the last move, we win.
odd-even-skip: this is a simple case. We can consider the skip as an extra turn in the odd subtree, so as long as we can win even subtree with no skip, or odd subtree with a skip, we win.
odd-odd-noskip: we need to win either of the subtrees with a skip to win.
odd-odd-skip: to handle this case we can first consider immediately skipping: if he loses noskip case for the current subtree, then we win. Otherwise we win iff we can win one of trees with a skip, and he can’t win the other without a skip.
The more detailed motivation for each of the cases is left as an exercise.
Всем привет!
Второй раунд соревнования MemSQL Start[c]UP 2.0 состоится уже сегодня, 10-ого Августа в 21:00 MSK. Одновременно будет два контеста: для тех, кто участвует онсайт, и для тех, кто участвует онлайн. Набор задач в двух контестах будет одинаковый, и за них будет начислен рейтинг на основе общего монитора.
Участники, участвующие в онсайт раунде, получат специальные призы за первые три места. Все участники онсайт раунда и топ 100 участников из онлайн раунда получат специальные футболки start[c]up.
Участники, не прошедшие во второй раунд, могут участвовать неофициально. При этом раунд будет рейтинговым для таких участников.
На соревновании будет предложено шесть задач, длительность соревнования -- три часа. Распределение баллов 1000-1000-1500-2000-2500-3000.
Удачи и отличного кодинга!
UPDATE: результаты будут опубликованы позже
MemSQL с радостью сообщает о проведении второго ежегодного соревнования по программированию Start[c]UP 2.0. Start[c]UP 2.0 проводится на платформе Codeforces и состоит из двух раундов.
Раунд 1 состоится онлайн 27 июля в 21:00 мск и будет проведен по стандартным правилам Codeforces. На нем будет представлено пять задач, сложность которых сопоставима со средним раундом на Codeforces, раунд является рейтинговым и длится 2.5 часа. Для участия в первом раунде допускаются все желающие.
Раунд 2 состоится одновременно онлайн и онсайт 10 августа в 21:00 мск и будет проведен по стандартным правилам Codeforces. Будет представлено шесть задач, сложность которых, по нашей оценке, превосходит средний раунд на Codeforces. Раунд является рейтинговым и длится 3 часа. Во втором раунде могут участвовать только участники, занявшие первые 500 мест в первом раунде. Лучшие 100 участников второго раунда получат футболки Start[c]UP 2.0.
Для тех из вас, кто находится географически в Кремниевой Долине, мы пригласим 25 лучших участников по итогам первого раунда на онсайт версию второго раунда. Победитель онсайт раунда получит специальный приз.
UPDATE: в первом раунде будет предложено шесть задач, а не пять, как было объявлено ранее
Тут давече прошел пятый CodeSprint. Интересно, как решается вот эта задача: https://www.hackerrank.com/contests/codesprint5/challenges/hacker-country
Стандартное для похожих задач решение с бинпоиском и флойдом ожидаемо ловило таймлимит на половине тестов. Я вижу что кто-то его втолкал ища отрицательный циклы дийкстрой (О.о) вместо флойда, но интересно правильное решение.
Всем привет!
Второй раунд соревнования MemSQL start[c]up состоится 3-его Августа в 21:00 MSK. Одновременно будет два контеста: для тех, кто участвует онсайт, и для тех, кто участвует онлайн. Набор задач в двух контестах будет одинаковый, и за них будет начислен рейтинг на основе общего монитора.
Участники, участвующие в онсайт раунде, получат специальные призы за первые три места. Все участники онсайт раунда и топ 100 участников из онлайн раунда получат специальные футболки start[c]up.
Участники, не прошедшие во второй раунд, могут участвовать неофициально. При этом раунд будет рейтинговым для таких участников.
На соревновании будет предложено шесть задач, длительность соревнования -- три часа. Распределение баллов 500-1000-1000-2000-2500-3000.
Задачи приготовлены разработчиками MemSQL pieguy, nika, exod40, SkidanovAlex и dolphinigle.
Удачи и отличного кодинга!
UPDATE: Опубликован разбор задач (на английском)
Автор: AlexSkidanov
Если несколько прямоугольников образуют квадрат N × N, то следующие два условия обязательно выплняются:
1) Суммарная площадь прямоугольников равна N × N.
2) Разница между правой границей самого правого прямоугольника и левой границей самого левого прямоугольника ровно N. Аналогично для нижней и верхней границы.
Легко показать, что эти условия являются также и достаточными.
Автор: nika
Пусть прошло D раундов на выбывание, и круговой раунд с M командами.
Тогда общее количество сыгранных игр: 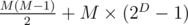
Мы хотим, чтобы 
Это уравнение с двумя неизвестными, чтобы его решить, можно зафиксировать значение одной из них, и найти значение другой. Мы не можем перебрать все значения для M, так как M может достигать 10^9. Однако, мы можем перебрать все значения D, так как количество игр растет экспоненциально с ростом D -- поэтому D может принять значения только в интервале 0 ≤ D ≤ 62.
Когда D зафиксировано, остается решить следующее уравнение: 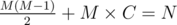
Так как левая часть уравнения возрастает, M можно найти двоичным поиском.
Автор: AlexSkidanov
Первая часть задачи -- найти минимум для каждого монстра. Чтобы это сделать, мы будем использовать алгоритм Дейкстры. Изначально минимум не известен ни для одного монстра. Для каждого превращения будем поддерживать величину, указывающую на количество монстров, которые это превращение создает, для которых минимум еще не известен (назовем его ki для i-ого превращения). Сначала рассмотрим каждое превращение, которое создает только бриллианты (то есть для которого ki = 0), и скажем, что это количество бриллиантов -- это временный минимум для монстра, которому принадлежит превращение (если у монстра есть более одного превращения в бриллианты, надо взять то, которое создает минимальное количество бриллиантов). Затем возьмем монстра с минимальным временным минимумом. Для этого монстра временный минимум является финальным минимумом. Это можно доказать используя подход, похожий на подход к доказательству алгоритма Дейкстры. Так как для этого монстра минимум известен, уменьшим ki для каждого превращения, которое производит этого монстра. Если для какого-то превращения ki стало равно нулю, обновим временный минимум для монстра, которому принадлежит это преврещение суммой минимумов по всем монстрам, которых это превращение производит, и количества бриллиантов, которые это превращение производит. Затем, среди всех монстров, для которых финальный минимум еще не известен, но известен временный, выберем того, для которого временный минимум минимален, и повторим процесс.
Когда монстров, для которых есть временный минимум, но нет финального, не осталось, все монстры, для которых минимум не нашелся, будут иметь - 1 - 1 в качестве ответа. Для остальных монстров мы знаем минимум, но не знаем максимум.
Вторая часть решения -- избавиться от превращений, выполнив которые мы никогда не сможем избавиться от всех монстров. Легко показать, что такими превращениями являются те, в результате которых появляется хотя бы один монстр, для которого минимум равен - 1. Уберем все такие превращения из набора превращений.
После этого найти максимумы очень легко. Начиная из каждого монстра, для которого максимум еще не известен, будем обходить монстров обходом в глубину. Для данного монстра, рассмотрим все превращения. Для конкретного превращения, для каждого монстра, который появляется в результате этого превращения, вызовем DFS чтобы найти максимум для этого монстра, просуммируем эти величины, прибавим количество бриллиантов, которые это превращение создает, и улучшим известный максимум для монстра, которому принадлежит это правило, полученной величиной. Если мы в какой-то момент времени попадаем в ситуацию, когда DFS вызван для монстра, для которого уже есть вызов DFS на стеке, это значит, что этот монстр может превратиться сам в себя (непосредственно или через других монстров) и ненулевое количество бриллиантов (по этой причине в условии оговаривается, что каждое превращение генерирует хотя бы один бриллиант), поэтому ответ для такого монстра -2. Если, обрабатывая одно из превращений, мы обнаружили, что в результате применения превращения появится монстр, для которого максимум равен -2, мы можем сразу назначить максимум для текущего монстра в -2 и выйти из DFS.
В качестве упражнения подумайте, как решить эту же задачу, если не гарантируется, что каждое превращение содержит хотя бы один бриллиант.
Автор: dolphinigle
Для простоты допустим, что над самой первой строкой и под самой последней строкой есть по дополнительной строке с морем.
Раздвоим поверхность цилиндра, добавив его справа к самому себе (при этом левый столбец раздвоенного моря по прежднему смежен с правым столбцом). Каждое превращение будем осуществлять в обеих половинах. Утверждается, что торгового маршрута не существует тогда и только тогда, когда для некоторой превращенной ячейки она достижима из своей копии по превращенным ячейкам (две превращенных ячейки смежны, если у них есть хотя бы одна общая точка, не обязательно общая сторона).
Доказать тот факт, что это услвоие достаточно, очень легко. Путь между ячейкой и ее копией разбивает море на северную и южную часть, и представляет из себя барьер между этими половинами, который ни один торговый маршрут не может пересечь.
Докажем необходимость условия. Пусть ни для какой превращенной ячейки ее копия не достижима по превращенным ячейкам. Тогда возьмем все ячейки, содержащие море, прилегающие к верхней границе, и найдем все достижимые из них ячейки с морем (две ячейки с морем смежны, если у них есть общая сторона). Пусть ни одна ячейка с морем, достижимая таким образом, не прилегает к нижней границе. Тогда возьмем самую нижнюю достижимую ячейку с морем (любую если их несколько), и начнем двигаться вправо вдоль морских ячеек, по превращенным ячейкам. Легко показать, что двигаясь по превращенным ячейкам, имеющим хотя бы одну общую точку, вдоль границы моря, мы опишем круг вокруг цилиндра и вернемся в ячейку, с который мы начали, что противоречит тому, что ни для какой превращенной ячейки ее копия не достижима из нее.
Дальше будем решать задачу моделируя запросы. Будем поддерживать компоненты связности превращенных ячеек используя систему непересекающихся множеств. Каждый раз, когда ячейка превращается, убедимся, что эта ячейка и ее копия не содержат соседей, принадлежащих одной компоненте связности. Если такие соседи есть, то после превращение этой ячейки, она и ее копия окажутся в одной компоненте связности, тем самым не оставив ни одного торгового маршрута. Если таких соседей нет, то превращаем ячейку, и объединяем все компоненты связности, прилегающие к ней, затем превращаем копию ячейки, и объединяем все компоненты связности, прилегающие к ней.
В этой задаче стоит отдельно рассмотреть случай, когда столбец только один (тогда ни одно превращение нельзя осуществить), и когда столбцов два (тогда у каждой ячейки только 5 соседей, а не восемь, что может привести к ошибкам в некоторых реализациях).
Автор: nika
В этом разборе все числа подрузмеваются по модулю N. Если в разборе встречается число 10, имеется ввиду 10 по модулю N.
В задаче нас просят найти гамильтонов цикл в графе. Для каждой вершины гамильтонова цикла через bef(X) будем обозначать предыдущую вершину в цикле а через aft(X) -- следующую.
Сначала покажем, что ответ -1 для любого нечетного N.
Рассмотрим вершину 0. Для любой вершины H, ведущей в 0, выполняются два условия:
2H = 0
2H + 1 = 0
Первому условию удовлетворяет только H = 0. Второму условию удовлетворяет только floor(N / 2).
Иными словами, pre[0] = floor(N/2), и aft[floor(N/2)] = 0
Теперь рассмотрим вершину N - 1. В нее ведут вершины, для которых верно
2H = N - 1
2H + 1 = N - 1
Второе условие выполняется только при H = N - 1. Первое условие выполняется только при H = floor(N / 2)
Иными словами, aft[floor(N/2)] равен N - 1. Это противоречит тому, что aft[floor(N/2)] должен быть 0.
Тем самым доказано, что N четно. Этот случай намного интереснее.
Рассмотрим вершину X. Из нее есть ребра в 2X и 2X + 1. Рассмотрим вершину X + N / 2. Из нее есть ребра в.... 2X + N и 2X + 1 + N. ...что по модулю N равно 2X и 2X + 1.
Значит, для вершин X и X + N / 2 множество исходящий ребер идентично.
Легко показать, что для каждой вершины X есть ровно два входящий ребра. Это следует из того, что в вершину X ребра идут только из вершин таких, что
2H = X
2H + 1 = X
по модулю N, и каждое из этих уравнений имеет ровно одно решение.
Факт, что каждая вершина имеет ровно два входящий ребра, вместе с фактом что X и X + N / 2 имеют одинаковое множество исходящий ребер, дает нам понять, что в вершины 2X и 2X + 1 есть ребра только из X и X + N / 2.
Иными словами, если мы решили взять ребро из X в 2X в гамильтонов цикл, мы обязаны взять ребро из X + N / 2 в 2X + 1 в цикл тоже (и наоборот).
Теперь, следуя правилу выше, для вершин X, X + N / 2 возьмем любые два из четырех ребер в 2X, 2X + 1. В итоге мы возьмем ровно N ребер, которые образуют некоторое количество простых циклов. Можем ли мы легко объединить? Оказывается, что в силу особенностей этих циклов, мы можем это сделать.
Утверждение: если есть два или более цикла, то есть вершина X такая, что X и X + N / 2 принадлежат разным циклам.
Доказательство: Пусть это не так. Покажем, что в этом случае есть только один цикл. Так как вершины X и X + N / 2 принадлежат одному циклу, они должны быть в одном цикле с 2X и 2X + 1. Так как X и 2X и 2X + 1 все принадлежат одному циклу, легко показать, что из любой вершины X можно попасть в любую другую вершину Y (доказательство этого остается в качестве упражнения). Теперь, расммотрим X такое, что X и X + N / 2 принадлежат разным циклам. Пусть из вершины X сейчас выбрано ребро в 2X + A, а из вершины X + N / 2 -- в 2X + B (A + B = 1). Поменяем их местрами -- пойдем из X в 2X + B и из X + N / 2 в 2X + A. Это соединит два цикла в один -- идея очень похожа на идею построения эйлерова цикла. После каждой такой операции количество циклов уменьшается на один, и в итоге останется только один цикл.
Осталось понять, как это сделать за O(N). Примером решения может быть DFS из вершины 0. Для каждой вершины X:
если мы в ней уже были, возвращаемся из DFS
если X + N / 2 была посещена, идем либо в 2X либо в 2X + 1 рекурсивно, в зависимсти от того, куда сейчас ведет ребро, выбранное для X + N / 2 (пойдем в вершину, в которую то ребро не ведет)
иначе, идем рекурсивно в 2X. Затем проверяем, смогли ли мы посетить в рекурсии X + N / 2. Если нет, значит они принадлежат разным циклам. Соединим их, и рекурсивно спустимся в 2X + 1.
Всем привет!
Первый раунд start[c]up начнется совсем скоро. Участвовать могут все желающие, никакой дополнительной регистрации, кроме регистрации на сам раунд, не требуется. Регистрация закрывается за пять минут до начала раунда.
Раунд пройдет по правилам codeforces и будет рейтинговым. Распределение баллов будет следующее: 500-1000-2000-2000-2500.
Задачи приготовлены разработчиками MemSQL pieguy, nika, exod40, SkidanovAlex и dolphinigle.
Лучшие 500 участников пройдут во второй раунд, а 25 лучших участников из Кремниевой Долины будут приглашены участвовать во втором раунде онсайт, где будут разыгрываться специальные призы.
Удачи на раунде и приятного кодинга!
UPDATE: Обратите внимание, что распределение баллов изменилось
UPDATE: Опубликован разбор задач!
MemSQL с радостью сообщает о проведении start[c]up -- соревнования по программированию, проводимого на Codeforces. Start[c]up состоит из двух раундов.
Оба раунда подготовлены программистами MemSQL: pieguy, nika, exod40, SkidanovAlex и dolphinigle.
Раунд 1 состоится онлайн 13 июля и будет проведен по стандартным правилам Codeforces. На нем будет представлено пять задач, сложность которых сопоставима со средним раундом на Codeforces. Для участия в первом раунде допускаются все желающие.
Раунд 2 состоится одновременно онлайн и онсайт 3 августа и будет проведен по стандартным правилам Codeforces. Будет представлено пять задач, сложность которых, по нашей оценке, превосходит средний раунд на Codeforces. Во втором раунде могут участвовать только участники, занявшие первые 500 мест в первом раунде. Лучшие 100 участников второго раунда получат футболки start[c]up.
Для тех из вас, кто находится географически в Кремниевой Долине, мы пригласим 25 лучших участников по итогам первого раунда на онсайт версию второго раунда. Победитель онсайт раунда получит специальный приз.
Больше информации о нас под катом
Сегодня я хочу рассказать про Хакатоны – интересный вид соревнований по программированию, который заметно отличается от всего, к чему привыкли люди, которые занимаются спортивным программированием. Хакатоны весьма популярны во всем мире, они проходят с какой-то периодичностью и в России, и на Украине, а в кремниевой долине их особенно много. За последние полтора месяца я поучаствовал в четырех хакатонах, и остался невероятно впечатлен.
Хакатон в Nokia
Самый первый хакатон, в котором мне довелось поучаствовать, проводился компанией Nokia, и целью хакатона, как можно догадаться, было разработать приложение для Windows Phone 7. Длительность “coding phase” была восемь часов, и разрешалось приходить с готовыми наработками. У нас готовых наработок не было, так что вся подготовка заключалась в том, чтобы найти два ноутбука с Windows, и поставить на них Windows Phone 7 SDK. Так как это был наш первый хакатон, мы не знали, чего ожидать. Мы приготовили идею – мы хотели написать приложение, связывающее два телефона, и дающее им канву, на которой они оба могут рисовать. Идея не очень сложная, и не очень новая – она, например, реализована в Pair. На хакатон я пришел с супругой, которая у меня тоже программист. Ни я ни она из-за рода работы не работали на Windows к тому дню уже порядка года, поэтому рабочая станция была немного непривычной. Для начала мы открыли документацию “пишем Hello World для WP7”, которая описывала, как создать простейшее приложение для WP7. Так как технологии развиваются с невероятной скоростью, простейшее приложение – это не приложение с текстом Hello World посередине, а web-браузер. Пройдя каждый пункт документации у нас получилось приложение с компонентой WebBrowser на весь экран. Это подтолкнуло нас к идее, что все приложение можно написать на HTML5 Canvas, и затем просто воткнуть его в эту самую компоненту. Мы в конечном итоге так и сделали. Через четыре часа приложение было уже написано, и мы рисовали на общей канве с двух компьютеров. Сервер мы быстренько подняли на EC2, и написали на PHP – буквально два 10-строчных скрипта. Порадовавшись тому, что за четыре часа до конца у нас все работает, мы решили проверить все на эмуляторе телефона. Указали WebBrowser компненте загружать страницу на EC2, запустили приложение, начали рисовать пальцем, и… а тут все стало не совсем радужно. Когда на WP7 нажимаешь пальцем и начинаешь его двигать, он прокручивает страницу, и ни Mouse Down, ни Mouse Move события на странице не вызываются вообще. Существующие специально для этой цели Touch Start и Touch Move события на WP7 не поддерживаются тоже. Я нашел вопрос на Stack Overflow, где спрашивали, можно ли отключить прокрутку страницы в WP7, с ответом “мой знакомый работает в WP7, и ответ – нет”. Тут-то мы и поняли, что четыре часа стараний ушли в унитаз, потому что запустить наш HTML5 код на WP7 попросту нельзя. Но, конечно, мы были далеко не первыми людьми, столкнувшимися с этой проблемой, и в мире есть много энтузиастов, которые так просто не сдаются. Порыскав поглубже в интернете я нашел двух ребят, которые через Reflection смогли найти во внутренностях WebBrowser часть, отвечающую за прокрутку, и собрали пример того, как ее оттуда можно выпилить. Я вошлебной силой копипаста реализовал такую же функцинальность у себя, перезапустил проект, повел пальцем, и никакой прокрутки не произошло. Это уже половина победы. К сожалению, как и ожидалось, отключение прокрутки не повлекло за собой срабатывание MouseMove или MouseDown – их, похоже, в WP7 в браузере нет как таковых. Но это решалось уже совсем просто – мы просто поставили обработчики на OnMouseMove и OnMouseDown в C# прямо на сам компонент WebBrowser, и в этих обработчиках вызывали события на HTML странице. Приложение заработало, мы его отполировали, и были готовы к презентации. На презентации мы сделали самое главное открытие о хакатонах, которое затем закрепили на каждом последующем из них: 95% всех презентаций – это шлак. Люди пишут календари, приложения для заметок, аггрегаторы социальных сетей и прочие двухколесные транспортные средства, и в среднем, не зависимо от количества команд, только 3-6 презентаций действительно интересны. На первом хакатоне мы не попали в топ3, но так как не ужасных приложений было всего 6, Nokia вручила 6 телефонов, так что мы с Машей унесли свеженький не залоченный Lumia 900 – очень недурной девайс.
AT&T Mobile hackathon -- Education
Через две недели после хакатона от Nokia мы пошли на значительно более масштабный хакатон от AT&T, посвященный проблемам образования. На нем мы узнали вторую интересную особенность хакатонов – люди относятся к ним очень серьезно. На вступительном слове организаторы сказали, что поводом для этого хакатона стало то, что в Америке 40% студентов не заканчивают университет. Затем люди представляли свои идеи, чтобы собрать команды. На этом хакатоне готовый код приносить было нельзя, и собрать команду было важно. Почти каждый второй человек рассказывал, как его беспокоит такая большая цифра, как 40%, и как его приложение поможет ее уменьшить. Правда, в основном это звучало как: “проблема заключается в том, что у студентов нет удобного календаря в телефоне”, или “у студентов нет удобных средств для заметок”. В общем теория о 95% проявила себя еще на стадии озвучивания идей. Было и несколько хороших серьезных идей – в основном высказанных учителями, а не программистами. Забегая в перед следует отметить, что выигравшая команда была как раз одной из тех, которые собрала учительница, а не программист. Еще до Хакатона решив, что писать надо для таблеток, мы одолжили у Ники c работы его iPad, который после прошлогоднего Russian Code Cup есть у каждого уважающего себя программиста (у меня нету). Наша идея была написать онлайн игру с математическими головоломками. Я ее озвучил, и к нам присоединились двое ребят из Cisco, которым она понравилась. Coding Phase был опять 8 часов. Пока ребята писали паззлы, я писал красивые эффекты на HTML5 Canvas и CSS3, чтобы игра выглядела презентабельно. Как раз когда я собрал небольшую демку с эффектами, к нам подошел парнишка из BlackBerry, и спросил над чем мы работаем. Я показал ему демку, и он предложил нам презентовать это дело не на iPad, а на PlayBook. Он дал нам PlayBook для презентации, и пообещал, что если мы что-то выиграем, он подарит каждому члену команды по Playbook. Поддержка HTML5 и CSS3 на Playbook была более чем достаточная, и моя демка отлично запустилась на нем. К тому времени ребята уже подготовили паззлы, и мы начали собирать все это дело в игру. Сервер опять развернули на AWS, с двумя 10-ти строчными PHP скриптами. За пол часа до конца Coding Phase мы смогли запустить первую рабочую версию игры, и поиграть с двух таблетов друг против друга. На PlayBook анимация немного тормозила, на iPad летала, поэтому мы решили для презенации только упомянуть, что второй игрок играет с PlayBook, но под камеру поставить все-таки iPad. Презентация прошла красиво. Перед награждением к нам подошел один из судей, и сказал, что хотя наше приложение и было технически заметно лучше многих других, в топ3 оно не может попасть, потому что оно не помогает решить проблему с 40% студентов, выпаюащих из колледжа. А так как правило 95% никто не отменял, на третьем месте оказалось приложение, которое просто показывает демотивирующие картинки, которые описывают судьбу человека без высшего образования. Мы же получили первый приз от AWS, так как Amazon спонсировал соревнование, в размере $1500 на AWS аккаунте, и, как следствие, по PlayBook на человека. Нам с Машей два PlayBook были ни к чему, так что она вместо своего взяла себе BlackBerry Bold 9900.
AngelHack
Парнишка из PlayBook оказался Larry McDonough, и предложил нам на следующем Хакатоне выступать от BlackBerry. За один только факт выступления BB платит по $500 на участника, и дает кофточки, кепочки и сумочки. За победу на хакатоне там цифры повыше, но победы не произошло, так что они не важны :о) Следующим Хакатоном, через две недели после AT&T, был AngelHack. Это огромный хакатон, с невероятным количеством участников. Coding Phase длится 24 часа, по итогам которых команда должна засабмитить 90 секундное видео с презентацией своего продукта. Из них выбирается 30 лучших, и они выступают с презентациями перед инвесторами, которые готовы вложить $25000 сразу на месте – это первый приз на соревновании. На этом Хакатоне мы выступали вдвоем c Машей, и писали игру, позволяющую выбрать друга на Facebook и намылить ему морду в игре, похожей на Mortal Combat. В этот раз мы хостились на Windows Azure, потому что они спонсировали соревнование, и я не могу не отметить, что Azure неплохо подрос со своим недавним релизом – если вам нужен PHP + MySQL (Python, Java, NodeJS) сайт, вы просто вводите название домена, и получаете доступы к MySQL и Git репозиторий. Все, что вы пушите в этот репозиторий, автоматически появляется на сайте. Во время работы с Azure было сложно поверить, что это сделал Microsoft. Кто бы мог подумать год назад, что делая git push со своей убунты я смогу обновлять сайт в Майкрософтовском облаке. В общем, в топ30 мы не попали, потому что на этом хакатоне ценились приложения с хорошими бизнес-перспективами, а мы просто написали забавную игру. Вот видео, которое мы в конечном итоге засабмитили:
По итогам этого хакатона мы не получили никаких призов, но унесли 1000 долларов за то, что представляли BlackBerry.
After Google IO hackathon
Наконец, в эти выходные, спустя всего неделю после AngelHack, мы пошли на хакатон, который нам наконец-то удалось выиграть. Хакатон был привязан к Google IO, и проводился компанией Mashery, с 36-часовой Coding Phase. Уставшие после AngelHack и тяжелой рабочей недели, мы не хотели писать ничего сложного, а просто хотели пообщаться с людьми, и выучить что-то новое, посвятить больше времени изучению того, что предлагают спонсоры на этом соревновании. Среди интересных спонсоров были AllJoyn, с API, которое позволяет легко общаться между телефонами/таблетами/компьютерами на небольшом расстоянии по Bluetooth или через общую точку доступа к WiFi, и Sphero Ball – шарик, которым можно управлять с Андройда, и который можно программировать. Сначала мы очень хотели написать что-то для Sphero, но первую половину дня шариков ни у кого не было – спонсор забыл прийти на событие. Но это было не важно, потому что первая половина дня все равно благополучно ушла на то, чтобы поставить Android SDK и разобраться как им пользоваться. Телефонов на Андройде в нашей команде ни у кого не было (у меня WP7, у Маши BB, у двух других ребят iPhone), так что телефон мы одолжили опять заранее, у Дэвида с работы, который купил его всего пару дней назад и еще не успел заполнить его личной информацией. Во второй половине первого дня шарик-таки нашелся, но после непродолжительной игры с ним мы поняли что он является абсолютно бесполезным девайсом. Точность выполнения команд, равно как и точность всех сенсоров в нем настолько ужасная, что написать хоть что-то рабочее для него не представляется возможным. Поэтому мы решили сконцентрироваться на AllJoyn. Настройка его, и долгие попытки связать два телефона заняли ненулевое время, как моего, так и представлителя AllJoyn на хакатоне, но в конце концов мы смогли заставить один телефон получить данные с акселорометра другого. Выступали мы вчетвером, с Марко с работы и молодым человеком по имени Харшит из Cisco, c которым мы выступали на AT&T хакатоне. Марко в первый день нашел Open Souce версию бомбермена на Java, в которую мы попытались сыграть вчетвером. Это было очень легко раньше, во времена, когда существовали цифровые клавиатуры, и стрелки были далеко от букв. Разместить четыре человека на клавиатуре сегодня, когда люди используют в основном лэптопы, дело не простое, и весь второй день мы неспеша хакали эту игру, чтобы сделать возможным управлять человечками с телефонов. Часа четыре с утра я с парнишкой из AllJoyn пытался разобраться, почему код, почти идентичный семплам, разрывает соединение ровно через 20 секунд после установки. Парнишке пришлось поднять половину команды, разрабатывающей AllJoyn, посреди воскресенья, чтобы разобраться в проблеме. В конце концов оказалось, что я создавал ссылку на объект, отвечающий за соединение, в области видимости метода, этот объект создающего, а не класса, содержащего этот метод, и Java любезно через 20 секунд после завершения метода тот объект собирала мусоросборщиком. Откуда берется волшебное значение в 20 секунд я могу только догадываться. В любом случае, задолго до конца Coding Phase все было готово, и мы нарезали в бомбермена с телефонов. Акселорометр управлял человечком, а нажатие в любом месте экрана ставило бомбу. Управление оказалось на удивление недурным, и презентации еще не начались, когда уже почти каждый участник хакатона зарубил в эту игру с нами. Единственные несколько человек на хакатоне, кто все еще не видел это произведение искусства из Open Source игры, едва измененного семпла AllJoyn и нескольких строк кода, все это связывающих, были судьи. Правило 95% в очередной раз проявило себя, и хороших презентаций было от силы 5. Плюс была одна презентация, почти ничего из себя не представляющая, но сделанная двумя 16-ти летними девочками. Они, собственно, собрали почти все вторичные призы – потому что 16-ти летние девочки, по мнению судей, на хакатоне являются более важным качеством команды, чем техническая сложность исполнения. В любом случае, AllJoyn использовало только четыре команды, и мы среди них волшебным образом заняли только второе место, уступив ребятам, которые сделали приложение, позволяющее быстро собрать контакты всех ребят, присутствющих на событии (вместо постоянного обмена визитками). Но в общем зачете мы разовали всех, и заняли первое место, внеся в свою копилку первую победу на хакатоне. В итоге мы ушли домой с $1300, которые, правда, пришлось делить на четверых. Так что для нас с Машей AngelHack, на котором мы заняли ничего, оказался прибыльнее, чем IOhack, который мы выиграли. А сразу после хакатона мы побежали на концерт Dream Threater, который в этот день выступал буквально в квартале от того места, где проходил хакатон, и в трех кварталах от нашего дома.
В итоге за четыре события мы обогатились на три новых девайса и чуть больше чем $3000, выучили много новых для себя технологий (разработка для WP7 и Android, Azure, Facebook API, AllJoyn API, Sphero), познакомились с огромным количеством очень интересных людей. Единственный большой минус хакатонов – они ужасно изматывают, и забирают единственные два дня на неделе, когда можно отдохнуть.
Вместо P.S. не могу не напомнить, что через две недели будет ICFPC – одно из самых крутых соревнований в году, тоже очень сильно отличающееся от спортивного программирования.
Давече на ВКонтакте Николай Дуров в одном из обсуждений посоветовал книжку Inside C++ Object Model.
Я ее купил, и, читая ее, неоднократно прозрел что я нуб в С++. Каждый день показывал знакомым примеры из книги и спрашивал, как они думают, как поведет себя компилятор, чтобы убедиться, что я такой нуб не один.
Вот сегодня я показал такой пример:
#include <stdio.h>
class Point
{
public:
int a;
Point() : a(5) { };
virtual ~Point() { printf("%d\n", a); }
};
class Point3D : public Point
{
public:
int b;
Point3D() : b(7) { };
virtual ~Point3D() { printf("M\n"); }
};
int main()
{
Point* p = new Point3D[5];
delete [] p;
return 0;
}
И спросил их, что они ожидают увидеть.
Потратьте 5 минут чтобы предложить свой вариант ответа.
На самом деле для меня (и для тех кому я задал вопрос) кажется очевидным, что 5 раз выведется M5 (сначала вызовется виртуальный деструктор Point3D, затем виртуальный деструктор Point).
Согласно книге это не так. delete[] ничего не знает о полиморфизме, и вызовет деструктор Point. Более того, delete[] ничего не знает о том, что реальный размер объектов в массиве больше размера Point, а потому удалив первый элемент он сдвинется только на размер Point, а не на размер Point3D, тем самым вызвав второй декструктор на совершенно неверном участке памяти. Ребята мне не поверили О.О
Мы запустили код, и он вывел M5 пять раз.
Как же так, книга врет? И в тоже время -- я могу поверить, что компилятор догадался взять деструктор из виртуальной таблицы, но откуда он узнал реальный размер объекта?
Не веря в происходящее, я установил Clang, и собрал этот код clang'ом. Код вывел пять пятерок. Кажется, что в этом коде вывести пять пятерок просто невозможно -- это значит, что компилятор не догадался вызывать деструктор из виртуальной таблицы, но догадался сдвигаться на правильный размер?
Я думаю, что все опытные С++ гуру уже поняли что здесь происходит.
Проблема в том, что код запускался на 64-ех битной машине, и компилятор догадался поместить a и b в один восьмибайтный блок, таким образом размер класса Point и Point3D был одинаковый (16 байт -- еще 8 на указатель на виртуальную таблицу).
Теперь давайте поменяем int в определении обоих классов на long long. Каково будет поведение? Опять же, потратьте пять минут, чтобы придумать свой ответ, прежде чем читать дальше.
Чуда не происходит. Коду неоткуда узнать реальный размер объектов. Оба компилятора продолжают вести себя так же как и раньше (g++ вызывает виртуальный деструктор, а clang вызывает деструктор у Point), но только теперь размер Point не равен размеру Point3D. Таким образом clang выводит мусор в виде пятерок, семерок, и численного представления указателя на виртуальную таблицу, а g++ просто сразу падает по Segmentation Fault, не успев вывести ничего. Это странно, потому что виртуальная таблица лежит в самом начале класса, и не понятно, что именно не позволяет вызвать виртуальный декструктор хотя бы для первого элемента.
В любом случае, мораль простая -- массивы не работают с полиморфизмом, и, видимо, приведенный код -- это undefined behavior. Интересно, как этот же код поведет себя в Visual Studio и MigGW?
Вот код для запуска с отладочным выводом:
#include <stdio.h>
class Point
{
public:
long long a;
Point() : a(5) { };
virtual ~Point() { printf("%lld\n", a); }
};
class Point3D : public Point
{
public:
long long b;
Point3D() : b(7) { };
virtual ~Point3D() { printf("M\n"); }
};
int main()
{
printf("%d\n", (int)sizeof(Point));
printf("%d\n", (int)sizeof(Point3D));
// это поможет понять где лежит указатель на виртуальную таблицу
printf("%llu\n", &Point::a);
printf("%llu\n", &Point3D::a);
printf("%llu\n", &Point3D::b);
Point* p = new Point3D[5];
delete [] p;
return 0;
}
Вывод для G++:
16
24
8
8
16
Segmentation fault
Вывод для clang:
16
24
8
8
16
4197968
5
7
4197968
5
Facebook анонсировал очередной HackerCup. Регистрация уже началась, квалификационный раунд начнется 20 января в 4 вечера по времени в Фейсбуке (21-ого в четыре утра по Москве).
TCO2011 закончился. Из семи номинаций в шести победили азиаты, и в одной победил поляк. Это печально :о)
Несколько слов о том, что вообще такое TCO2011 для тех, кто не знает. Это соревнование, проводимое компанией TopCoder в нескольких номинациях, включая проектирование и разработку ПО, дизайн, и, самое важное и интересное, спортивное программирование.
До этого года ТСО четыре года подряд проходил в Вегасе, в этом году его провели в городе Голливуд на берегу Атлантического Океана, в 20 минутых езды на машине от Маями. Организаторы объяснили это тем, что очень сложно говорить серьезно и приглашать компании к сотрудничеству, когда событие проходит в Лас Вегасе.
Несколько фотографий отеля и видов из окна











Наша компания спонсировала соревнование, и я присутствовал на соревновании как спонсор. Я уже публиковал фотографии нашего столика в комнате, где проводилось соревнование, и говорил, что у Интела там целый угол. Вот так этот угол выглядел.

Люди иногда подходили и играли в Wii, но в целом казалось, что усилия Интела не оправдали себя.
Фейсбук на этом соревновании не раздавал никаких дорогих подарков, только кубики рубика, Интел разыграл нетбук от Леново, мы разыграли MacBook Air. Кажется, что большие компании очень жадные :о Разыгрвали мы его в турнире по покеру, который проходил на пуфиках рядом с ballroom-ом


С финалом в последний день прошла накладка. Утром Петя должен был общаться с детьми, которых привели на выступление Dean Kamen, а после обеда Миша Кевер писал финал ТСО. После Финала у нас с Эриком уже был самолет. Пришлось проводить финал по покеру прямо во время ланча :о)

Выиграла его девушка по имени Анна из Польши, ее хендл на топкодере 7ania7.

Теперь немного о режиме дня и самих соревнованиях. Завтрак каждый день начинался в 7:30, и длился около часа. Можно было вставать немного позже, но в принципе обычно получалось подобраться на завтрак к началу, и некоторые ребята уже там сидели.

Другие подтягивались попозже. После завтрака обычно все шли в ballroom, потому что всегда начиналось какое-то соревнование или мероприятие. Во время всех соревнований на экране было видно, что делает каждый из участников.
А на стене висел большой монитор с текущими результатами. На нем же во время челенжа видно кто кого и насколько успешно почеленжил. Марафон матч наблюдать так не очень интересно, потому что там мало экшена, а вот Алгоритмы -- это весьма захватывающее зрелище. Интересно наблюдать за тем, что пишут участники, и сравнивать со своими идеями. Видеть ошибки и думать, заметят ли их участники.

После system test результаты начинали показывать с последнего места, чтобы держать всех заинтригованными до последнего. Хотя, кажется, что с первого места никто ниразу на системниках не упал.
Мы с Эриком уехали с соревнования за несколько минут до начала церемонии награждения, поэтому не смогли понаблюдать за финальными системными тестами. В самолете, правда, был интернет, и результаты мы узнали достаточно быстро.
Интересно, что почти все русские ребята приехали с iPad'ами. И это не потому, что все так любят продукцию Apple, а потому, что почти все прошли на Russian Code Cup, где выдавали iPad всем участникам. Mail.ru реально расщедрился на своем соревновании. TopCoder Open выдал только футболочки и сувениры :о)
В этом году не осталось больше ни одного онсайта -- TopCoder Open было последним, замыкая цепочку соревнования от Facebook, Яндекса, Google, mail.ru и ABBYY. Хотелось бы верить, что все компании, которые провели в этом году впервые свое онсайт соревнование, проведут его и в следующем, и уже в январе мы будем проходить отборочные на HackerCup :о)
В прошлом посте я упоминал, что один из победителей в номинации "лучшее развлечение для участников" выиграла девочка, предложившая участникам выполнить 10 заданий вида "сфоткайте себя и <описание жертвы> в <описание обстановки>". Не смотря на то, что это действительно клевое развлечение, очень мало людей действительно им занялись.







